
调试 Android 内存占用
在本指南中,你将学习如何:
- 使用
dumpsys meminfo获取内存使用的高级概览。 - 理解 Linux 内存管理的基础知识。
- 使用 Perfetto 调查随时间变化的内存使用情况。
- 分析 native heap profile 和 Java heap dump 以识别内存泄漏。
前置条件
- 运行 macOS 或 Linux 的主机。
- 已安装 ADB 并在 PATH 中。
- 运行 Android 11+ 的设备。
如果你正在分析自己的应用并且不是运行 userdebug 版本的 Android,你的应用需要在 manifest 中标记为 profileable 或 debuggable。更多详细信息请参阅 heapprofd 文档,了解哪些应用可以作为目标。
dumpsys meminfo
开始调查进程内存使用情况的一个好方法是使用 dumpsys meminfo,它提供了进程使用各种类型内存的高级概览。
$ adb shell dumpsys meminfo com.android.systemui
Applications Memory Usage (in Kilobytes):
Uptime: 2030149 Realtime: 2030149
** MEMINFO in pid 1974 [com.android.systemui] **
Pss Private Private SwapPss Rss Heap Heap Heap
Total Dirty Clean Dirty Total Size Alloc Free
------ ------ ------ ------ ------ ------ ------ ------
Native Heap 16840 16804 0 6764 19428 34024 25037 5553
Dalvik Heap 9110 9032 0 136 13164 36444 9111 27333
[更多内容...]查看 Dalvik Heap (= Java Heap) 和 Native Heap 的 "Private Dirty" 列,我们可以看到 SystemUI 在 Java heap 上的内存使用是 9M,在 native heap 上是 17M。
Linux 内存管理
但是 clean ,dirty ,Rss ,Pss ,Swap 实际上意味着什么?要回答这个问题,我们需要稍微深入了解 Linux 内存管理。
从内核的角度来看,内存被分成相同大小的块,称为 pages 。这些通常是 4KiB。
Pages 被组织成虚拟连续的范围,称为 VMA (Virtual Memory Area)。
当进程通过 mmap() system call 请求新的内存页面池时,会创建 VMA。应用程序很少直接调用 mmap()。这些调用通常由分配器中介,对于 native 进程是 malloc()/operator new(),对于 Java 应用则由 Android RunTime 中介。
VMA 可以分为两种类型:文件支持的和匿名的。
文件支持的 VMA 是内存中的文件视图。它们通过将文件描述符传递给 mmap() 获得。内核将通过传递的文件为 VMA 上的 page faults 提供服务,因此读取指向 VMA 的指针等同于对文件的 read() 操作。文件支持的 VMA 被用于,例如,动态链接器 (ld) 在执行新进程或动态加载库时,或者 Android 框架在加载新的 .dex 库或访问 APK 中的资源时。
匿名 VMA 是仅内存的区域,不支持任何文件。这是分配器从内核请求动态内存的方式。匿名 VMA 通过调用 mmap(... MAP_ANONYMOUS ...) 获得。
物理内存仅在应用程序尝试从 VMA 读取/写入时,以页面粒度分配。如果你分配了 32 MiB 的页面但只触及一个字节,你进程的内存使用只会增加 4KiB。你将进程的 虚拟内存 增加了 32 MiB,但其驻留的 物理内存 只增加了 4 KiB。
在优化程序的内存使用时,我们感兴趣的是减少它们在 物理内存 中的占用。高 虚拟内存 使用通常在现代平台上不会引起关注(除非你用完了地址空间,这在 64 位系统上很难做到)。
我们将进程驻留在 物理内存 中的内存量称为其 RSS (Resident Set Size)。但并非所有驻留内存都是相等的。
从内存消耗的角度来看,VMA 内的单个页面可以具有以下状态:
- Resident: 页面映射到物理内存页面。驻留页面可以有两种状态:
- Clean (仅适用于文件支持的页面):页面的内容与磁盘上的内容相同。在内存压力下,内核可以更容易地驱逐 clean 页面。这是因为如果它们再次需要,内核知道可以通过从底层文件读取来重新创建其内容。
- Dirty: 页面的内容与磁盘不同,或者(在大多数情况下)页面没有磁盘支持(即它是 匿名 的)。Dirty 页面无法被驱逐,因为这样做会导致数据丢失。但是它们可以被交换到磁盘或 ZRAM(如果存在)。
- Swapped: dirty 页面可以被写入磁盘上的交换文件(在大多数 Linux 桌面发行版上)或被压缩(在 Android 和 CrOS 上通过 ZRAM)。页面将保持交换状态,直到在其虚拟地址上发生新的 page fault,此时内核会将其带回主内存。
- Not present: 页面上从未发生过 page fault,或者页面是 clean 的,后来被驱逐了。
通常更重要的是减少 dirty 内存的数量,因为它不能像 clean 内存那样回收,并且在 Android 上,即使在 ZRAM 中交换,仍然会消耗部分系统内存预算。这就是为什么我们在 dumpsys meminfo 示例中查看 Private Dirty 的原因。
共享 内存可以映射到多个进程中。这意味着不同进程中的 VMA 引用相同的物理内存。这通常发生在常用库的文件支持内存(例如,libc.so、framework.dex)中,或者更罕见的是,当进程 fork() 时,子进程从其父进程继承 dirty 内存。
这引入了 PSS (Proportional Set Size) 的概念。在 PSS 中,驻留在多个进程中的内存按比例归因于每个进程。如果我们将一个 4KiB 页面映射到四个进程中,每个进程的 PSS 都会增加 1KiB。
回顾
- 动态分配的内存,无论是通过 C 的
malloc()、C++ 的operator new()还是 Java 的new X()分配的,总是以 匿名 和 dirty 开始,除非它从未被使用。 - 如果此内存一段时间未被读/写,或者在内存压力的情况下,它会被交换到 ZRAM 中并变为 swapped 。
- 匿名内存,无论是 _驻留_(因此 dirty )还是 swapped ,总是资源占用者,如果不必要应避免。
- 文件映射的内存来自代码(java 或 native)、库和资源,几乎总是 clean 。Clean 内存也会侵蚀系统内存预算,但通常应用程序开发人员对其控制较少。
随时间变化的内存
dumpsys meminfo 适合获取当前内存使用的快照,但即使是很短的内存峰值也可能导致低内存情况,这将导致 LMKs。我们有两种工具来调查这种情况:
- RSS High Watermark。
- Memory tracepoints。
RSS 高水位
我们可以从 /proc/[pid]/status 文件中获得大量信息,包括内存信息。VmHWM 显示进程自启动以来看到的最大 RSS 使用情况。此值由内核保持更新。
$ adb shell cat '/proc/$(pidof com.android.systemui)/status'
[...]
VmHWM: 256972 kB
VmRSS: 195272 kB
RssAnon: 30184 kB
RssFile: 164420 kB
RssShmem: 668 kB
VmSwap: 43960 kB
[...]Memory tracepoint
NOTE: 有关 memory trace points 的详细说明,请参阅 Data sources > Memory > Counters and events 页面。
我们可以使用 Perfetto 从内核获取有关内存管理事件的信息。
$ adb shell perfetto \
-c - --txt \
-o /data/misc/perfetto-traces/trace \
<<EOF
buffers: {
size_kb: 8960
fill_policy: DISCARD
}
buffers: {
size_kb: 1280
fill_policy: DISCARD
}
data_sources: {
config {
name: "linux.process_stats"
target_buffer: 1
process_stats_config {
scan_all_processes_on_start: true
}
}
}
data_sources: {
config {
name: "linux.ftrace"
ftrace_config {
ftrace_events: "mm_event/mm_event_record"
ftrace_events: "kmem/rss_stat"
ftrace_events: "kmem/ion_heap_grow"
ftrace_events: "kmem/ion_heap_shrink"
}
}
}
duration_ms: 30000
EOF在它运行时,如果你跟随操作,请拍摄照片。
使用 adb pull /data/misc/perfetto-traces/trace ~/mem-trace 拉取文件并上传到 Perfetto UI。这将显示系统 ION 使用的总体统计信息,以及要展开的每个进程统计信息。向下滚动(或 Ctrl-F 搜索)到 com.google.android.GoogleCamera 并展开。这将显示相机的各种内存统计信息的 Timeline。
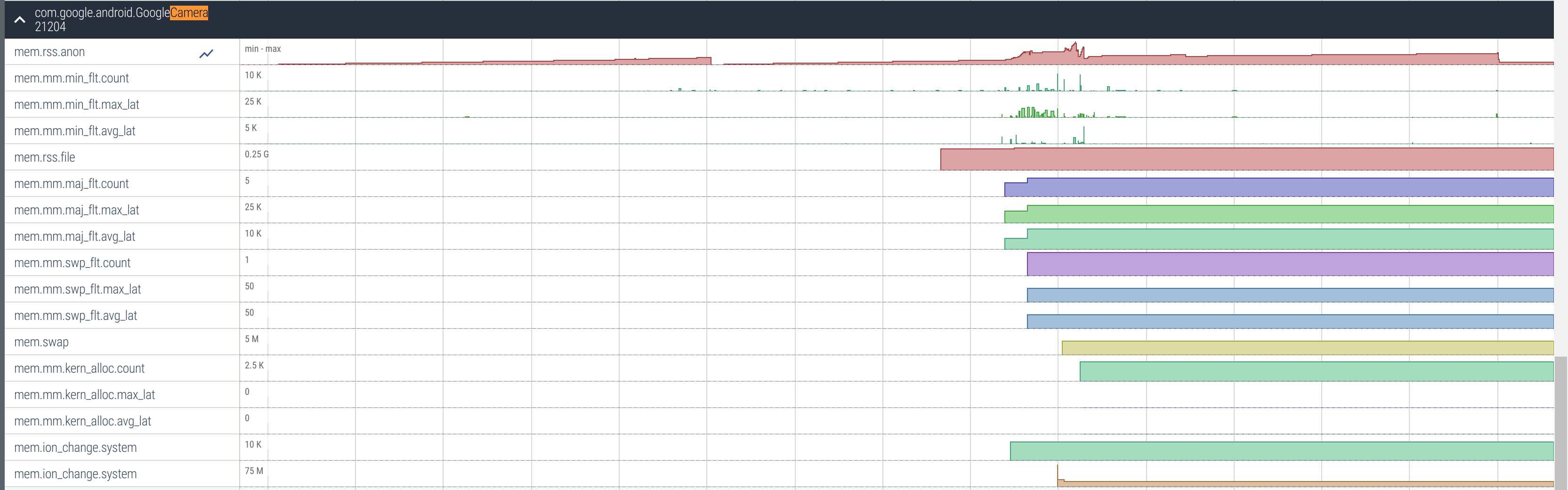
我们可以看到,在 trace 的大约 2/3 处,内存激增(在 mem.rss.anon track 中)。这就是我拍摄照片的地方。这是查看应用程序的内存使用如何对不同触发做出反应的好方法。
使用哪个工具
如果你想深入到由 Java 代码分配的 匿名 内存,dumpsys meminfo 将其标记为 Dalvik Heap,请参阅 分析 java heap 部分。
如果你想深入到由 native 代码分配的 匿名 内存,dumpsys meminfo 将其标记为 Native Heap,请参阅 分析 Native Heap 部分。注意,即使你的应用没有任何 C/C++ 代码,最终也可能有 native 内存。这是因为某些框架 API(例如 Regex)的实现是通过 native 代码内部实现的。
如果你想深入到文件映射的内存,最好的选择是使用 adb shell showmap PID(在 Android 上)或检查 /proc/PID/smaps。
低内存杀死
当 Android 设备内存不足时,一个名为 lmkd 的守护进程将开始杀死进程以释放内存。设备的策略各不相同,但通常进程将按降序的 oom_score_adj 分数被杀死(即后台应用程序和进程优先,前台进程最后)。
Android 上的应用程序在切换离开时不会被杀死。相反,即使用户完成使用它们后,它们仍然保持 缓存 状态。这是为了使应用程序的后续启动更快。此类应用程序通常首先被杀死(因为它们具有更高的 oom_score_adj)。
我们可以使用 Perfetto 收集有关 LMK 和 oom_score_adj 的信息。
$ adb shell perfetto \
-c - --txt \
-o /data/misc/perfetto-traces/trace \
<<EOF
buffers: {
size_kb: 8960
fill_policy: DISCARD
}
buffers: {
size_kb: 1280
fill_policy: DISCARD
}
data_sources: {
config {
name: "linux.process_stats"
target_buffer: 1
process_stats_config {
scan_all_processes_on_start: true
}
}
}
data_sources: {
config {
name: "linux.ftrace"
ftrace_config {
ftrace_events: "lowmemorykiller/lowmemory_kill"
ftrace_events: "oom/oom_score_adj_update"
ftrace_events: "ftrace/print"
atrace_apps: "lmkd"
}
}
}
duration_ms: 60000
EOF使用 adb pull /data/misc/perfetto-traces/trace ~/oom-trace 拉取文件并上传到 Perfetto UI。

我们可以看到,当 Camera 打开时,其 OOM 分数降低(使其不太可能被杀死),关闭后再次增加。
分析 Native Heap
Native Heap Profiles 需要 Android 10。
NOTE: 有关 native heap profiler 和故障排除的详细说明,请参阅 Data sources > Heap profiler 页面。
应用程序通常通过 malloc 或 C++ 的 new 而不是直接从内核获取内存。分配器确保你的内存得到更有效的处理(即没有太多间隙),并且从内核请求的开销保持较低。
我们可以使用 heapprofd 记录进程执行的 native 分配和释放。生成的 profile 可用于将内存使用归因于特定的函数调用栈,支持 native 和 Java 代码的混合。Profile _仅显示在运行时进行的分配_,之前进行的任何分配都不会显示。
捕获 profile
使用 tools/heap_profile 脚本的 android 子命令来 profile 连接的 Android 设备上的进程。如果你遇到问题,请确保你使用 最新版本。使用 tools/heap_profile android -h 查看所有参数,或使用默认值并仅 profile 进程(例如 system_server):
$ tools/heap_profile android -n system_server
Profiling active. Press Ctrl+C to terminate.
You may disconnect your device.
Wrote profiles to /tmp/profile-1283e247-2170-4f92-8181-683763e17445 (symlink /tmp/heap_profile-latest)
The raw-trace and heap_dump.* (pprof) files can be visualized with https://ui.perfetto.dev.当你看到 Profiling active 时,请在手机上操作一下。完成后,按 Ctrl-C 结束 profile。对于本教程,我打开了几个应用程序。
查看数据
然后将输出目录中的 raw-trace 文件上传到 Perfetto UI 并点击显示的菱形标记。

可用的选项卡包括:
- Unreleased malloc size: 在创建 dump 时,在此调用栈中分配但未释放的字节数。
- Total malloc size: 在此调用栈中分配的字节数(包括在 dump 时刻释放的字节)。
- Unreleased malloc count: 在此调用栈中进行的没有匹配释放的分配数。
- Total malloc count: 在此调用栈中进行的分配数(包括具有匹配释放的分配)。
默认视图将显示在 profile 运行时进行但未释放的所有分配(space 选项卡)。
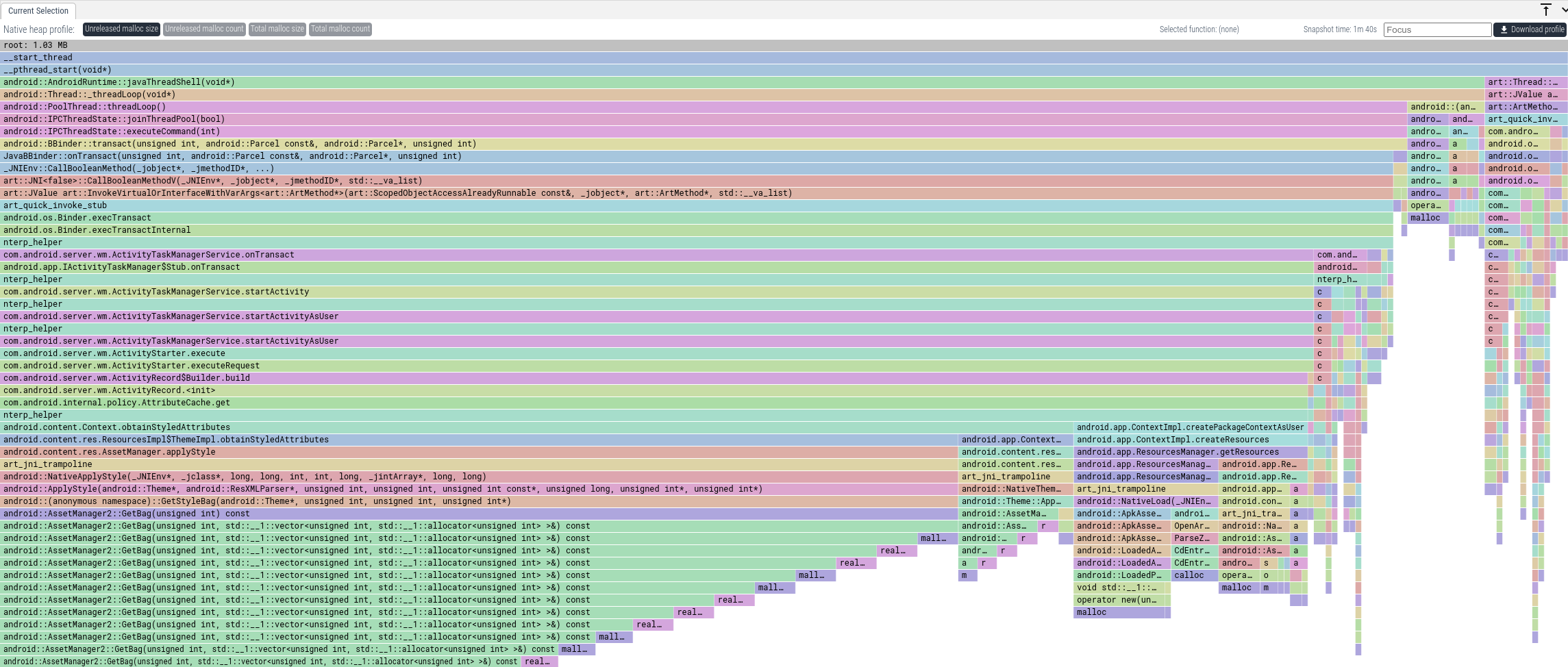
我们可以看到,通过 AssetManager.applyStyle 的路径分配了大量内存。要获取以这种方式分配的总内存,我们可以在 Focus 文本框中输入 "applyStyle"。这将仅显示某些帧匹配 "applyStyle" 的调用栈。
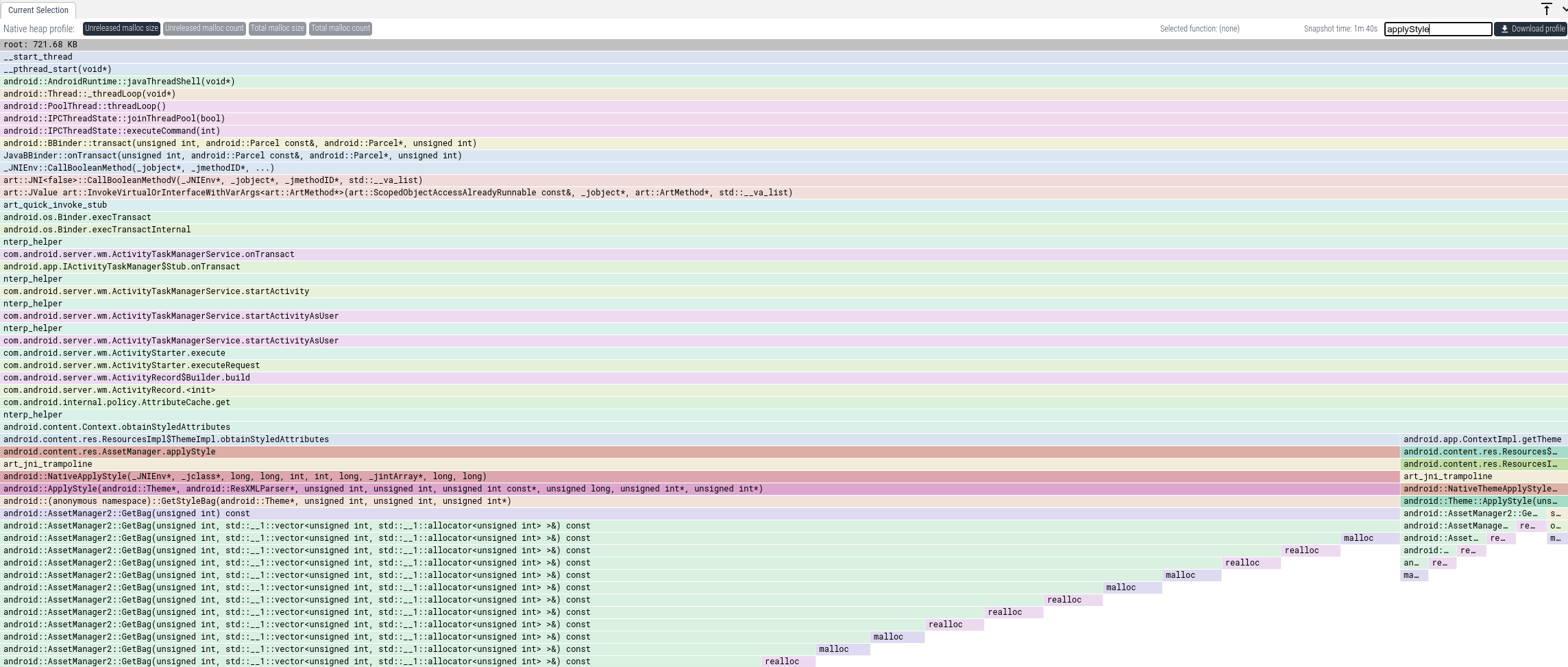
由此我们清楚地知道必须查看代码中的哪个位置。从代码中我们可以看到该内存如何被使用,以及我们是否真的需要所有这些内存。
分析原始 mmap 调用
大多数 native 内存分配通过 malloc 进行,这是 heapprofd(上面的 Native Heap Profiler)可以看到的。然而,某些组件(例如 ART、图形驱动程序、自定义分配器)可能使用 mmap 直接从内核请求内存。这些分配对 heapprofd 是不可见的。
要调试这些,我们可以利用 mmap 调用相对罕见(与 malloc 相比)的事实。与 CPU profiling 不同,我们在 CPU profiling 中频繁 采样 以最小化开销,对于 mmap,我们可以记录 每一个事件,而不会产生显著的性能影响。
我们可以使用两个数据源实现这一点:
linux.ftrace带有syscall_events:这为我们提供每个 mmap 调用的时间戳、参数(大小、标志)和返回值。需要 Android 14 (U) 或更新版本。linux.perf:我们可以配置 perf 采样器在mmapsyscall 上触发。关键是,我们设置period: 1以捕获 每个 发生次数的调用栈。支持 Android 12 (S) 或更新版本。
使用 Perfetto
你可以在单个 Perfetto 配置中组合两个数据源。
注意:mmap 的 syscall ID 因架构而异。
- arm64:
222(以下示例中使用) - x86_64:
9
buffers: {
size_kb: 63488
fill_policy: RING_BUFFER
}
data_sources: {
config {
name: "linux.ftrace"
ftrace_config {
# 使用 syscall 名称;Perfetto 处理 ID 映射。
# 需要 Android 14+
syscall_events: "sys_mmap"
syscall_events: "sys_munmap"
syscall_events: "sys_madvise"
# 可选: 捕获调度以查看哪个线程正在调用 mmap
ftrace_events: "sched/sched_switch"
}
}
}
data_sources {
config {
name: "linux.perf"
perf_event_config {
timebase {
period: 1 # 捕获每个发生,无采样!
tracepoint {
name: "raw_syscalls:sys_enter"
# 过滤器: 222 是 arm64 上的 mmap。在 x86_64 上使用 9。
filter: "id == 222"
}
}
callstack_sampling {
# 可选: 将范围限定到特定目标
# scope { target_cmdline: "your.app.package" }
kernel_frames: true
}
}
}
}
duration_ms: 10000使用 Simpleperf
如果你只需要调用栈(而不是 ftrace 参数 Timeline),你也可以使用 simpleperf 带有 --tp-filter 标志来实现相同的结果。
# 记录每个 mmap 的调用栈(arm64 上 id == 222)
adb shell 'simpleperf record -e raw_syscalls:sys_enter --tp-filter "id == 222" -a --duration 10 -g'分析 Java Heap
Java Heap Dumps 需要 Android 11。
NOTE: 有关捕获 Java heap dump 和故障排除的详细说明,请参阅 Data sources > Java heap dumps 页面。
转储 java heap
我们可以获取构成 Java heap 的所有 Java 对象的图的快照。我们使用 tools/java_heap_dump 脚本。如果你遇到问题,请确保你使用 最新版本。
$ tools/java_heap_dump -n com.android.systemui
Dumping Java Heap.
Wrote profile to /tmp/tmpup3QrQprofile
This can be viewed using https://ui.perfetto.dev.我们还可以在分配开始因 java.lang.OutOfMemoryError 而失败时收集对象图的快照。
查看数据
将 trace 上传到 Perfetto UI 并点击显示的菱形标记。
这将呈现一组如以下所述的火焰图视图。
"Size" 和 "Objects" 选项卡
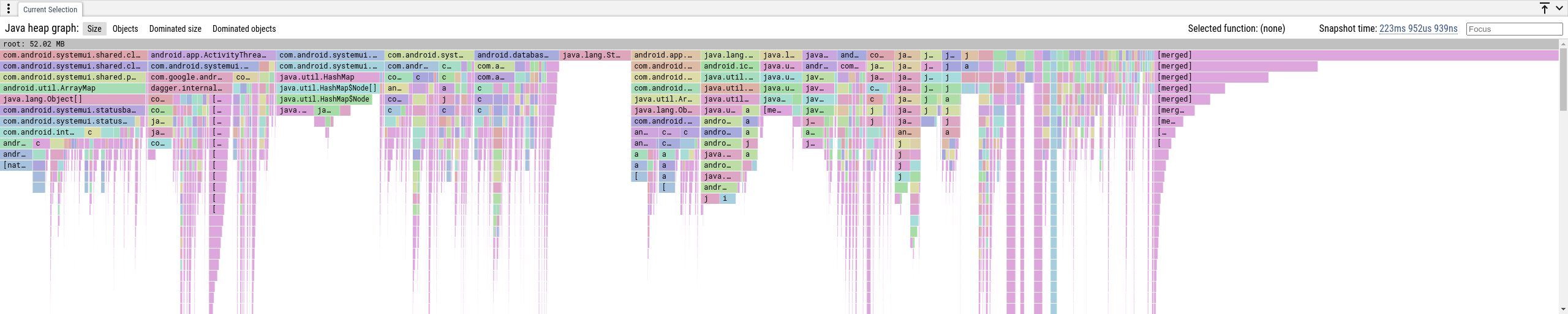
这些视图显示归因于到垃圾回收根的最短路径的内存。通常,对象可以通过许多路径到达,我们只显示最短的,因为这减少了显示数据的复杂性,并且通常是最有信号量的。最右边的 [merged] 堆栈是所有太小而无法显示的对象的总和。
- Size: 通过此路径保留到 GC 根的字节数。
- Objects: 通过此路径保留到 GC 根的对象数。
如果我们只想看到包含某些字符串的帧的调用栈,我们可以使用 Focus 功能。如果我们想知道与通知有关的所有分配,我们可以在 Focus 框中放入 "notification"。
与 native heap profile 一样,如果我们想专注于图的某些特定方面,我们可以按类名进行过滤。如果我们想查看可能由通知引起的所有内容,我们可以在 Focus 框中放入 "notification"。
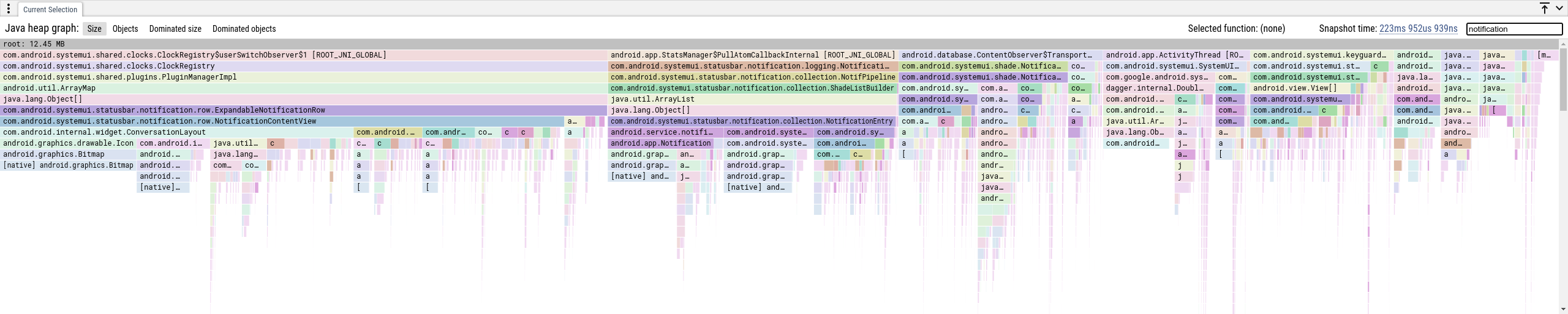
我们按类名聚合路径,因此如果有多个相同类型的对象被 java.lang.Object[] 保留,我们将显示一个元素作为其子级,正如你可以在上面的最左侧堆栈中看到的那样。这也适用于下面描述的支配树路径。
"Dominated Size" 和 "Dominated Objects" 选项卡
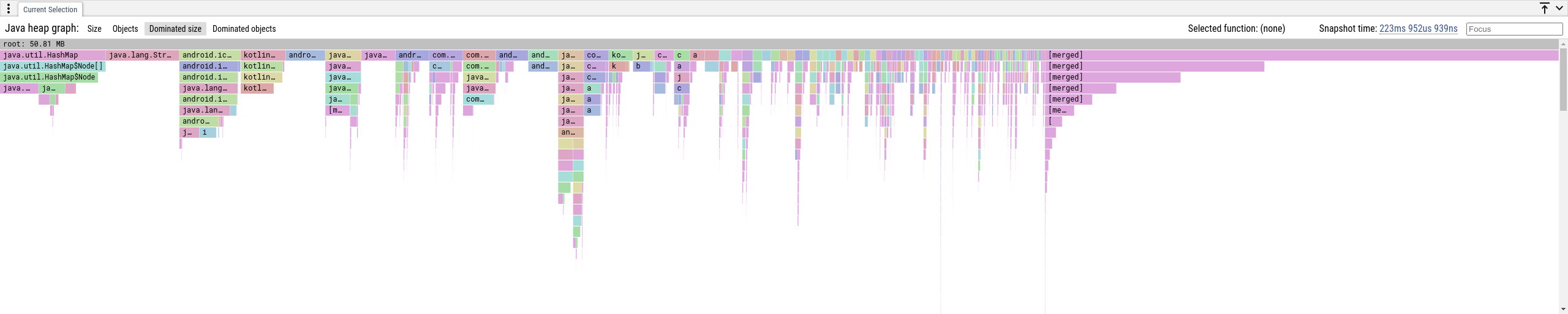
将堆图呈现为火焰图(树)的另一种方法是显示其 支配树。在堆图中,如果 b 只能通过通过 a 的路径从根到达,则对象 a 支配对象 b。对象的支配者形成从根到对象的链,并且对象被此链上的所有对象独占地保留。对于图中所有可到达的对象,这些链形成一棵树,即支配树。
我们按类名聚合树路径,并且每个元素(树节点)代表一组在支配树中具有相同类名和位置的对象。
- Dominated Size: 节点中的对象独占地保留的字节数。
- Dominated Objects: 节点中的对象独占地保留的对象数。