
缓冲区和数据流
本页描述了在 Perfetto 中采集 trace 时的数据流。它描述了所有缓冲阶段,解释了如何调整缓冲区大小以及如何调试数据丢失。
概念
Perfetto 中的 trace 是异步多写入者单读取者管道。在许多方面,其架构与现代 GPU 的命令缓冲区非常相似。
trace 数据流的设计原则是:
- trace 快速路径基于直接写入共享内存缓冲区。
- 高度优化以实现低开销写入。未针对低延迟读取进行优化。
- Trace 数据最终在 trace 结束时或通过 IPC 通道发出显式刷新请求时提交到中央 trace 缓冲区。
- 生产者是不受信任的,不应该能够看到彼此的 trace 数据,因为这会泄露敏感信息。
在一般情况下,trace 中涉及两种类型的缓冲区。当从 Linux 内核的 ftrace 基础结构中提取数据时,涉及第三阶段缓冲(每个 CPU 一个):
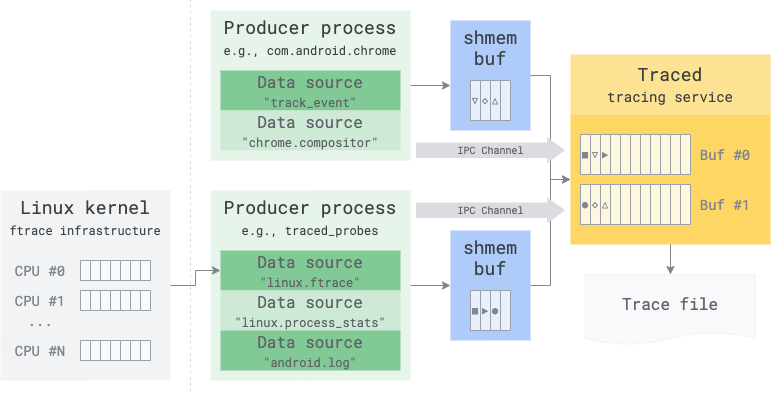
trace 服务的中央缓冲区
这些缓冲区(上图中为黄色)由用户在[trace config](config.md)的 buffers 部分中定义。在最简单的情况下,一个 trace 会话 = 一个缓冲区,无论数据源和生产者的数量如何。
这是 trace 数据最终保存在内存中的地方,无论它来自内核 ftrace 基础结构、traced_probes 中的其他数据源还是使用[Perfetto SDK](/docs/instrumentation/tracing-sdk.md)的另一个用户空间进程。在 trace 结束时(或期间,如果处于流模式),这些缓冲区被写入输出 trace 文件。
这些缓冲区可以包含来自不同数据源甚至不同生产者进程的 trace 数据包的混合。什么写入哪里在 trace config 的[缓冲区映射部分](config.md#dynamic-buffer-mapping)中定义。因此,trace 缓冲区不在进程之间共享,以避免跨生产者进程的交叉对话和信息泄露。
共享内存缓冲区
每个生产者进程都有一个与 trace 服务 1:1 共享的内存缓冲区(上图中为蓝色),无论它托管多少个数据源。此缓冲区是一个临时暂存缓冲区,有两个用途:
写入路径上的零拷贝。此缓冲区允许直接在 trace 服务可直接读取的内存区域中从写入者快速路径序列化 trace 数据。
将写入与 trace 服务的读取解耦。trace 服务的工作是尽可能快地将 trace 数据包从共享内存缓冲区(蓝色)移动到中央缓冲区(黄色)。共享内存缓冲区隐藏了 trace 服务的调度和响应延迟,允许生产者在 trace 服务暂时被阻塞时继续写入而不会丢失数据。
Ftrace 缓冲区
当启用 linux.ftrace 数据源时,内核将有自己的每个 CPU 缓冲区。这些缓冲区是不可避免的,因为内核无法直接写入用户空间缓冲区。traced_probes 进程将定期读取这些缓冲区,将数据转换为二进制 proto,并遵循用户空间 trace 的相同数据流。这些缓冲区只需要足够大以容纳两个 ftrace 读取周期之间的数据(TraceConfig.FtraceConfig.drain_period_ms)。
Trace 数据包的生命周期
以下是了解 trace 数据包在缓冲区之间的数据流的摘要。考虑一个生产者进程托管两个以不同速率写入数据包的数据源的情况,两个数据源都针对同一个中央缓冲区。
当每个数据源开始写入时,它将获取共享内存缓冲区的一个空闲页面并直接将 proto 编码的 trace 数据序列化到其上。
当共享内存缓冲区的一个页面被填满时,生产者将向服务发送异步 IPC,要求它复制刚刚写入的共享内存页面。然后,生产者将获取共享内存缓冲区中的下一个空闲页面并继续写入。
当服务收到 IPC 时,它将共享内存页面复制到中央缓冲区并再次将共享内存缓冲区页面标记为空闲。此时,生产者中的数据源可以重用该页面。
当 trace 会话结束时,服务向所有数据源发送
Flush请求。作为响应,数据源将提交所有未完成的共享内存页面,即使它们没有完全填满。服务将这些页面复制到服务的中央缓冲区中。
缓冲区大小调整
中央缓冲区大小调整
调整中央缓冲区大小的数学计算非常直接:在默认情况下不使用 write_into_file 进行 trace 时(当 trace 文件仅在 trace 结束时写入),缓冲区将容纳各种数据源写入的数据。
trace 的总长度将是 (缓冲区大小) / (聚合写入速率)。如果所有 producer 以 2 MB/s 的组合速率写入,16 MB 缓冲区将容纳 ~8 秒的 trace 数据。
写入速率高度依赖于配置的数据源和系统的活动。对于带有调度器 trace 的 Android trace,1-2 MB/s 是典型数字,但如果启用了更健谈的数据源(例如,syscall 或 pagefault trace),则可以轻松地增加 1+ 个数量级。
当使用流模式时,缓冲区需要能够在两个 file_write_period_ms 周期(默认:5s)之间容纳足够的数据。例如,如果 file_write_period_ms = 5000 并且写入数据速率为 2 MB/s,则中央缓冲区需要至少 5 * 2 = 10 MB 以避免数据丢失。
共享内存缓冲区大小调整
共享内存缓冲区的大小取决于:
- 底层系统的调度特征,即 trace 服务可以在调度程序队列上被阻塞多长时间。这是内核配置和
traced进程的 nice 级别的函数。 - 生产者进程中所有数据源的最大写入速率。
假设生产者以 8 MB/s 的最大速率产生。如果 traced 被阻塞 10 ms,则共享内存缓冲区需要至少 8 * 0.01 = 80 KB 以避免丢失。
经验测量表明,在大多数 Android 系统上,128-512 KB 的共享内存缓冲区大小就足够了。
默认共享内存缓冲区大小为 256 KB。使用 Perfetto 客户端库时,可以通过设置 TracingInitArgs.shmem_size_hint_kb 来调整此值。
WARNING: 如果数据源在单个批次中写入非常大的 trace 数据包,则共享内存缓冲区需要足够大以处理该数据包,或者必须使用 BufferExhaustedPolicy.kStall。
例如,考虑一个每 10 秒发出 2MB 屏幕截图的数据源。其(简化)代码如下所示:
for (;;) {
ScreenshotDataSource::Trace([](ScreenshotDataSource::TraceContext ctx) {
auto packet = ctx.NewTracePacket();
packet.set_bitmap(Grab2MBScreenshot());
});
std::this_thread::sleep_for(std::chrono::seconds(10));
}其平均写入速率为 2MB / 10s = 200 KB/s。但是,数据源将连续创建 2MB 的突发而不产生;它仅受 trace 序列化开销的限制。实际上,它将以 O(GB/s) 的速率写入 2MB 缓冲区。如果共享内存缓冲区 < 2 MB,则 trace service 可能无法以该速率赶上,并且将遇到数据丢失。
在这种情况下,这些选项是:
- 增加托管数据源的生产者中的共享内存缓冲区的大小。
- 将写入拆分为由一些延迟分隔的块。
- 在定义数据源时采用
BufferExhaustedPolicy::kStall:
class ScreenshotDataSource : public perfetto::DataSource<ScreenshotDataSource> {
public:
constexpr static BufferExhaustedPolicy kBufferExhaustedPolicy =
BufferExhaustedPolicy::kStall;
...
};调试数据丢失
Ftrace 内核缓冲区丢失
当使用 Linux 内核 ftrace 数据源时,如果 traced_probes 进程被阻塞太长时间,则在内核 -> 用户空间路径中可能会发生丢失。
在 trace proto 级别,此路径中的丢失记录为:
- 在
FtraceCpuStats消息中,在 trace 的开始和结束时发出。如果overrun字段非零,则数据已丢失。 - 在
FtraceEventBundle.lost_events字段中。这允许精确地定位数据丢失发生的位置。
在 TraceProcessor SQL 级别,此数据在 stats 表中可用:
> select * from stats where name like 'ftrace_cpu_overrun_end'
name idx severity source value
-------------------- -------------------- -------------------- ------ ------
ftrace_cpu_overrun_e 0 data_loss trace 0
ftrace_cpu_overrun_e 1 data_loss trace 0
ftrace_cpu_overrun_e 2 data_loss trace 0
ftrace_cpu_overrun_e 3 data_loss trace 0
ftrace_cpu_overrun_e 4 data_loss trace 0
ftrace_cpu_overrun_e 5 data_loss trace 0
ftrace_cpu_overrun_e 6 data_loss trace 0
ftrace_cpu_overrun_e 7 data_loss trace 0这些丢失可以通过增加TraceConfig.FtraceConfig.buffer_size_kb或减少TraceConfig.FtraceConfig.drain_period_ms来缓解
共享内存丢失
由于 traced 被阻塞时的突发,trace 数据可能会在共享内存中丢失。
在 trace proto 级别,此路径中的丢失记录为:
- 在
TraceStats.BufferStats.trace_writer_packet_loss中。 - 在
TracePacket.previous_packet_dropped中。 注意:每个数据源发出的第一个数据包也被标记为previous_packet_dropped=true。这是因为服务无法判断那是否是真正的第一个数据包,或者在此之前的所有内容都已丢失。
在 TraceProcessor SQL 级别,此数据在 stats 表中可用:
> select * from stats where name = 'traced_buf_trace_writer_packet_loss'
name idx severity source value
-------------------- -------------------- -------------------- --------- -----
traced_buf_trace_wri 0 data_loss trace 0中央缓冲区丢失
中央缓冲区中的数据丢失可能会由于两个不同的原因而发生:
当使用
fill_policy: RING_BUFFER时,由于环形缓冲区的包装,较旧的 trace 数据被覆盖。 这些丢失在 trace proto 级别记录在TraceStats.BufferStats.chunks_overwritten中。当使用
fill_policy: DISCARD时,缓冲区满后提交的较新 trace 数据被丢弃。 这些丢失在 trace proto 级别记录在TraceStats.BufferStats.chunks_discarded中。
在 TraceProcessor SQL 级别,此数据在 stats 表中可用,每个中央缓冲区一个条目:
> select * from stats where name = 'traced_buf_chunks_overwritten' or name = 'traced_buf_chunks_discarded'
name idx severity source value
-------------------- -------------------- -------------------- ------- -----
traced_buf_chunks_di 0 info trace 0
traced_buf_chunks_ov 0 data_loss trace 0Summary: 检测和调试数据丢失的最佳方法是使用 Trace Processor 并发出查询:select * from stats where severity = 'data_loss' and value != 0
原子性和顺序保证
"写入者序列"是由数据源的给定 TraceWriter 发出的 trace 数据包序列。在几乎所有情况下,1 个数据源 == 1+ 个 TraceWriter(s)。支持从多个线程写入的一些数据源通常每个线程创建一个 TraceWriter。
从序列写入的 trace 数据包在它们被写入的相同顺序下在 trace 文件中发出。
不同序列写入的数据包之间没有顺序保证。序列在设计上是并发的,并且可能存在多个线性化。服务不遵守跨不同序列的全局时间戳顺序。如果来自两个序列的两个数据包以全局时间戳顺序发出,服务仍然可以以相反的顺序在 trace 文件中发出它们。
trace 数据包是原子的。如果 trace 数据包在 trace 文件中发出,则保证包含数据源写入的所有字段。如果 trace 数据包很大并跨越多个共享内存缓冲区页面,则只有在观察到所有片段都已提交且没有间隙的情况下,服务才会将其保存在 trace 文件中。
如果 trace 数据包丢失(例如,由于环形缓冲区中的包装或共享内存缓冲区中的丢失),则在该序列中不会发出进一步的 trace 数据包,直到之前的所有数据包也被丢弃。换句话说,如果 trace 服务最终处于看到序列的数据包 1,2,5,6 的情况,它将只发出 1, 2。但是,如果写入新数据包(例如,7, 8, 9)并且它们覆盖 1, 2,清除间隙,则将发出完整的序列 5, 6, 7, 8, 9。 但是,当使用流模式时,此行为不成立,因为在这种情况下,周期性读取将消耗缓冲区中的数据包并清除间隙,允许序列重新启动。
trace 数据包中的增量状态
在许多情况下,trace 数据包彼此完全独立,可以在没有进一步上下文的情况下处理和解释。然而,在某些情况下,它们可以具有_增量状态_并且行为类似于帧间视频编码技术,其中某些帧需要关键帧的存在才能有意义地解码。
这里是两个具体示例:
- Ftrace 调度 slice 和 /proc/pid 扫描。ftrace 调度事件由线程 id 键控。在大多数情况下,用户希望将这些事件映射回父进程(线程组)。为了解决这个问题,当在 Perfetto trace 中同时启用
linux.ftrace和linux.process_stats数据源时,后者确实会从 /proc 伪文件系统中捕获进程<>线程关联,每当 ftrace 看到新的线程-id 时。在这种情况下,典型的 trace 如下所示:
# 来自 process_stats 的 /proc 扫描器。
pid: 610; ppid: 1; cmdline: "/system/bin/surfaceflinger"
# 来自 ftrace
timestamp: 95054961131912; sched_wakeup: pid: 610; target_cpu: 2;
timestamp: 95054977528943; sched_switch: prev_pid: 610 prev_prio: 98/proc 条目每个进程只发出一次,以避免使 trace 的大小膨胀。在没有数据丢失的情况下,这可以很好地重建该 pid 的所有调度事件。但是,如果 process_stats 数据包在环形缓冲区中被丢弃,则将无法为引用该 PID 的所有其他 ftrace 事件计算进程详细信息。
- Perfetto SDK 中的[Track Event 库](/docs/instrumentation/track-events)大量使用字符串驻留。大多数字符串和描述符(例如,关于进程/线程的详细信息)只发出一次,随后使用单调 ID 引用。在描述符数据包丢失的情况下,不可能完全理解这些事件。
Trace Processor 具有内置机制,可以检测驻留数据的丢失,并跳过引用缺失的驻留字符串或描述符的数据包的摄取。
当在环形缓冲区模式下使用 trace 时,这些类型的丢失非常可能发生。
有两种缓解方法:
通过
TraceConfig.IncrementalStateConfig.clear_period_ms发出增量状态的定期失效。这将导致使用增量状态的数据源定期丢弃驻留/进程映射表,并在下次出现时重新发出描述符/字符串。这很好地缓解了环形缓冲区 trace 上下文中的问题,只要clear_period_ms比中央 trace 缓冲区中 trace 数据的估计长度低一个数量级。将增量状态记录到专用缓冲区中(通过
DataSourceConfig.target_buffer)。此技术通常与前面提到的 ftrace + process_stats 示例一起使用,将 process_stats 数据包记录在不太可能包装的专用缓冲区中(ftrace 事件比新进程的描述符频繁得多)。
刷新和窗口化 trace 导入
另一个在涉及多个数据源的 trace 中遇到的常见问题是 trace 提交的非同步性质。如上面的[trace 数据包的生命周期](#life-of-a-trace-packet)部分所述,trace 数据仅在共享内存缓冲区的完整内存页面被填满时(或在 trace 会话结束时)提交。在大多数情况下,如果数据源以定期节奏产生事件,页面会被相当快地填充,并且事件在几秒钟内提交到中央缓冲区。
然而,在其他情况下,数据源可能只是零星地发出事件。想象一下数据源在显示器打开/关闭时发出事件的情况。这种不频繁的事件最终可能会在共享内存缓冲区中暂存很长时间,并且可能会在发生数小时后才提交到 trace 缓冲区。
可能发生这种情况的另一个场景是使用 ftrace 并且特定 CPU 在大多数时间处于空闲状态或被热拔出(ftrace 使用每个 CPU 缓冲区)。在这种情况下,CPU 可能会记录很少或根本没有数据几分钟,而其他 CPU 每秒泵送数千个新的 trace 事件。
这会导致两个最终破坏用户期望或导致错误的副作用:
UI 可以显示一个异常长的 Timeline,中间有一个巨大的间隙。事件的数据包顺序对 UI 没有影响,因为事件在导入时按时间戳排序。在这种情况下,trace 将包含非常近期的事件加上一些在几小时前发生的陈旧事件。UI,为了正确性,将尝试显示所有事件,显示一些早期事件,随后是一个巨大的时间间隔,在此期间没有任何事情发生,随后是近期事件流。
当记录长 trace 时,Trace Processor 可以显示形式为 "XXX event out-of-order" 的导入错误。这是因为,为了在导入时限制内存使用,Trace Processor 使用滑动窗口对事件进行排序。如果 trace 数据包过于无序(trace 文件顺序与时间戳顺序),排序将失败,并且某些数据包将被丢弃。
缓解措施
对于这类问题的最佳缓解措施是在 trace config 中指定flush_period_ms(对于大多数情况,10-30 秒通常就足够了),尤其是在采集长 trace 时。
这将导致 trace service 向数据源发出定期刷新请求。刷新请求导致数据源将共享内存缓冲区页面提交到中央缓冲区,即使它们没有完全填满。默认情况下,刷新仅在 trace 结束时发出。
对于在没有 flush_period_ms 的情况下采集的长 trace,另一个选项是在导入 trace 时将 --full-sort 选项传递给 trace_processor_shell。这样做将禁用窗口化排序,但代价是更高的内存使用(trace 文件将在解析之前完全缓冲在内存中)。