
heapprofd: Memory Profile 的采样
tomlewin, fmayer · 2021-04-14
背景
Heap profiler 将内存分配与其发生的调用堆栈相关联(示例可视化)。处理程序执行的每个分配是令人望而却步的昂贵操作,因此 Android Heap Profiler 采用采样方法来处理统计上有意义的分配子集。本文档探讨其统计属性。
{kind=link}
概念动机
从概念上讲,采样是这样实现的:每个字节都有一些概率 p 被采样。理论上我们可以认为每个字节都经过伯努利试验。我们使用随机采样方法而不是每隔 n 个字节取一个字节的原因是代码中可能存在规律的分配模式,可能会被相应的规律采样所遗漏。
为了将采样字节缩放到正确的比例,我们乘以 1 / p,即如果我们以 10% 的概率采样一个字节,则每个采样的字节代表 10 个分配的字节。
实现
在实践中,算法如下工作:
我们查看一个分配
如果分配的大小足够大,使其有 >99% 的机会至少被采样一次,我们直接返回分配的大小。这是一个性能优化。
如果分配的大小较小,我们计算如果我们以给定的采样率对每个字节进行采样,我们将绘制多少次采样:
在实践中,我们通过跟踪下一个采样的到达时间来做到这一点。当分配发生时,我们从下一个采样的到达时间减去其大小,并检查我们是否将其降至零以下。然后我们重复从指数分布绘制(这是泊松的到达时间),直到到达时间被带回 0 以上。我们必须从指数分布绘制的次数就是分配应该计为的采样数。
我们将分配内绘制的采样数乘以采样率,以获得分配大小的估计
我们而是直接从泊松/二项分布绘制,以查看我们为给定分配大小获得多少采样,但这在计算上不那么高效。这是因为由于它们的小尺寸和我们的低采样率,我们不采样大多数分配。这意味着使用指数绘制方法更高效,因为对于非采样,我们只需要递减 Counter。为每个分配从泊松采样(而不是为每个采样从指数绘制)更昂贵。
理论性能
如果我们以某个速率 1 / p 采样,那么要合理设置 p,我们需要知道采样任何大小的分配的概率是多少,以及采样它时的预期误差。如果我们设置 p = 1,则我们采样所有内容并且没有误差。降低采样率会损失覆盖率和准确性。
采样概率
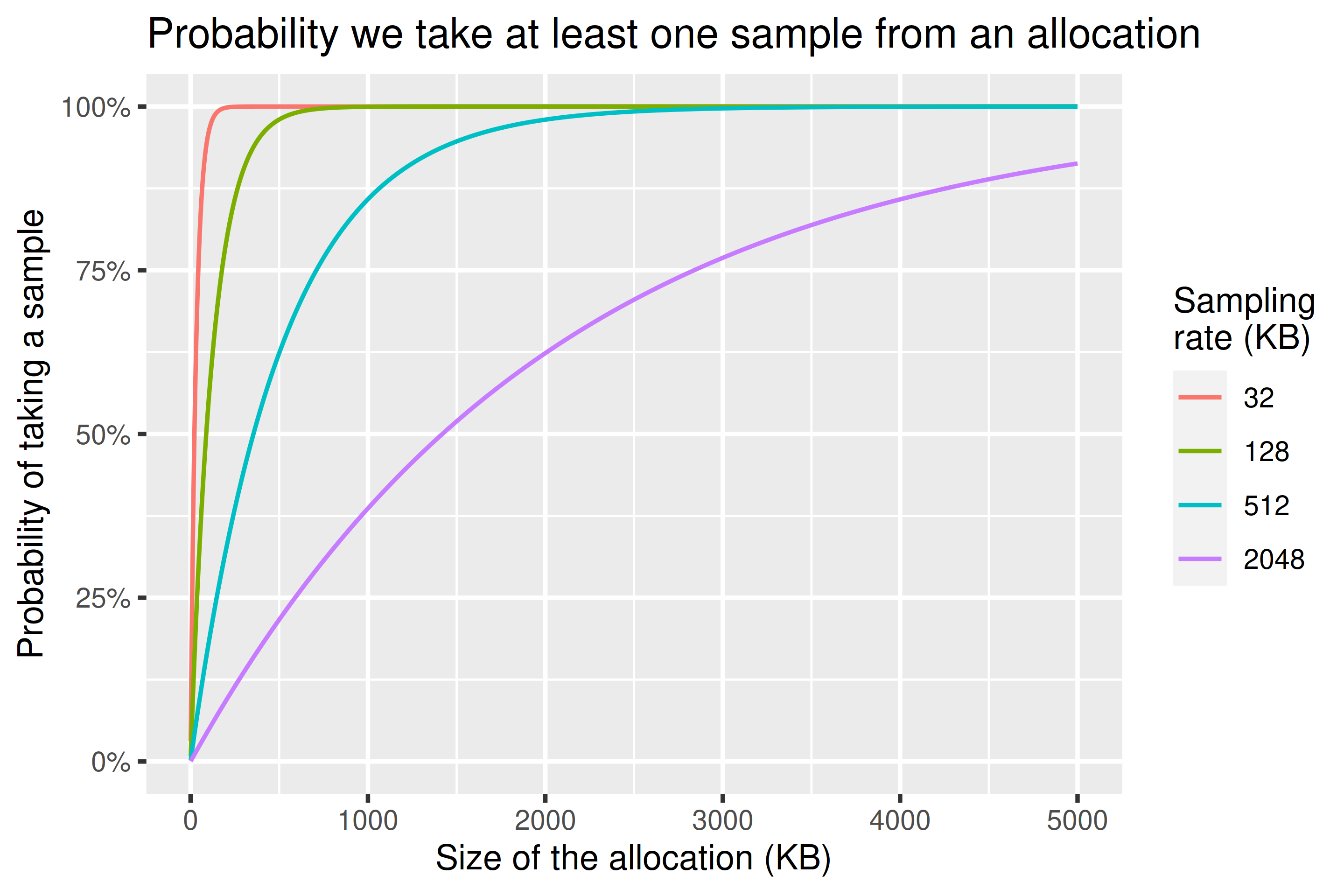
我们将以指数概率(采样率)< 分配大小采样分配。这等价于如果我们以我们的采样率对字节进行采样,我们没有未能采样分配中所有字节的概率。
因为指数分布是无记忆的,我们可以将相同的分配加在一起,即使它们在不同时间发生,用于概率目的。这意味着如果我们有 1MB 的分配,然后是另一个 1MB,我们至少采样的概率与对连续的 2MB 分配至少采样的概率相同。
我们可以从下图中看到,如果我们将采样率从 32KiB 增加 16 倍到 512KiB,我们仍然有 95% 的机会采样 1.5MiB 以上的任何内容。如果我们 64 倍增加到 2048KiB,我们仍然有 80% 的机会采样 3.5MiB 以上的任何内容。
预期误差
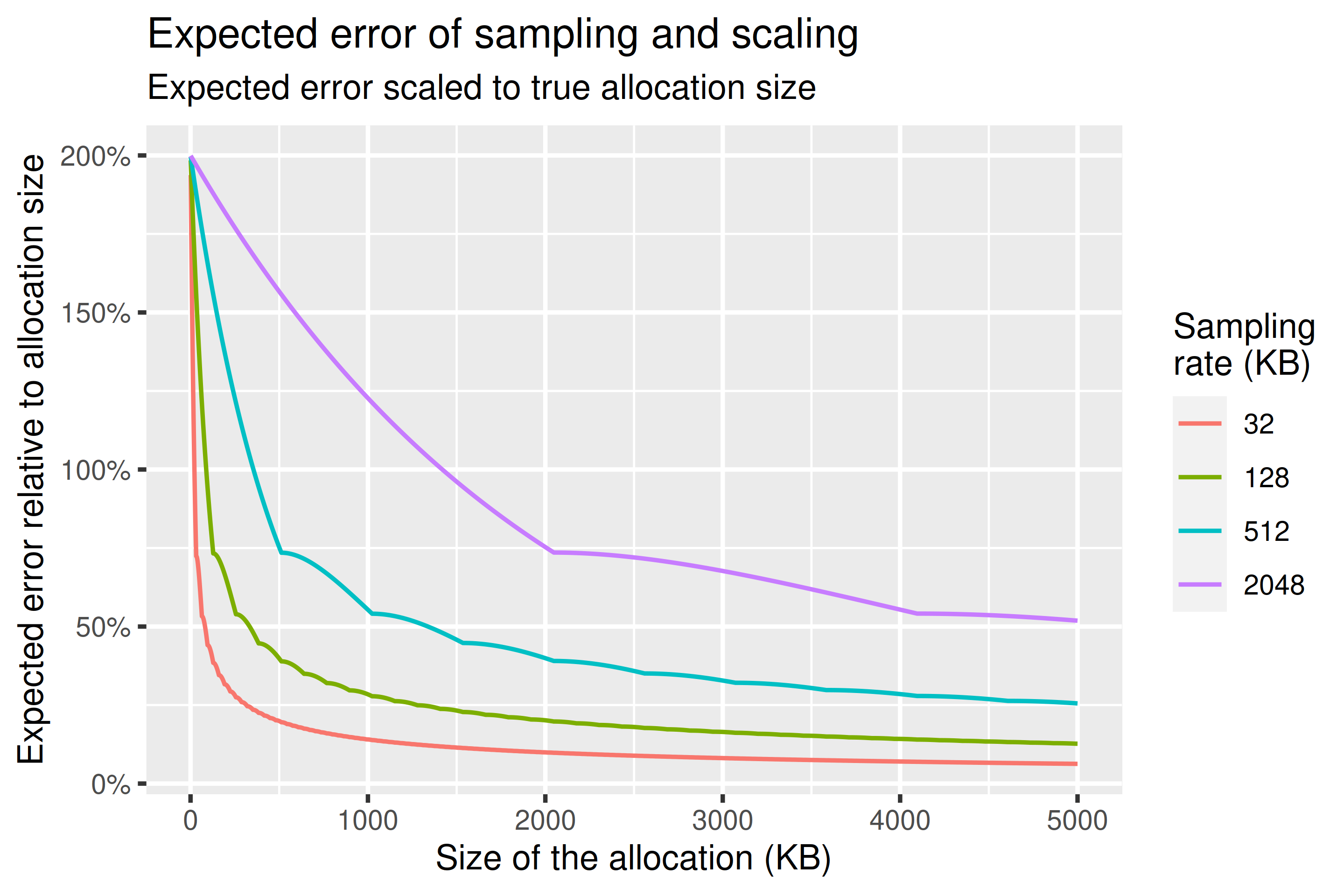
我们还可以考虑在给定分配大小和采样率下我们将产生的预期误差。与以前一样,分配发生在哪里并不重要——如果我们在不同时间有两个相同类型的分配,它们具有与大小等于其总和的单个分配相同的统计属性。这是因为我们使用的指数分布是无记忆的。
对于预期误差,我们报告类似 平均绝对百分比误差 的内容。这只是意味着我们查看相对于真实分配大小我们可能错了多少百分比,然后根据它们的发生概率缩放这些结果。这是一个有一些问题的估计器(即它是有偏差的,使得低估受到更多惩罚),但很容易推理,并且作为我们对平均错误程度的衡量是有用的。我建议只需将其读作类似于标准差。
下图显示了预期误差和条件预期误差:假设我们在分配中至少有一个采样的预期误差。两者都有与所使用的采样率一致的周期性。要点是,虽然估计是无偏的,因此它们的预期值等于它们的真实值,但仍然可能出现重大误差。
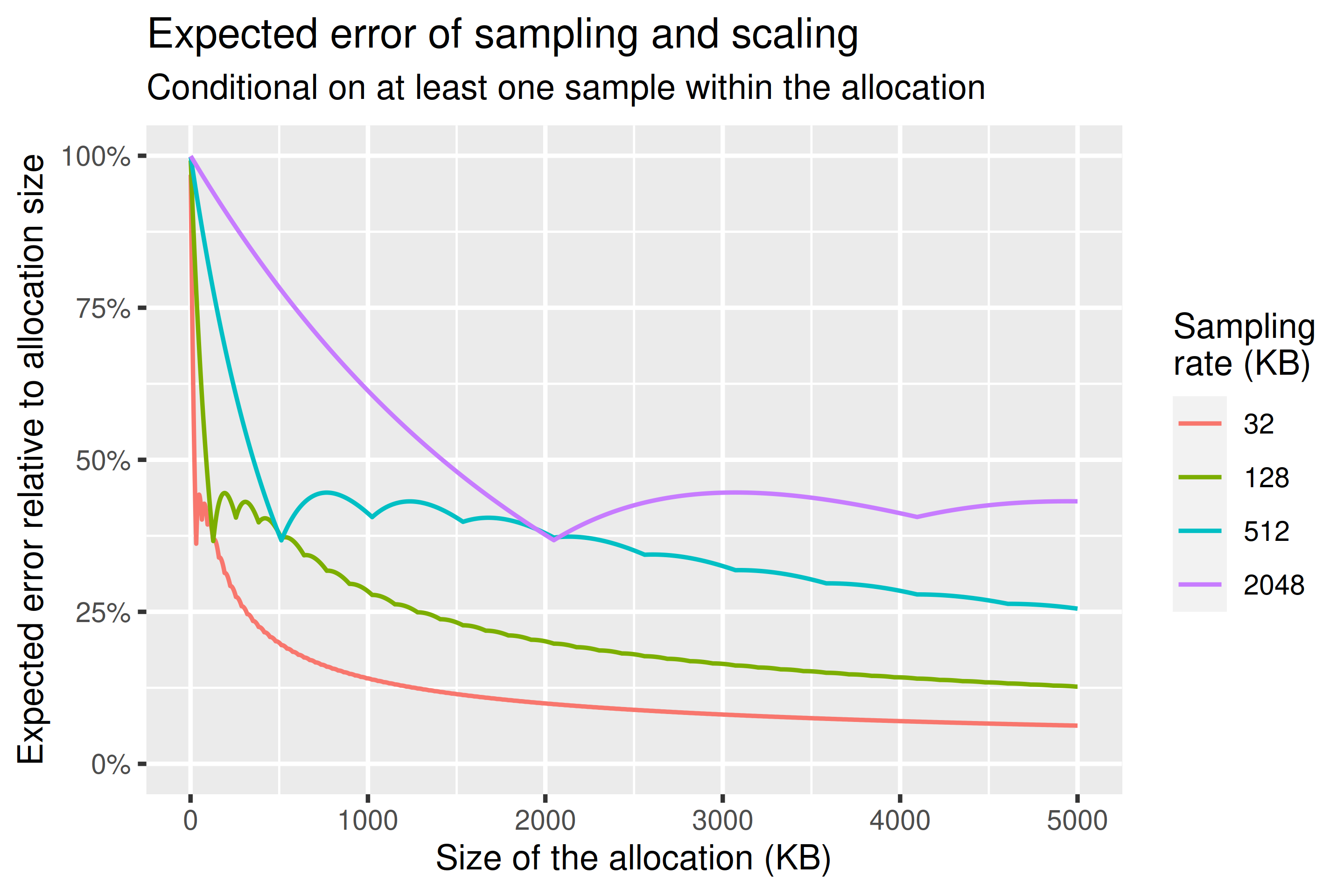
假设我们至少对分配进行一次采样,我们可能会产生什么误差?我们可以使用下图回答这个问题,该图显示了在至少进行一次采样的条件下的预期误差。这是我们最终会在 heap profile 中看到的事物的预期误差。重要的是要强调,这种预期误差方法并不精确,而且底层采样仍然是无偏的——预期值是真实值。这应该更多地被视为类似于标准差的度量。
性能考虑
STL 分布
在 Pixel 4 上对 STL 分布的基准测试强化了我们使用指数分布估计几何分布的方法,因为其性能提高了约 8 倍(完整结果)。
以 p = 1 / 32000 从指数分布绘制采样:
ARM64: 21.3ns(sd 0.066ns,可忽略不计,小于 CPU 周期)
ARM32: 33.2ns(sd 0.011ns,可忽略不计,小于 CPU 周期)
以 p = 1 / 32000 从几何分布绘制采样:
ARM64: 169ns(sd 0.023ns,可忽略不计,小于 CPU 周期)(7.93x)
ARM32: 222ns(sd 0.118ns,可忽略不计,小于 CPU 周期)(6.69x)
附录
所做的改进
我们以前(在 Android 12 之前)如果分配大小大于我们的采样率,则准确且立即返回分配大小。这有几个影响。
最明显的影响是,使用旧方法,我们预期在大约 63% 的时间内采样一个等于我们采样率大小的分配,而不是 100%。这意味着在比我们的采样率小一个字节的分配和大一个字节的分配之间存在覆盖范围的不连续性。从统计角度来看,这仍然是无偏的,但重要的是要注意。
另一个不寻常的影响是,采样率不仅取决于正在使用的内存大小,还取决于它的分配方式。如果我们的采样率是 10KB,并且我们有一个 10KB 的分配,我们会确定地采样它。相反,如果这 10KB 分配在两个 5KB 的分配之间,我们以 63% 的概率采样它。同样,这不会使我们的结果产生偏差,但这意味着我们的有许多小分配的内存测量值可能比有一些大分配的内存测量值更嘈杂,即使使用的总内存相同。如果我们不每次都返回大于采样率的分配,那么指数分布的无记忆性将意味着我们的方法对内存在分配之间如何分割不敏感,这似乎是一个理想的属性。
我们更改了简单返回分配大小的截止点。以前,如上所述,截止点在采样率,这导致不连续。现在,截止点由给定我们使用的采样率,我们有 >99% 的机会至少采样一次分配的大小确定。这解决了上述问题。