
在 Kubernetes 上部署 Bigtrace
NOTE: 本文档是为 Bigtrace 服务的管理员而非 Bigtrace 用户设计的。这也为非 Google 员工设计 - Google 员工应查看 go/bigtrace。
Bigtrace 概述
Bigtrace 是一个通过在 Kubernetes 集群中分布 TraceProcessor 实例来处理 O(百万)级 trace 的工具。
Bigtrace 的设计由四个主要部分组成:
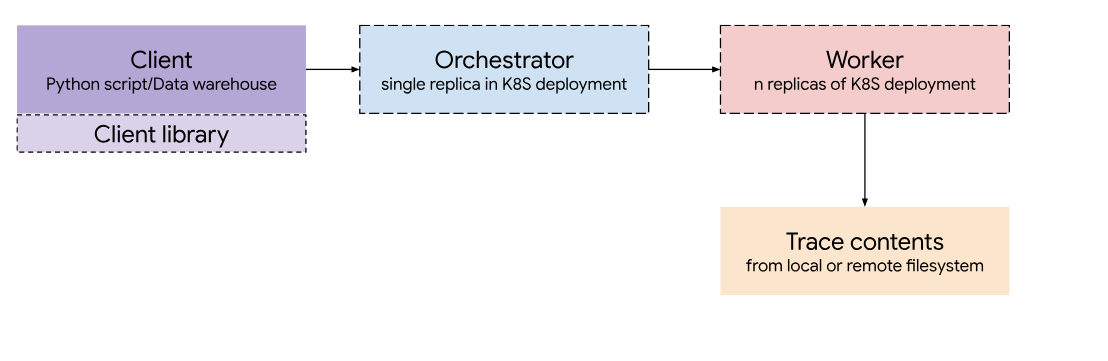
客户端
有三种客户端可以与 Bigtrace 交互:Python API、clickhouse-client 和 Apache Superset。
- Python API 存在于 Perfetto python 库中,可以类似于 TraceProcessor 和 BatchTraceProcessor API 使用。
- Clickhouse 是一个数据仓库解决方案,为用户提供基于 SQL 的界面来编写查询,这些查询通过 gRPC 发送到 Orchestrator。这可以使用 clickhouse-client 原生访问,它提供了一个 CLI,允许用户向数据库编写查询。
- Superset 是 Clickhouse 的 GUI,提供 SQLLab 来运行查询,支持现代功能如多标签页、自动完成和语法高亮,以及提供数据可视化工具来轻松从查询结果创建图表。
编排器
Orchestrator 是服务的核心组件,负责将 trace 分片到各个 Worker pod,并将结果流式传输到 Client。
工作节点
每个 Worker 运行一个 TraceProcessor 实例,并在给定的 trace 上执行输入的查询。每个 Worker 在集群中的自己的 pod 上运行。
Object Store (GCS)
对象存储包含服务可以查询的 trace 集合,由 Worker 访问。 目前,支持 GCS 作为主要对象存储,以及加载存储在每台机器本地的 trace 用于测试。
可以通过在 src/bigtrace/worker/repository_policies 中创建新的存储库策略来添加额外的集成。
在 GKE 上部署 Bigtrace
GKE
部署 Bigtrace 的推荐方式是在 Google Kubernetes Engine 上,本指南将解释该过程。
前提条件:
- 一个 GCP 项目
- GCS
- GKE
- gcloud (https://cloud.google.com/sdk/gcloud)
- Perfetto 目录的克隆
服务账号权限
除了 Compute Engine 服务账号的默认 API 访问权限外,还需要以下权限:
- Storage Object User - 允许 Worker 检索 GCS 身份验证令牌
这些可以在 GCP 上通过 IAM & Admin > IAM > Permissions 添加。
设置集群
创建集群
- 在 GCP 中导航到 Kubernetes Engine
- 创建一个标准集群(Create > Standard > Configure)
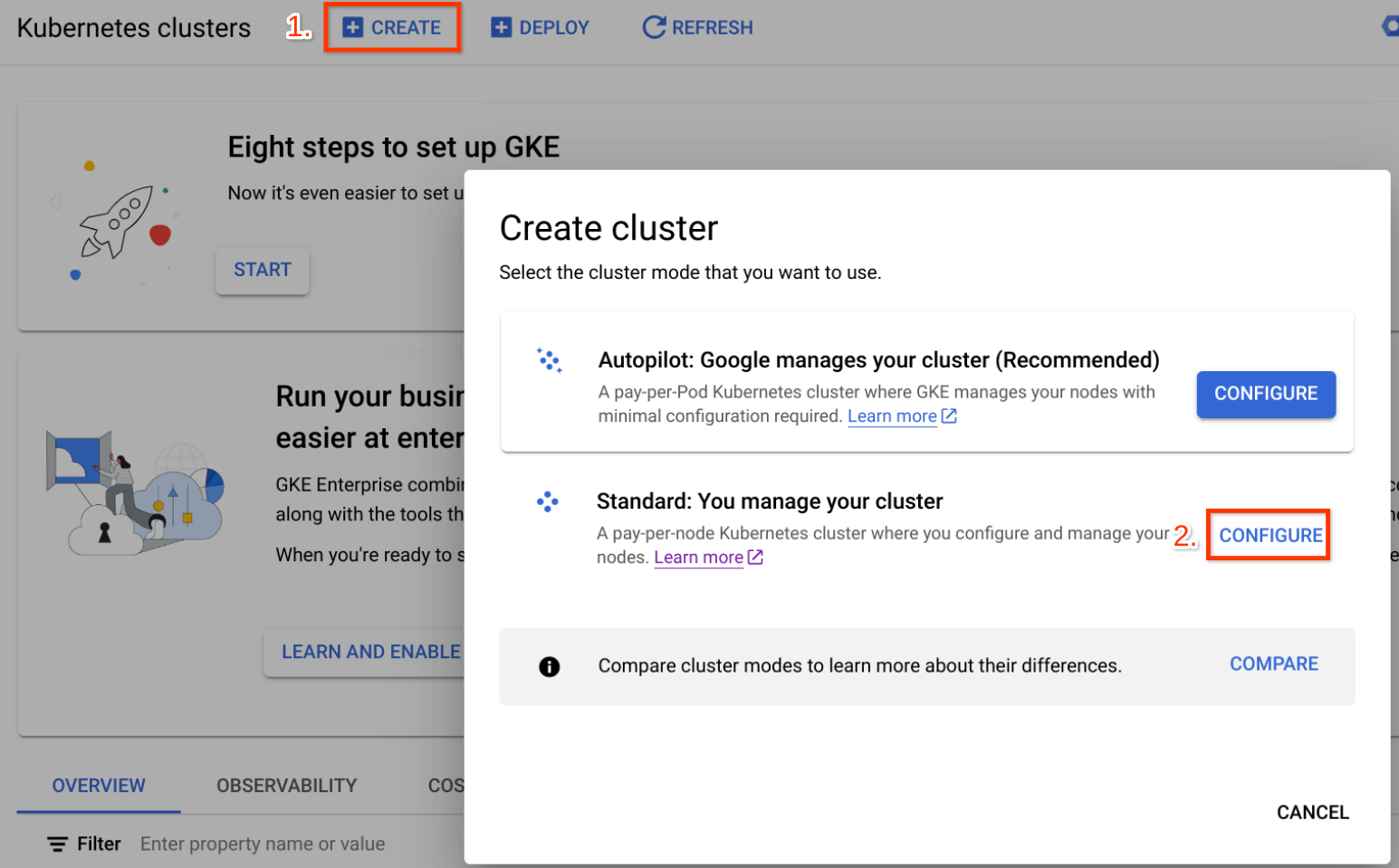
- 在 Cluster basics 中,选择位置类型 - 使用 zonal 以获得最佳负载均衡性能
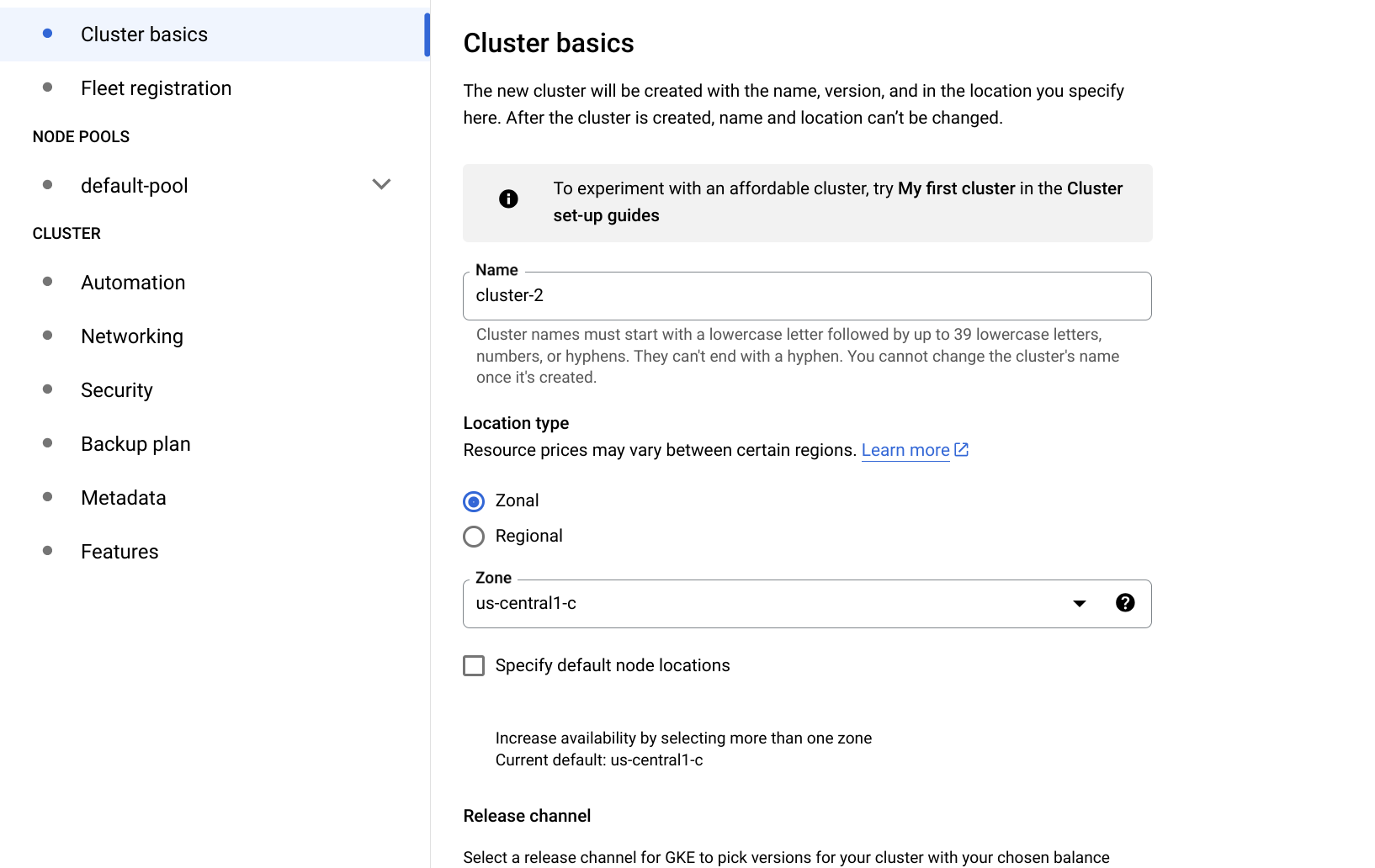
- 在 Node pools > default-pool > Nodes 中,选择 VM 类型 - 最好是标准类型 - 例如 e2-standard-8 或更高
- 在 Networking 标签页中,为 L4 内部负载均衡器启用子网(这对于在 VPC 内使用内部负载均衡的服务是必需的)
- 创建集群
访问集群
要使用 kubectl 应用部署和服务的 yaml 文件,必须首先连接并通过集群进行身份验证。
你可以在设备上或使用以下命令在 cloud shell 中按照这些说明操作:
gcloud auth login
gcloud container clusters get-credentials [CLUSTER_NAME] --zone [ZONE]--project [PROJECT_NAME]部署 Orchestrator
Orchestrator 的部署需要两个主要步骤:构建镜像并推送到 Artifact Registry,以及部署到集群。
构建和上传 Orchestrator 镜像
配置 docker 以推送到 Google Cloud artifact registry
gcloud auth configure-docker [ZONE]-docker.pkg.dev要构建镜像并推送到 Artifact Registry,首先导航到 perfetto 目录,然后运行以下命令:
docker build -t bigtrace_orchestrator infra/bigtrace/docker/orchestrator
docker tag bigtrace_orchestrator [ZONE]-docker.pkg.dev/[PROJECT_NAME]/[REPO_NAME]/bigtrace_orchestrator
docker push [ZONE]-docker.pkg.dev/[PROJECT_NAME]/[REPO_NAME]/bigtrace_orchestrator应用 yaml 文件
要使用上一步构建的注册表中的镜像,必须修改 orchestrator-deployment.yaml 文件以替换该行。
image: [ZONE]-docker.pkg.dev/[PROJECT_NAME]/[REPO_NAME]/bigtrace_orchestrator还应根据之前选择的每个 pod 的 vCPU 设置 CPU 资源。
resources:
requests:
cpu: [VCPUS_PER_MACHINE]
limits:
cpu: [VCPUS_PER_MACHINE]然后要部署 Orchestrator,你需要应用 orchestrator-deployment.yaml 和 orchestrator-ilb.yaml,分别用于部署和内部负载均衡服务。
kubectl apply -f infra/bigtrace/gke/orchestrator-deployment.yaml
kubectl apply -f infra/bigtrace/gke/orchestrator-ilb.yaml这将 Orchestrator 作为单个副本部署在 pod 中,并将其作为服务公开,供客户端在 VPC 内访问。
部署 Worker
与 Orchestrator 类似,首先构建镜像并推送到 Artifact Registry。
docker build -t bigtrace_worker infra/bigtrace/docker/worker
docker tag bigtrace_worker [ZONE]-docker.pkg.dev/[PROJECT_NAME]/[REPO_NAME]/bigtrace_worker
docker push [ZONE]-docker.pkg.dev/[PROJECT_NAME]/[REPO_NAME]/bigtrace_worker然后修改 yaml 文件以反映镜像以及适合用例的所需配置。
image: [ZONE]-docker.pkg.dev/[PROJECT_NAME]/[REPO_NAME]/bigtrace_worker
...
replicas: [DESIRED_REPLICA_COUNT]
...
resources:
requests:
cpu: [VCPUS_PER_MACHINE]然后按如下方式部署部署和服务:
kubectl apply -f infra/bigtrace/gke/worker-deployment.yaml
kubectl apply -f infra/bigtrace/gke/worker-service.yaml部署 Clickhouse
构建和上传 Clickhouse 部署镜像
此镜像基于基础 Clickhouse 镜像构建,并提供了 gRPC 与 Orchestrator 通信所需的 Python 库。
docker build -t clickhouse infra/bigtrace/bigtrace_clickhouse
docker tag clickhouse [ZONE]-docker.pkg.dev/[PROJECT_NAME]/[REPO_NAME]/clickhouse
docker push [ZONE]-docker.pkg.dev/[PROJECT_NAME]/[REPO_NAME]/clickhouse要在集群中的 pod 上部署此镜像,必须使用 kubectl 应用提供的 yaml 文件,例如:
kubectl apply -f infra/bigtrace/clickhouse/clickhouse-config.yaml
kubectl apply -f infra/bigtrace/clickhouse/pvc.yaml
kubectl apply -f infra/bigtrace/clickhouse/pv.yaml
kubectl apply -f infra/bigtrace/clickhouse/clickhouse-deployment.yaml
kubectl apply -f infra/bigtrace/clickhouse/clickhouse-ilb.yaml对于 clickhouse-deployment.yaml,你必须将镜像变量替换为上一步构建的镜像的 URI - 该镜像包含安装了 gRPC 所需 Python 文件的 Clickhouse 镜像。
env 变量 BIGTRACE_ORCHESTRATOR_ADDRESS 也必须更改为 GKE 给出的 Orchestrator 服务的地址:
containers:
- name: clickhouse
image: # [ZONE]-docker.pkg.dev/[PROJECT_NAME]/[REPO_NAME]/clickhouse
env:
- name: BIGTRACE_ORCHESTRATOR_ADDRESS
value: # Address of Orchestrator service如果要验证部署是否成功,可以运行:
kubectl get deployments这应该生成类似以下的输出:
NAME READY UP-TO-DATE AVAILABLE AGE
clickhouse 0/1 1 0 106s
orchestrator 0/1 1 0 48m
worker 0/5 5 0 27m这意味着 orchestrator、workers 和 clickhouse 已成功部署。
文件摘要
部署
包含 Clickhouse 服务器的镜像并配置必要的卷和资源。
Internal Load Balancer Service (ILB)
此内部负载均衡器用于允许从 GKE 中的 VPC 内访问 Clickhouse 服务器 pod。这意味着集群外的 VM 可以通过 Clickhouse Client 访问 Clickhouse 服务器,而无需将服务公开给公众。
Persistent Volume and Persistent Volume Claim
这些文件创建 Clickhouse 服务器所需的卷,以便在 pod 故障时持久化数据库。
Config
这是可以指定 Clickhouse 配置文件以根据用户要求自定义服务器的地方。(https://clickhouse.com/docs/en/operations/server-configuration-parameters/settings)
通过 clickhouse-client (CLI) 访问 Clickhouse
你可以通过以下方式部署 Clickhouse: https://clickhouse.com/docs/en/install
通过 CLI 运行客户端时,重要的是指定: ./clickhouse client --host [ADDRESS] --port [PORT] --receive-timeout=1000000 --send-timeout=100000 --idle_connection_timeout=1000000
部署 Superset
有两种部署 Superset 的方法 - 一种用于开发,一种用于生产。
你可以按照以下说明在 VM 中部署 Superset 实例用于开发: https://superset.apache.org/docs/quickstart
你可以按照以下说明在 Kubernetes 上跨 pod 部署生产就绪的实例: https://superset.apache.org/docs/installation/kubernetes
然后可以通过 clickhouse-connect 将 Superset 连接到 Clickhouse,按照此链接的说明操作,但用部署的连接详细信息替换第一步:https://clickhouse.com/docs/en/integrations/superset