
基于 Trace 的 metrics
WARNING: 此页面描述了旧版(v1)metrics 系统。对于所有新的用例,请参阅Trace 汇总文档,这是此系统的后继者。此页面仅作为历史参考保留。
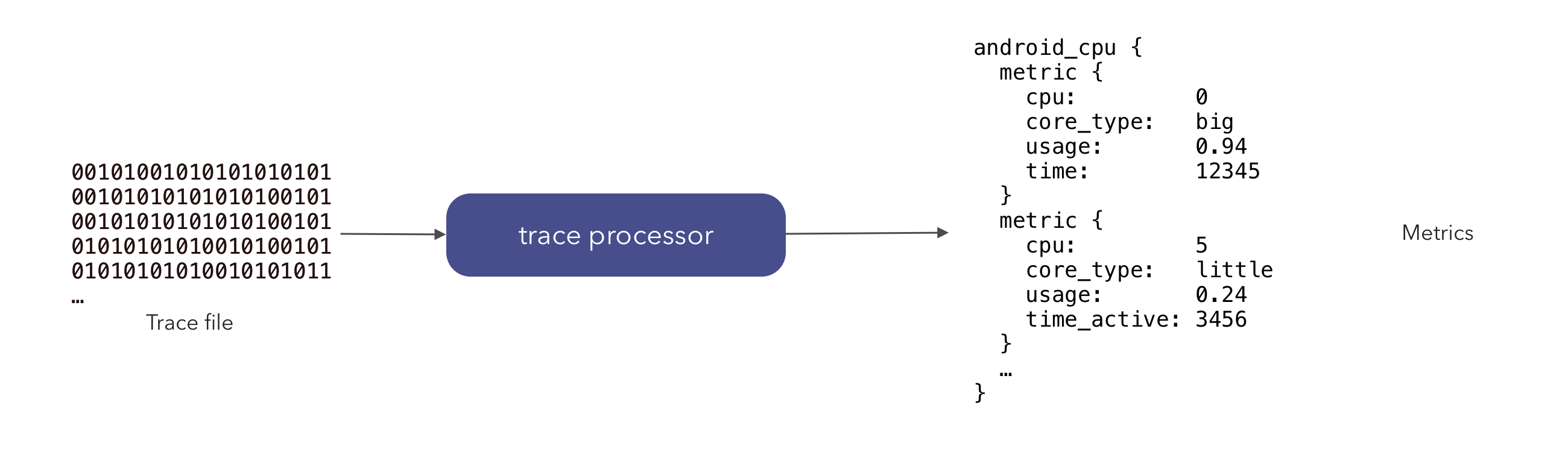
metrics 子系统是trace processor的一部分,它使用 trace 计算可重现的 metrics。它可以在广泛的情况下使用;示例包括基准测试、实验室测试和大型 trace 语料库。
简介
动机
性能 metrics 对于监控系统的健康状况很有用,并确保系统在添加新功能时不会随时间回归。
但是,直接从系统检索的 metrics 有一个缺点:如果出现回归,很难确定问题的根本原因。通常,问题可能无法重现,或者可能依赖于特定的设置。
基于 Trace 的 metrics 是此问题的一种可能的解决方案。不是直接在系统上收集 metrics,而是收集 trace 并从 trace 计算 metrics。如果发现 metrics 回归,开发人员可以直接查看 trace 以了解为什么发生回归,而不必重现问题。
metrics 子系统
metrics 子系统是trace processor的一部分,它对 trace 执行 SQL 查询并产生总结某些性能属性(例如,CPU、内存、启动延迟等)的 metrics。
例如,在 trace 上生成 Android CPU metrics 非常简单:
> ./trace_processor --run-metrics android_cpu <trace>
android_cpu {
process_info {
name: "/system/bin/init"
threads {
name: "init"
core {
id: 1
metrics {
mcycles: 1
runtime_ns: 570365
min_freq_khz: 1900800
max_freq_khz: 1900800
avg_freq_khz: 1902017
}
}
...
}
...
}
...
}metrics 开发指南
由于 metrics 编写需要大量迭代才能正确,因此有几个技巧可以使体验更顺畅。
热重新加载 metrics
为了在开发 metrics 时获得最快的迭代时间,可以热重新加载 SQL 的任何更改;这将跳过重新编译(对于内置 metrics)和 trace 加载(对于内置和自定义 metrics)。
为此,trace processor 在_交互模式_中启动,同时指定关于应该运行哪些 metrics 和任何扩展路径的命令行标志。然后,在 REPL shell 中,使用命令 .load-metrics-sql(导致磁盘上的任何 SQL 被重新读取)和 .run-metrics(运行 metrics 并打印结果)。
例如,假设我们要迭代 android_startup metrics。我们可以从 Perfetto checkout 运行以下命令:
> ./tools/trace_processor --interactive \
--run-metrics android_startup \
--metric-extension src/trace_processor/metrics@/ \
--dev \
<trace>
android_startup {
<startup metrics 的内容>
}
# 现在对与启动 metrics 相关的 SQL 文件进行你想要的任何更改。
# 即使在 src/trace_processor/metric 中添加新文件也可以工作。
# 然后,我们可以使用 `.load-metrics-sql` 重新加载更改。
> .load-metrics-sql
# 我们可以使用 `.run-metrics` 重新运行更改后的 metrics
> .run-metrics
android_startup {
<更改后的启动 metrics 的内容>
}NOTE: 下面将看到为什么此命令需要 --dev。
这也适用于命令行上指定的自定义 metrics:
> ./tools/trace_processor -i --run-metrics /tmp/my_custom_metric.sql <trace>
my_custom_metric {
<my_custom_metric 的内容>
}
# 像以前一样更改 SQL 文件。
> .load-metrics-sql
> .run-metrics
my_custom_metric {
<更改后的 my_custom_metric 的内容>
}WARNING: 目前无法以相同的方式重新加载 protos。如果更改了 protos,则需要重新编译(对于内置 metrics)并重新调用 trace processor 以获取更改。
WARNING: 从 --metric-extension 文件夹中删除的文件_不会_被删除,并且仍然可用,例如,对于 RUN_METRIC 调用。
在不重新编译的情况下修改内置 metrics SQL
可以在运行时覆盖内置 metrics 的 SQL,而无需重新编译 trace processor。为此,需要使用内置 metrics 所在的磁盘路径和虚拟路径的特殊字符串 / 来指定标志 --metric-extension。
例如,从 Perfetto checkout 内部:
> ./tools/trace_processor \
--run-metrics android_cpu \
--metric-extension src/trace_processor/metrics@/
--dev
<trace>这将使用 repo 中的实时 SQL 运行 CPU metrics_ 而不是_内置到二进制文件中的 SQL 定义。
NOTE: protos_ 不会_以相同方式被覆盖 - 如果更改了任何 proto 消息,则需要重新编译 trace processor 以使更改可用。
NOTE: 使用此功能需要 --dev 标志。此标志确保此功能不会在生产中意外使用,因为它仅用于本地开发。
WARNING: protos_ 不会_以相同方式被覆盖 - 如果更改了任何 proto 消息,则需要重新编译 trace processor 以使更改可用。
metrics 辅助函数
RUN_METRIC
RUN_METRIC 允许你运行另一个 metrics 文件。这允许你使用在该文件中定义的视图或表,而无需重复。
从概念上讲,RUN_METRIC 为 SQL 查询添加了_组合性_以将大型 SQL metrics 分解为更小的、可重用的文件。这类似于函数如何在传统编程语言中分解大块。
RUN_METRIC 的简单用法如下:
在文件 android/foo.sql 中:
CREATE VIEW view_defined_in_foo AS
SELECT *
FROM slice
LIMIT 1;在文件 android/bar.sql 中:
SELECT RUN_METRIC('android/foo.sql');
CREATE VIEW view_depending_on_view_from_foo AS
SELECT *
FROM view_defined_in_foo
LIMIT 1;RUN_METRIC 还支持运行_模板化_metrics 文件。以下是一个示例:
在文件 android/slice_template.sql 中:
CREATE VIEW {{view_name}} AS
SELECT *
FROM slice
WHERE slice.name = '{{slice_name}}';在文件 android/metric.sql 中:
SELECT RUN_METRIC(
'android/slice_template.sql',
'view_name', 'choreographer_slices',
'slice_name', 'Chroeographer#doFrame'
);
CREATE VIEW long_choreographer_slices AS
SELECT *
FROM choreographer_slices
WHERE dur > 1e6;当运行 slice_template.sql 时,trace processor 将在执行文件之前将传递给 RUN_METRIC 的参数替换到模板化文件中。
换句话说,对于上述示例,SQLite 实际上看到和执行的是:
CREATE VIEW choreographer_slices AS
SELECT *
FROM slice
WHERE slice.name = 'Chroeographer#doFrame';
CREATE VIEW long_choreographer_slices AS
SELECT *
FROM choreographer_slices
WHERE dur > 1e6;模板化 metrics 文件的语法本质上是 Jinja 的 语法的高度简化版本。
演练:原型化 metrics
TIP: 要查看如何向 trace processor 添加新 metrics,请参阅此处的检查清单
本演练将概述如何在不编译 trace processor 的情况下本地原型化 metrics。此 metrics 将计算 trace 中每个进程的 CPU 时间,并列出前 5 个进程(按 CPU 时间)的名称以及进程创建的线程数。
NOTE: 请参阅此 GitHub gist 以查看演练结束时代码的外观。下面的先决条件和步骤 4 提供了有关如何获取 trace processor 和运行 metrics 代码的说明。
先决条件
作为设置步骤,创建一个文件夹作为临时工作区;此文件夹将在步骤 4 中使用 env 变量 $WORKSPACE 引用。
另一个要求是 trace processor。这可以从此处下载,或者可以使用此处的说明从源代码构建。无论选择哪种方法,$TRACE_PROCESSOR env 变量都将在步骤 4 中用于引用二进制文件的位置。
步骤 1
由于 metrics 平台中的所有 metrics 都是使用 protos 定义的,因此 metrics 需要结构化为 proto。对于此 metrics,需要对进程名称及其 CPU 时间和线程数有一些概念。
首先,在工作区中名为 top_five_processes.proto 的文件中,创建一个名为 ProcessInfo 的基本 proto 消息,包含这三个字段:
message ProcessInfo {
optional string process_name = 1;
optional uint64 cpu_time_ms = 2;
optional uint32 num_threads = 3;
}接下来,创建一个包装消息,该消息将保存包含前 5 个进程的重复字段。
message TopProcesses {
repeated ProcessInfo process_info = 1;
}最后,为所有 metrics 的根 proto 定义一个扩展([TraceMetrics](https://github.com/google/perfetto/blob/main/protos/perfetto/metrics/metrics.proto#L39) proto)。
extend TraceMetrics {
optional TopProcesses top_five_processes = 450;
}添加此扩展字段允许 trace processor 将新定义的 metrics 链接到 TraceMetrics proto。
注意:
- 字段 id 450-500 保留用于本地开发,因此可以将其中任何一个用作扩展字段的字段 id。
- 此处字段名称的选择很重要,因为 SQL 文件和 SQL 中生成的最终表将基于此名称。
将所有内容放在一起,以及一些样板前导文件,给出:
syntax = "proto2";
package perfetto.protos;
import "protos/perfetto/metrics/metrics.proto";
message ProcessInfo {
optional string process_name = 1;
optional int64 cpu_time_ms = 2;
optional uint32 num_threads = 3;
}
message TopProcesses {
repeated ProcessInfo process_info = 1;
}
extend TraceMetrics {
optional TopProcesses top_five_processes = 450;
}步骤 2
接下来,编写 SQL 以生成按它们运行的 CPU 时间总和以及与进程关联的线程数排序的前 5 个进程的表。
以下 SQL 应该添加到工作区中名为 top_five_processes.sql 的文件中:
CREATE VIEW top_five_processes_by_cpu AS
SELECT
process.name as process_name,
CAST(SUM(sched.dur) / 1e6 as INT64) as cpu_time_ms,
COUNT(DISTINCT utid) as num_threads
FROM sched
INNER JOIN thread USING(utid)
INNER JOIN process USING(upid)
GROUP BY process.name
ORDER BY cpu_time_ms DESC
LIMIT 5;让我们分解这个查询:
- 使用的第一个表是
sched表。这包含 trace 中可用的所有调度数据。每个调度 "slice" 都与一个线程关联,该线程在 Perfetto trace 中使用其utid唯一标识。从 sched 表中需要的两条信息是dur- 持续时间的缩写,这是 slice 持续的时间量 - 和utid,它将用于与线程表连接。 - 下一个表是线程表。这给我们提供了大量不太有趣的信息(包括其线程名称),但它确实给了我们
upid。与utid类似,upid是 Perfetto trace 中进程的唯一标识符。在这种情况下,upid将引用承载由utid给定线程的进程。 - 最后一个表是进程表。这给出了与原始 sched slice 关联的进程的名称。
- 有了每个 sched slice 的进程、线程和持续时间,收集单个进程的所有 slice 并对它们的持续时间求和以获得 CPU 时间(除以 1e6,因为 sched 的持续时间以纳秒为单位)和不同线程的数量。
- 最后,我们按 cpu 时间排序并限制为前 5 个结果。
步骤 3
既然 metrics 的结果已经表示为 SQL 表,则需要将其转换为 proto。metrics 平台对使用 SQL 函数发出 proto 具有内置支持;这是在此步骤中广泛使用的内容。
让我们看看它如何适用于我们上面的表。
CREATE VIEW top_five_processes_output AS
SELECT TopProcesses(
'process_info', (
SELECT RepeatedField(
ProcessInfo(
'process_name', process_name,
'cpu_time_ms', cpu_time_ms,
'num_threads', num_threads
)
)
FROM top_five_processes_by_cpu
)
);再次分解:
- 从最内层的 SELECT 语句开始,看起来像是对 ProcessInfo 函数的函数调用;实际上这并非巧合。对于 metrics 平台知道的每个 proto,都会生成一个与 proto 同名的 SQL 函数。此函数接受键值对,键为要填充的 proto 字段的名称,值为要存储在字段中的数据。输出是通过写入函数中描述的字段创建的 proto。(*)
在这种情况下,对于 top_five_processes_by_cpu 表中的每一行调用此函数一次。输出将是完全填充的 ProcessInfo proto。
对 RepeatedField 函数的调用是最有趣的部分,也是最重要的部分。在技术术语中,RepeatedField 是一个聚合函数。实际上,这意味着它接受一个完整的值表并生成一个包含传递给它的所有值的单个数组。
因此,整个 SELECT 语句的输出是一个包含 5 个 ProcessInfo protos 的数组。
- 接下来是创建
TopProcessesproto。现在,语法应该已经感觉有些熟悉;调用 proto 构建器函数来用来自内部函数的 proto 数组填充process_info字段。
此 SELECT 的输出是单个 TopProcesses proto,包含 ProcessInfos 作为重复字段。
- 最后,创建视图。此视图被特殊命名,以允许 metrics 平台查询它以获取每个 metrics 的根 proto(在这种情况下为
TopProcesses)。请参阅下面有关此视图名称背后的模式的说明。
(*) 这并非严格正确。为了类型检查 protos,返回了一些关于 proto 类型的元数据,但这对于 metrics 作者来说并不重要。
NOTE: 重要的是视图命名为 {TraceMetrics 扩展字段的名称}_output。这是 metrics 平台用于所有 metrics 的使用的和期望的模式。
最终文件应该如下所示:
CREATE VIEW top_five_processes_by_cpu AS
SELECT
process.name as process_name,
CAST(SUM(sched.dur) / 1e6 as INT64) as cpu_time_ms,
COUNT(DISTINCT utid) as num_threads
FROM sched
INNER JOIN thread USING(utid)
INNER JOIN process USING(upid)
GROUP BY process.name
ORDER BY cpu_time_ms DESC
LIMIT 5;
CREATE VIEW top_five_processes_output AS
SELECT TopProcesses(
'process_info', (
SELECT RepeatedField(
ProcessInfo(
'process_name', process_name,
'cpu_time_ms', cpu_time_ms,
'num_threads', num_threads
)
)
FROM top_five_processes_by_cpu
)
);NOTE: SQL 文件的名称应该与 TraceMetrics 扩展字段的名称相同。这是为了允许 metrics 平台将 proto 扩展字段与需要运行的 SQL 关联以生成它。
步骤 4
TRACE_PROCESSOR --run-metrics $WORKSPACE/top_five_processes.sql $TRACE 2> /dev/null(有关要测试的示例 trace,请参阅下面的说明部分。)
通过传递要计算的 metrics 的 SQL 文件,trace processor 使用此文件的名称来查找 proto 并找出 proto 的输出表的名称和 TraceMetrics 的扩展字段的名称;这就是为什么仔细选择这些其他对象的名称很重要的原因。
说明:
- 如果某些东西没有按预期工作,请检查工作区看起来与此 GitHub gist的内容相同。
- 此 metrics 的一个很好的示例 trace 是 Perfetto UI 使用的 Android 示例 trace,可在此处找到。
- stderr 被重定向以删除 trace processor 生成的解析 trace 产生的任何噪音。
如果一切顺利,应该可以看到以下输出(具体来说,这是上面链接的 Android 示例 trace 的输出):
[perfetto.protos.top_five_processes] {
process_info {
process_name: "com.google.android.GoogleCamera"
cpu_time_ms: 15154
num_threads: 125
}
process_info {
process_name: "sugov:4"
cpu_time_ms: 6846
num_threads: 1
}
process_info {
process_name: "system_server"
cpu_time_ms: 6809
num_threads: 66
}
process_info {
process_name: "cds_ol_rx_threa"
cpu_time_ms: 6684
num_threads: 1
}
process_info {
process_name: "com.android.chrome"
cpu_time_ms: 5125
num_threads: 49
}
}后续步骤
- 常见任务页面列出了如何向 trace processor 添加新 metrics 的步骤。
附录:上游化的理由
NOTE: Google 员工:在 Google3 中使用 metrics 的内部使用(即机密 metrics),请参阅此内部页面。
强烈鼓励作者将从 Perfetto trace 派生的所有 metrics 添加到 Perfetto repo,除非有明确的用例(例如,机密性)说明这些 metrics 不应该公开可用。
作为向上游提交 metrics 的回报,作者将获得在本地运行 metrics 的一流支持,并且可以确信他们的 metrics 将随着 trace processor 的开发而保持稳定。
不仅在开发时从在单个 trace 上本地运行扩展到在大量 trace 上运行,反之也非常有用。当在实验室基准测试的 metrics 中观察到异常时,可以下载代表性 trace,并且可以在 trace processor 中本地运行相同的 metrics。
由于相同的代码在本地和远程运行,开发人员可以自信地重现问题,并使用 trace processor 和/或 Perfetto UI 来识别问题。