
heapprofd: Android Heap Profiler
状态: 已完成 · fmayer, primiano · 2018-06-15
更新: 2020-04-20
目标
提供低开销的原生 heap profiling 机制,具有 C++ 和 Java callstack 归因,可供 Android 系统上的所有进程使用。这包括 Java 和原生服务。该机制能够将 heap dumps 导出到 traces,以便能够将 heap 信息与系统上的其他活动相关联。此功能在 Android 10 版本中添加。
概述
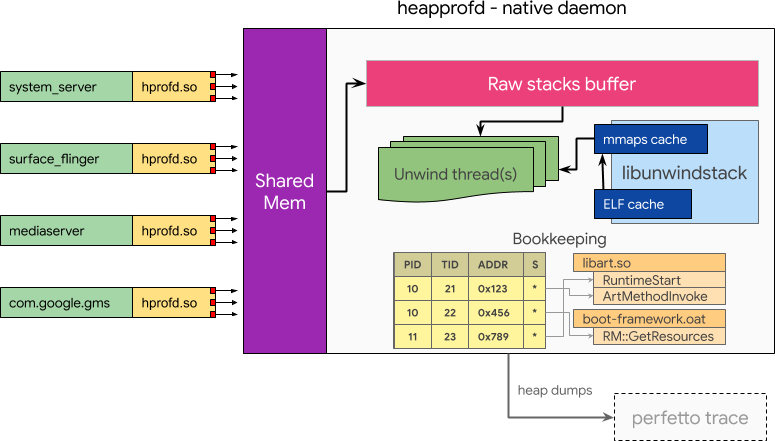
实现一个进程外 heap profiler。在 malloc 中进行最少的内联处理,然后委托给中央组件进行进一步处理。这引入了一个新的守护进程 heapprofd 。
当启用 tracing 时,无论是通过系统属性还是传递给现有进程的信号,一定百分比的 malloc 调用会将当前调用堆栈复制到由 heapprofd 接收的共享内存缓冲区中。heapprofd 使用 libunwindstack 异步进行堆栈展开和符号化。此信息用于构建账本表以跟踪活动分配,并最终转储到 Perfetto trace 中。
本文档中引用的所有数据都在 Android P 上的 Pixel 2 上收集。
要求
这些是 heap profiler 必须满足的属性:
无需设置: 可以使用单个命令获取 heap profile。
分析运行中的应用程序: 系统可用于启用已运行应用程序的分析,以获取自启用 profiling以来的内存使用情况信息,而无需重启。这对于跟踪内存泄漏很有用。
归因于 Java 方法: 系统可用于跟踪 Java 应用程序的原生内存使用情况。Java heap 上的分配超出了本文档的范围。
禁用时零开销: 当系统未启用时,必须不会产生性能开销。
分析整个系统: 系统必须能够处理分析所有正在运行的进程的负载。采样率经过调整以限制数据量。
可忽略的进程内内存开销: 系统不得在进程中保存账本数据,以免膨胀更高级别的 metrics(如 PSS)。
有界性能影响: 对于所有用例,设备仍然必须可用。
详细设计
启用 profiling
用例 1:从正在运行的进程 profile 未来的分配
实时信号之一(BIONIC_SIGNAL_PROFILER)在 libc 中保留作为触发机制。在此场景中:
- heapprofd 向目标进程发送 RT 信号
- 收到信号后,bionic 通过安装临时 malloc hook 作出反应,后者又生成一个线程以在进程上下文中动态加载 libheapprofd.so。这意味着 heapprofd 将不适用于静态链接的二进制文件,因为它们缺乏
dlopen的能力。我们不能直接从信号处理程序生成线程,因为pthread_create不是异步安全的。 - 调用 libheapprofd.so 中的初始值设定项来处理其余部分(请参阅下面的 客户端操作和进程内挂钩)
用例 2:从启动分析单个进程
- heapprofd 设置一个格式为 libc.debug.heapprofd.argv0 的属性(argv0 是
/proc/self/cmdline中的第一个参数,直到第一个 ":") - 原生进程:bionic 初始化时检查属性是否存在,如果存在且匹配进程名称,则加载 libheapprofd.so。
- 托管的 java 进程:zygote 在
PreApplicationInit中调用mallopt(M_SET_ZYGOTE_CHILD, ...)。在此过程中,Bionic 检查属性是否存在,如果存在且匹配进程名称,则加载 libheapprofd.so 并继续如上所述。
用例 3:分析整个系统
可以设置系统属性 libc.heapprofd.enable 以在启动时启用 heap profiling。设置此属性后,每个进程在启动时都会加载 libheapprofd.so 库。其余部分与上述情况相同。
禁用分析
通过从 heapprofd 端关闭 sockets 来简单地禁用分析。在 send() 失败时,客户端将卸载挂钩(请参阅附录:线程安全的挂钩设置/拆除)
客户端操作和进程内挂钩
在 libheapprofd.so 初始化时:
- 客户端通过连接的 UNIX socket 与 heapprofd 守护进程建立连接。
- 连接后,守护进程将向客户端发送一个数据包,指定分析配置(采样率;采样所有线程/仅特定线程;采样启发式调整)。它还将发送用于发送采样的 SharedMemoryBuffer 的 FD(请参阅 wire protocol)。
- 安装 malloc 挂钩。
在每次 *alloc()/posix_memalign() 调用时,客户端库将执行一些最少的记账。如果达到采样率,它将把原始堆栈连同指定寄存器状态、tid、操作的全局序列号和分配大小的标头一起复制到共享内存缓冲区中。然后它将在控制 socket 上发送以唤醒服务。
在每次 free() 调用时,客户端将释放的地址追加到全局(进程范围)仅追加缓冲区(缓冲区是为了避免对每个 free 进行 send() 开销)。当固定大小的缓冲区已满或在预设数量的操作后,此 free()s 缓冲区将发送到 heapprofd 守护进程。这还包括操作的全局序列号。
如果由于 heapprofd 已关闭 socket(无论是自愿(优雅禁用)还是非自愿(已崩溃))导致 send() 失败,客户端将拆除挂钩并禁用任何分析操作。
服务操作
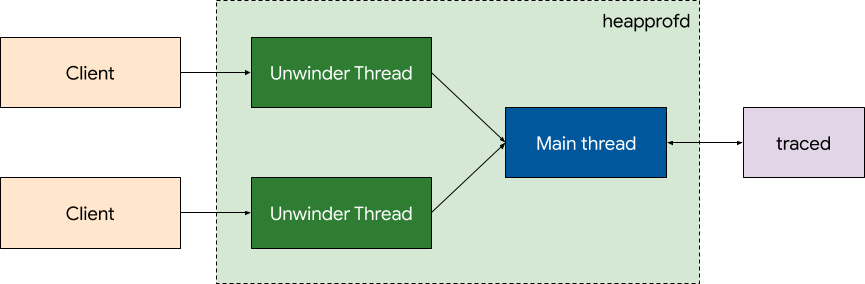
展开器线程读取客户端的共享内存缓冲区并处理接收到的采样。展开的结果随后通过 PostTask 排队,供主线程进行记账。在线程之间使用基于队列的模型是因为它使同步更容易。主线程根本不需要同步,因为记账数据只能由它访问。
如果采样是 malloc,则堆栈被展开,结果数据在主线程中处理。主线程忽略序列号低于此地址已处理的序列号的 mallocs。如果采样是 free,则将其添加到缓冲区。一旦序列号低于 free 的所有 mallocs 都已处理,就处理它。
展开
使用 libunwindstack 进行展开。实现了一个新的 Memory 类,将复制的堆栈覆盖在进程内存上(使用 FDMemory 访问)。FDMemory 使用目标应用程序发送的 /proc/self/mem 文件描述符上的读取。
class StackMemory : public unwindstack::MemoryRemote {
public:
...
size_t Read(uint64_t addr, void* dst, size_t size) override {
if (addr >= sp_ && addr + size <= stack_end_ && addr + size > sp_) {
size_t offset = static_cast<size_t>(addr - sp_);
memcpy(dst, stack_ + offset, size);
return size;
}
return mem_->Read(addr, dst, size);
}
private:
uint64_t sp_;
uint8_t* stack_;
size_t size;
};这允许展开对于原生代码和 ART 的所有三种执行模式都可以工作。原生库被映射到进程内存中,ART 写入的临时调试信息也可以通过进程内存访问。有可能 ART 会在展开完成之前垃圾收集信息,在这种情况下我们将错过堆栈帧。由于这无论如何是一种采样方法,这种准确性损失是可以接受的。
远程展开还使我们能够在 libunwindstack 中使用 全局缓存(Elf::SetCachingEnabled(true))。这防止了由不同进程使用的调试信息被加载和解压缩多次。
我们添加一个 FDMaps 对象来解析从目标进程发送的 /proc/self/maps 映射。我们为每个正在分析的进程保持 FDMaps 对象缓存。这既节省了文本解析 /proc/[pid]/maps 的开销,也保持了展开所需的各种对象(例如,解压缩的 minidebuginfo)。如果展开因 ERROR_INVALID_MAP 失败,我们重新解析 maps 对象。我们将对 libunwindstack 进行更改,以创建 [LocalUpdatableMaps](https://cs.android.com/android/platform/superproject/main/+/main:system/unwinding/libunwindstack/Maps.cpp?q=symbol:LocalUpdatableMaps)的更通用版本,该版本也适用于远程进程。
远程展开的优势
防崩溃: 记账逻辑或 libunwindstack 中的崩溃错误不会导致用户可见的崩溃,而只会导致缺少 profile 数据。这将导致与 heapprofd 的连接中断,并在客户端侧优雅地停止 profiling。
性能: 复制堆栈比展开具有更一致和更高的性能,展开可能需要几毫秒。请参见上图。
不会膨胀更高级别的 metrics: 诸如 PSS 之类的更高级别 metrics 不会因记账成本而膨胀。
压缩: 如果在多个进程之间共享,已展开帧的记账可以更有效率。例如,常见的帧序列(在 libc、ART 等中)可以重复数据删除。
远程展开的缺点
复杂性: 系统比同步展开和符号化具有更高的复杂性。
记账
数据以树的形式存储,其中每个元素都有指向其父元素的反向指针。这重复数据删除了重复的堆栈帧。对方法名和库名应用了字符串驻留。
细节将根据实现期间收集的数据进行调整。
Wire 协议
在 heapprofd 的早期版本中,我们使用 SOCK_STREAM socket 将调用堆栈发送到服务。我们现在使用基于共享内存的 wire protocol,详细说明单独描述。
失败模式
heapprofd 展开无法跟上: 共享内存缓冲区将拒绝新采样。如果设置了 block_client,客户端将重试直到共享内存缓冲区中有空间。
heapprofd 崩溃: 在控制 socket 上写入将失败,客户端将被拆除。
客户端中写入失败: 如果写入失败并出现 EINTR 以外的任何错误代码,则连接关闭,分析被拆除。
Fork 处理
进程 fork 后,我们需要清理由父进程初始化的状态并卸载 malloc 挂钩。我们目前不打算支持跟踪 fork,请参阅 [考虑的替代方案](#alternatives-considered)以获取可能的实现。
性能考虑
远程展开
注意:这些数据是在 heapprofd 使用 socket 从客户端到服务进行通信时收集的。我们现在使用共享内存缓冲区,因此我们应该具有更低的开销。
使用远程展开是为了减少对正在分析的应用程序的性能影响。发送堆栈后,应用程序可以恢复其操作,而远程守护进程展开堆栈并进行展开。由于发送堆栈平均来说比展开堆栈是更快的操作,这导致了性能提升。
|
|
|
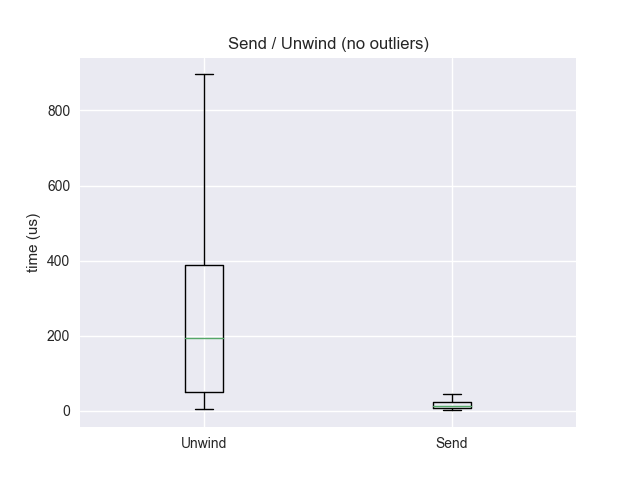
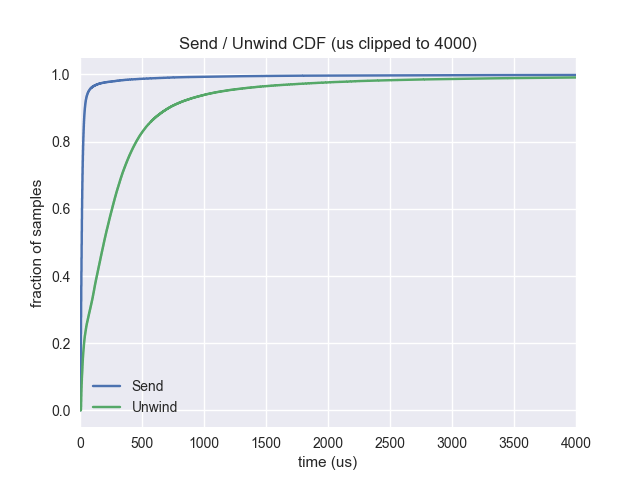
平均展开: 413us 平均发送: 50us 中位展开: 193us 中位发送: 14us 90 百分位展开: 715us 90 百分位发送: 40us
采样
在每个 malloc 调用时展开堆栈具有很高的成本,并不总是值得支付。因此,客户端使用泊松采样对 malloc 调用进行采样,概率与其分配大小成比例(即,较大的分配比较小的分配更可能被考虑)。自上次考虑的 malloc 以来分配的所有内存都归因于此分配。
采样率作为初始握手的一部分可配置。采样率 == 1 将退化为完全准确的高开销模式。
有关更多详细信息,请参阅 Memory Profile 的采样。
先前的艺术:crbug.com/812262, crbug.com/803276。
实现计划
实现原型 [已完成]
实现上述系统的原型,该系统在 walleye 上以 root 身份运行时配合 SELinux setenforce 0 工作。
实现基准 [已完成]
实现一个从基本事实数据执行 malloc / free 调用的程序。使用 heapprofd 分析此程序,然后将结果与基本事实数据进行比较。使用它来迭代采样启发式方法。
生产化 [已完成]
进行在 setenforce 1 和非 root 身份下运行 heapprofd 所需的安全更改。
测试计划
- 对共享内存缓冲区进行模糊测试。[已完成]
- 组件的单元测试。[已完成]
- CTS。[已完成]
背景
ART 执行模式
ART(Android Runtime,Android Java 运行时)有三种不同的执行模式。
解释: Java 字节码在执行期间被解释。ART 中的检测允许获取正在执行的代码的 dexpc(~dex 文件中的偏移量)。
JIT 编译: Java 字节码在运行时编译为原生代码。代码和 ELF 信息都仅存在于进程内存中。调试信息存储在全局变量中,目前仅当应用程序可调试或设置了全局系统属性(dalvik.vm.minidebuginfo)时才会存储。这是因为当前实现会产生过高的内存开销,无法默认启用。
AOT(ahead of time)编译: Java 代码在运行时之前编译为原生代码。这会生成一个 .oat 文件,本质上是一个 .so 文件。代码和 ELF 信息都存储在磁盘上。在执行期间,像共享原生库一样,它被内存映射到进程内存中。
堆栈展开
堆栈展开是从堆栈的原始字节确定返回地址链的过程。这些是我们想要将分配的内存归因于的地址。
堆栈展开的最有效方法是使用帧指针。这在 Android 上是不可靠的,因为我们不控制供应商库或 OEM 版本的构建参数,并且由于 ARM32 上的问题。因此,我们的堆栈展开依赖于 libunwindstack,它使用库 ELF 文件中的 DWARF 信息来确定返回地址。这可能显著更慢,展开堆栈需要 100μs 到 ~100 ms 之间的时间(来自 simpleperf 的数据)。
libunwindstack 是 Android 对 libunwind 的替代品。它具有现代 C++ 面向对象 API 表面,并支持 Android 特定功能,允许它使用 ART 根据执行模式发出的信息来展开混合的原生和 Java 应用程序。它还支持原生代码和 ART 的所有三种执行模式的符号化。
符号化
符号化是从代码地址确定函数名和行号的过程。对于 Google 构建的版本,我们可以从 go/ab 或 https://ci.android.com 获取符号化二进制文件(即具有可用于符号化的 ELF 部分的二进制文件)(例如 https://ci.android.com/builds/submitted/6410994/aosp_cf_x86_phone-userdebug/latest/aosp_cf_x86_phone-symbols-6410994.zip)。
对于其他版本,符号化需要二进制文件中包含的调试信息。此信息通常被压缩。JIT 编译代码的符号化需要进程内存中包含的信息。
Perfetto
Perfetto 是一个开源、高效且可扩展的平台级 tracing 系统,允许从内核、应用程序和服务收集性能数据。它的目标是成为 Android 和 Chrome 的下一代性能 tracing 机制。
相关工作
simpleperf
即使 simpleperf 是 CPU 而不是 memory profiler,它在本质上与本文档中提出的工作相似,因为它支持离线展开。要求内核定期提供堆栈跟踪的副本,这些副本被转储到磁盘上。转储的信息随后在分析完成后用于展开堆栈。
malloc-debug
malloc-debug 检测 bionic 的分配函数以检测常见的内存问题,如缓冲区溢出、双重释放等。这与本文档中描述的项目相似,因为它使用相同的机制来检测 libc 分配函数。与 heapprofd 不同,它不向用户提供 heap dumps。
功能矩阵
| use after free 检测 | Java 对象图归因 | 原生内存归因 | Android | 进程外 | |
|---|---|---|---|---|---|
| heapprofd | 否 | 否 | 是 | 是 | 是 |
| malloc-debug | 是 | 否 | 是 | 是 | 否 |
考虑的替代方案
Copy-on-write 堆栈
堆栈的下层帧在客户端发送和服务器展开堆栈信息之间不太可能更改。我们希望通过 vmsplice(2) 将它们拼接到一个管道中来利用这一事实来标记堆栈页面为写时复制。不幸的是,vmsplice 系统调用不会将页面标记为写时复制,而是在概念上映射到管道缓冲区,这会导致守护进程看到 vmsplice 之后发生的堆栈更改,从而破坏展开器。
跨 fork(2)进行 profile
如果我们想要为新 fork 的进程启用 profiling,我们需要建立与 heapprofd 的新连接并创建新的连接池。这是为了防止来自父进程和子进程的消息交错。
对于非 zygote 进程,我们可以使用 pthread_atfork(3) 来建立新连接。
对于 zygote 进程,FileDescriptorInfo::ReopenOrDetach 在 fork(2) 之后被调用——因此在 pthread_atfork 处理程序之后——分离所有 socket,即将它们替换为指向 /dev/null 的文件描述符。如果 socket 不包含在 kPathWhiteList 中,zygote 会崩溃。因此,仅使用 pthread_atfork 处理程序是不可行的,因为在其中建立的连接将在 zygote 子进程中立即断开。
Fork 后,zygote 调用 PreApplicationInit,目前 malloc_debug 使用它来通过设置 gMallocLeakZygoteChild 来检测它是处于根 zygote 还是子进程中。它还调用 Java 回调,但目前似乎不存在动态注册原生回调的方法。
朴素的延迟初始化(即在 atfork 处理程序中关闭 socket,然后在第一次调用 malloc 时重新连接)是有问题的,因为 zygote 中 fork 和 ReopenOrDetach 之间的代码可能会调用 malloc,从而导致建立连接,然后再次被 ReopenOrDetach 关闭。
为了解决这个问题,我们可以采取类似于 gMallocLeakZygoteChild 的方法。Fork 之前,zygote 将被修改以将 gheapprofdInZygoteFork 设置为 true,在 fork 处理完成后,它将被设置为 false。这样我们可以确保延迟初始化直到 fork 完全完成。pthread_atfork 用于在 fork 后在子进程中关闭文件描述符。
通过外部检测启动来 profile 应用程序
此选项依赖于 tracing 系统检测应用程序启动的能力(无论如何我们都需要此功能来进行性能分析)。
优势
- 从 libc 视角要处理的情况减少了一种
缺点
- 不太准确,将错过启动的前 X 毫秒
- 观察 ftrace 事件以检测启动的机制不是平凡的。
延迟展开
预期许多分配是短暂的,我们可以将堆栈的展开延迟固定的时间。这是内存与 CPU 使用之间的权衡,因为这些堆栈必须保持在内存中,直到被展开或释放。
此图显示 20% 的分配在来自同一进程的 900 个采样分配(在 1% 处,因此总共 500000 个)内被释放。
|
平均: 7000 个分配 |
平均: 8950 字节 |
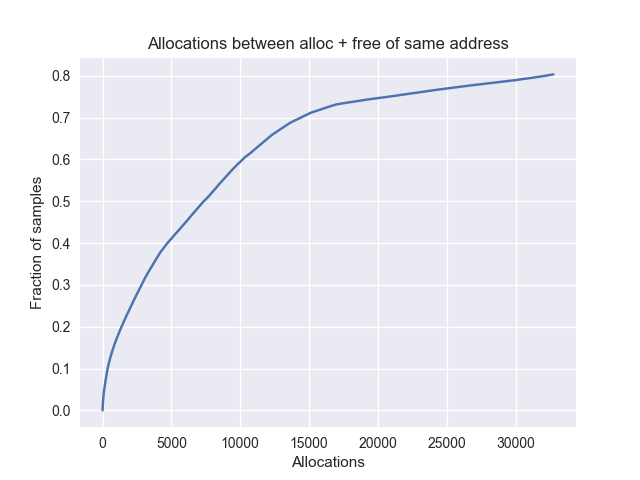
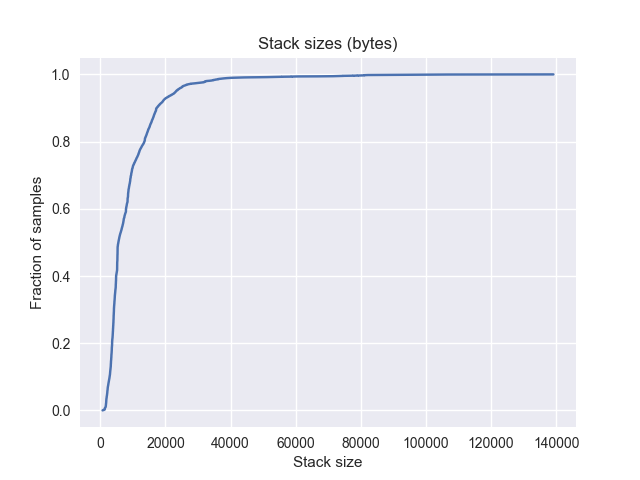
因此,在 1% 采样率下,以每个进程 ~8 兆字节(900 * 8950)的成本,我们可以减少展开次数约 20%。这将不允许我们获得"分配空间"的准确数字,因此拒绝了这个想法。