使用 Tracing 和 callstack 采样调试调度阻塞
在本指南中,你将学习如何:
- 捕获组合的调度和 callstack 采样 traces。
- 基于调度事件执行精确的 callstack 采样,而不是基于时间/随机采样。
- 使用数据推断锁争用、优先级反转和其他调度阻塞问题。
我们要解决的问题
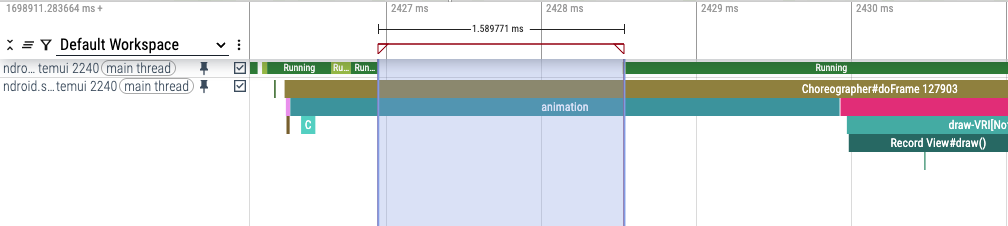
一个 bug 导致 Android SystemUI 主线程在下拉通知栏时阻塞 1-10 毫秒,导致通知栏动画偶尔卡顿。这个 bug 相当可重现。
在 trace 中,bug 表现为 Android 的 systemui 主线程在动画中间被阻塞(即被取消调度),如下所示:
剧透:根本原因
我们使用 Perfetto 中在 sched_switch + sched_waking 上触发的调用栈采样来找到根本原因。这恰好在线程在尝试获取已被持有的锁时挂起或在释放锁后唤醒等待者的时刻提供调用栈。
实际问题如下:
- Android 的 SystemUI 使用 Kotlin coroutines。
- 在内部,Kotlin coroutines 依赖于 ScheduledThreadPoolExecutor。
- SystemUI 的主线程正在尝试调度低优先级 coroutines。
- 在内部,这转换为使用后台线程池将未来任务追加到任务队列。
- 在 ScheduledThreadPoolExecutor 中排队任务需要 ReentrantLock。
- 后台线程也需要相同的锁来从队列中提取任务。
- ReentrantLock 不感知等待者的优先级。释放锁时,它会按 lock() 调用的顺序一次唤醒一个等待者线程。
- SystemUI 中有许多后台优先级 coroutines,因此该锁频繁被 BG 线程争用。
- ReentrantLock 也不是 CPU 感知的,并且可能在 unlock() 后唤醒等待者时在同一个核心上序列化 CPU 亲和线程。
- 这导致一种形式的优先级反转,主线程最终在能够获取锁之前等待一长串后台线程。
方法论
如果你想直接跳转到 trace 配置,请参阅 附录:使用的最终 trace 配置。
相反,如果你想了解我们的调试旅程以及我们是如何到达该配置的,请继续阅读。
我们的旅程始于一位同事询问我们是否可以以 10KHz 或更高的频率记录 callstack 样本。答案是一概的 _"忘掉它"_:由于 Android 上 callstack 采样的工作方式,这根本无法实现。(需要解压缩调试部分;异步展开,内核为每个样本将原始栈复制到 perf_event 缓冲区;基于 DWARF 的展开)。
当我们问 "为什么你需要高频率采样?" 时,讨论变得有趣了。 我们的同事告诉我们这个 bug: _"我想知道主线程在哪里阻塞和恢复执行。如果样本足够频繁,也许我就能用罪魁祸首获得正确的调用栈"_。
不幸的是,即使是最有性能意识的工程师也经常混淆 "callstack 采样" 与 随机采样 或 _基于时间(或基于指令/周期)的采样_,忘记了 callstack 采样是更强大的机器。
虽然随机采样无疑是 callstack 采样最流行的形式之一,但这种方法更有助于回答形式为 "函数在哪里花费 CPU 周期?" 或 "我能做些什么来减少任务的 CPU 使用?" 的问题。这些都不适用于此。
Linux - 以及许多其他操作系统 - 上的 callstack 采样要强大得多。简单来说,你可以将 callstack 采样视为 _"每次特定事件发生 N 次时抓取一个调用栈"_(另请参阅此 easyperf.net 博客文章。
有趣的部分是 _哪个特定事件_。通常这可以是:
- 定时器溢出,以实现 "每 X ms 抓取一个调用栈"。
- PMU Counters 溢出,例如以实现 "每 N 条指令退役 / M 次缓存未命中抓取一个调用栈"。
/sys/kernel/tracing/event/**/*中可用的任何内核跟踪点。
后者是可以将 callstack 采样变成实用的瑞士军刀的有趣选项。现在,内核中定义了大量跟踪点,但其中两个在这里特别有趣:
sched_switch:每次发生上下文切换时都会触发这种情况。有趣的情况是当你尝试获取锁 → 锁被持有 → 你要求内核将线程放在等待链上 → 内核将你调度出去时。 在内部,这通常最终导致sys_futex(FUTEX_WAIT, ...)。 这很重要,因为这是我们关心的线程阻塞的时刻。sched_waking:每当一个线程使另一个线程有资格再次被调度时触发。注意,"有资格被调度" != "现在被调度"。线程可以在被唤醒后许多毫秒被放在运行队列(即调度)上。在此期间可能会调度其他线程。 这很重要,因为这是另一个线程最终唤醒(解除阻塞)我们线程的时刻。
所以整体游戏如下:如果你可以看到你的线程在哪里被阻塞的调用栈,以及另一个线程在哪里解除阻塞你线程的调用栈,这两个调用栈通常通过代码搜索提供足够的信息来弄清楚其他所有内容。
这种技术并不是特别新颖,也不是 Linux 特有的。如果你想阅读更详细的文章,请查看 Bruce Dawson 的 The Lost Xperf Documentation–CPU Usage (Precise),它在 Windows 上详细解释了这个用例(这些原则大多也适用于 Linux)。
我们的第一次失败尝试
起初我们过于兴奋,编写了一个在每个 sched_switch 和每个 sched_waking 上抓取调用栈的配置。提供的配置仅供参考(不要使用它)以及一些有用的注释。
linux.perf 是在 Perfetto 中执行 callstack 采样的数据源(相当于 Linux 的 perf 或 Android 的 simpleperf 命令行工具)。
你会注意到有两个数据源实例。为什么? 这反映了 perf_event_open syscall 在底层的工作方式:如果你想要在 某事 上的调用栈,那么 某事 必须是 leader Counter。 在我们的实现中,每个 perf 数据源映射到一个 leader Counter,具有自己的 perf 缓冲区。
所以我们有一个 sched_switch 的数据源,一个 sched_waking 的数据源,这是我们追求的两个跟踪点。
period:1 意味着 "采样每个事件"。我们真的不想在这里做任何采样。我们不是在寻找通用的聚合火焰图。
我们想要捕获一个非常特定的一组调用栈,用于每帧精确发生一次的事件。不采样,谢谢。
ring_buffer_pages: 2048 使用了比平时大的 perf 事件环形缓冲区。这是内核排队所有样本的缓冲区,我们的 traced_perf 守护进程读取它们。
更大的缓冲区提供了更多处理突发的能力。
大小以页面为单位,所以 2048 * 4KB -> 8MB。
不幸的是,更高的值似乎会失败,因为内核无法找到连续的 mlockable 内存区域。
# *** 不要使用此配置 ***
# 这会 overrun 调用栈采样器(见注释)。
# 附录中有改进的配置。
# 第 1 部分
data_sources {
config {
name: "linux.perf"
perf_event_config {
timebase {
period: 1
tracepoint {
name: "sched/sched_switch"
}
timestamp_clock: PERF_CLOCK_MONOTONIC
}
callstack_sampling {
kernel_frames: true
}
ring_buffer_pages: 2048 # 8MB
}
}
}
# 第 2 部分
data_sources {
config {
name: "linux.perf"
perf_event_config {
timebase {
period: 1
tracepoint {
name: "sched/sched_waking"
}
timestamp_clock: PERF_CLOCK_MONOTONIC
}
callstack_sampling {
kernel_frames: true
}
ring_buffer_pages: 2048 # 8MB
}
}
}不幸的是,这种方法理论上听起来不错,但导致了灾难性的失败。
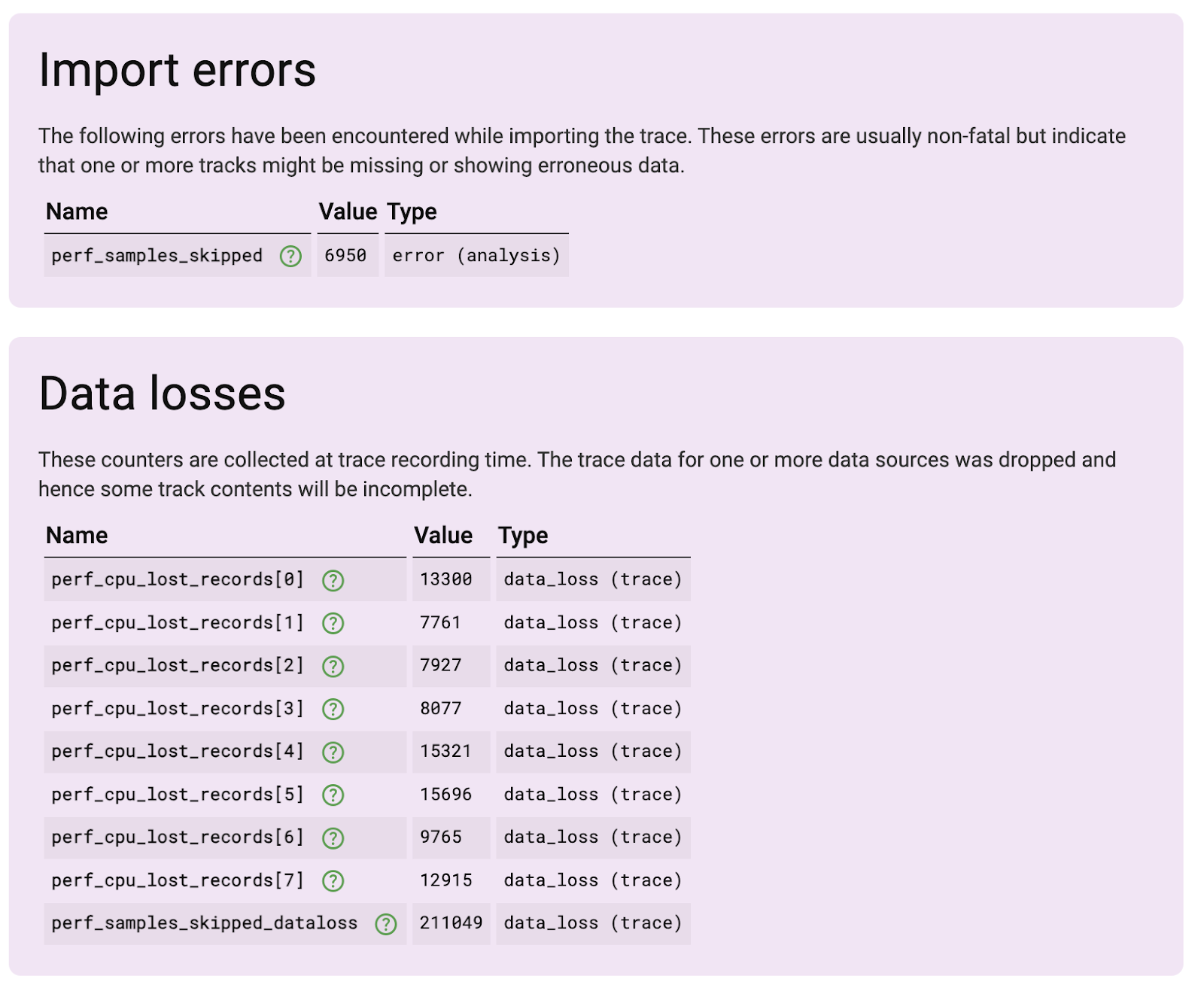
在每个 sched_switch 上采样太多了。在一个屏幕打开的空闲手机上,平均每秒有 ~20K 调度事件,开始触摸屏幕时爆发远超该速率。内核和 traced_perf 都无法跟上该速率。
跟踪点过滤器来救援
毕竟,我们不需要系统中每个调度活动的调用栈。我们真正关心的是 SystemUI 的主线程,以及任何其他参与其阻塞的线程。
所以在我们的下一次迭代中,我们通过仅过滤 SystemUI 线程来平息调用栈采样器,如下所示。
"filter" 操作符一直传递到内核,它在跟踪点级别进行过滤(即在发出调用栈样本之前)
需要注意几点:
- 每个 sched_switch 事件有两个线程名称(称为 "comm"):被调度的线程(
prev_comm)和被调度的新线程(next_comm)。 我们想要捕获我们调度进或调度出 SystemUI 主线程的所有实例。 - 相反,sched_waking 只有被唤醒线程的 "comm"。
所以我们更新配置如下:
...
tracepoint {
name: "sched/sched_switch"
filter: "prev_comm ~ \"*systemui*\" || next_comm ~ \"*systemui*\"
}
...
tracepoint {
name: "sched/sched_waking"
filter: "comm ~ \"*systemui*\"
}
...采集 overrun 消失了,我们得到了一个更有用的 trace。现在 trace 中的每个线程都有三个 track:
- 一个具有线程调度状态(Running、Runnable 等)
- 一个具有常用的 tracing slice (Choreographer#doFrame、Animation)
- 一个新的带有调用栈(彩色 V 形)。每个 V 形对应一个样本。如果你点击它,你可以看到调用栈。
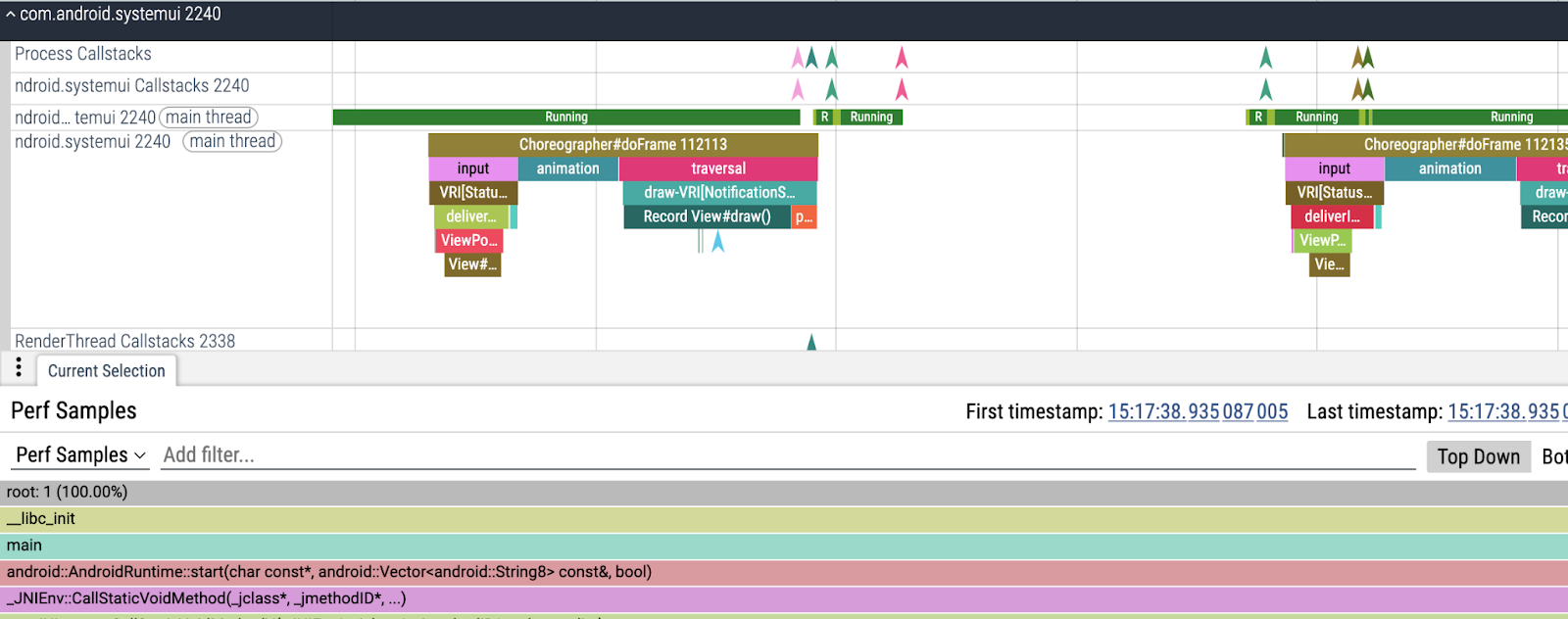
现在我们可以放大我们正在寻找的主线程阻塞,并最终找到我们被阻塞的位置。
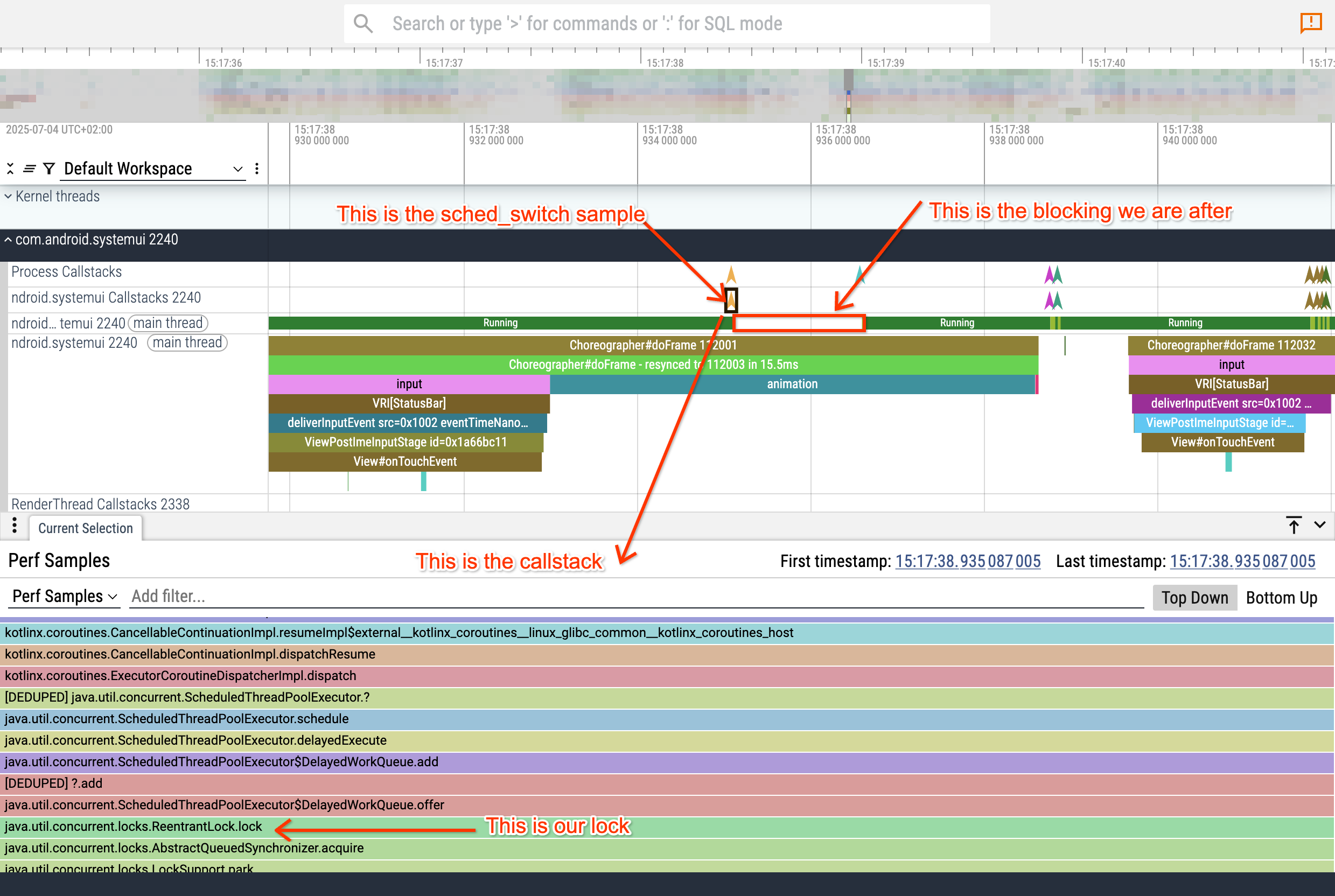
我们得到了第一条情报:sysui 的主线程在尝试将未来任务发布到 ScheduledThreadPoolExecutor 的任务队列时在互斥锁上被阻塞。
这里有几个问题:
- 为什么发布任务需要锁(这更多是一个离题的 Kotlin coroutine 架构设计问题)
- 为什么这个锁被持有 1.5ms?
- 谁持有这个锁?
为了回答这个问题,让我们反向 trace 事件。在神秘阻塞点之后点击主线程的 Running Slice 并查看 "woken by"。这表示唤醒我们的线程。
点击它,我们将看到我们被一个 BG 线程唤醒。
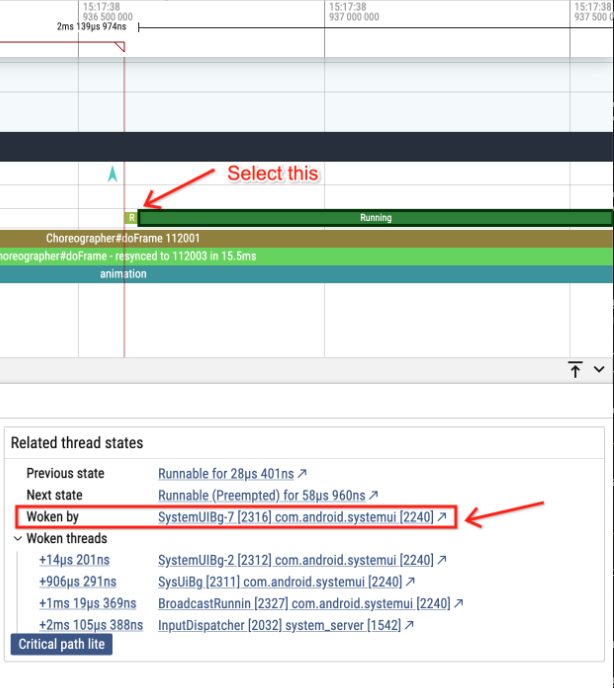
点击该链接会带我们到唤醒线程的 Timeline。但在这里魔法发生了。因为我们在 sched_waking 上也启用了栈采样,现在我们的唤醒者也有一个调用栈。
选择 V 形将向我们展示导致唤醒的调用栈:
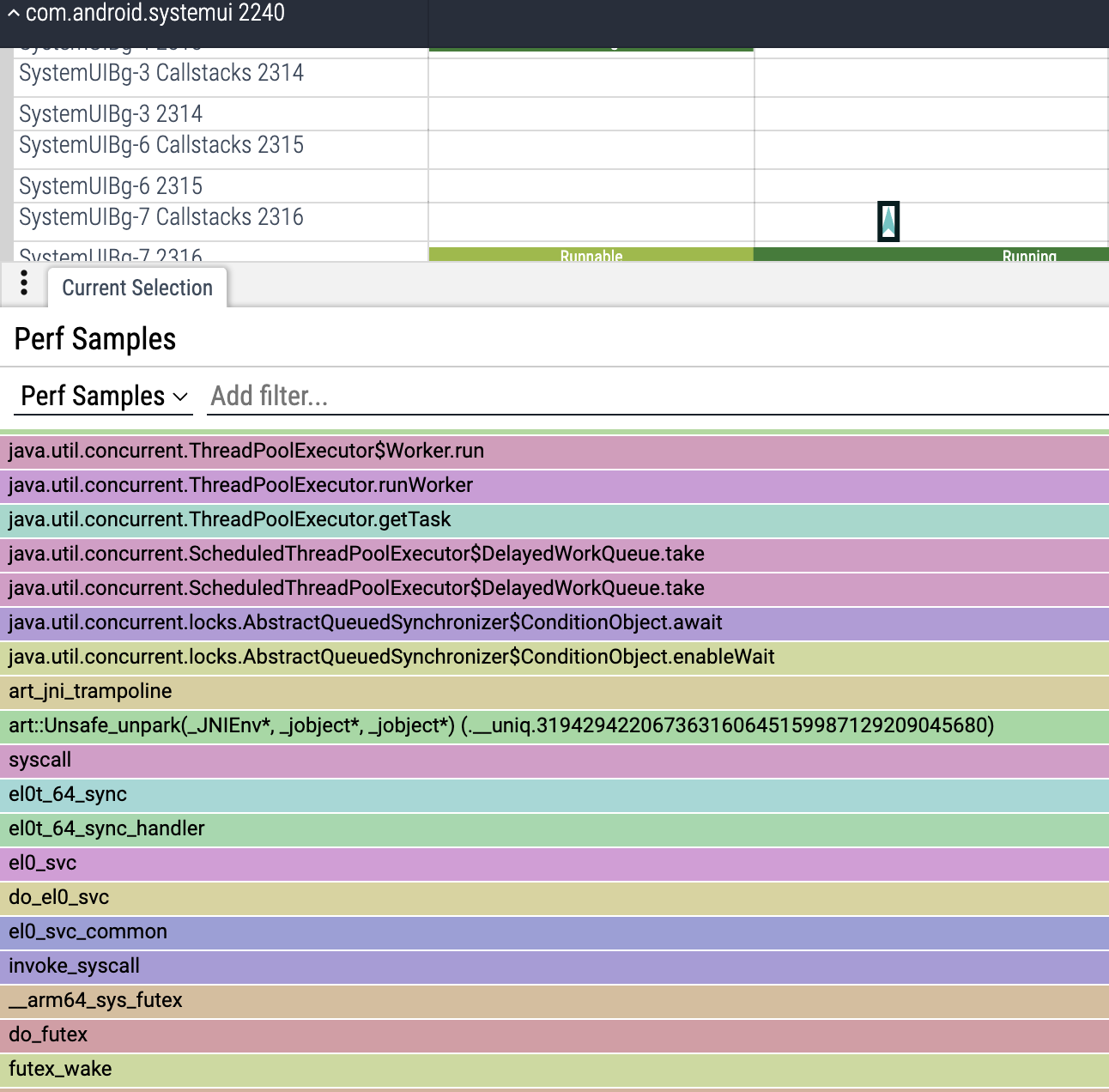
我们在这里看到的是,后台任务的执行获取锁,从队列中获取任务,然后释放锁。
释放锁的行为最终唤醒主线程。但这还不是我们要寻找的完整答案。我们最终让这个随机 BG 线程拥有锁是怎么回事?这个线程只运行了一个 160 us 的微小任务。但主线程的整个阻塞时间是 1.5 ms,是 10 倍。同时发生了什么?
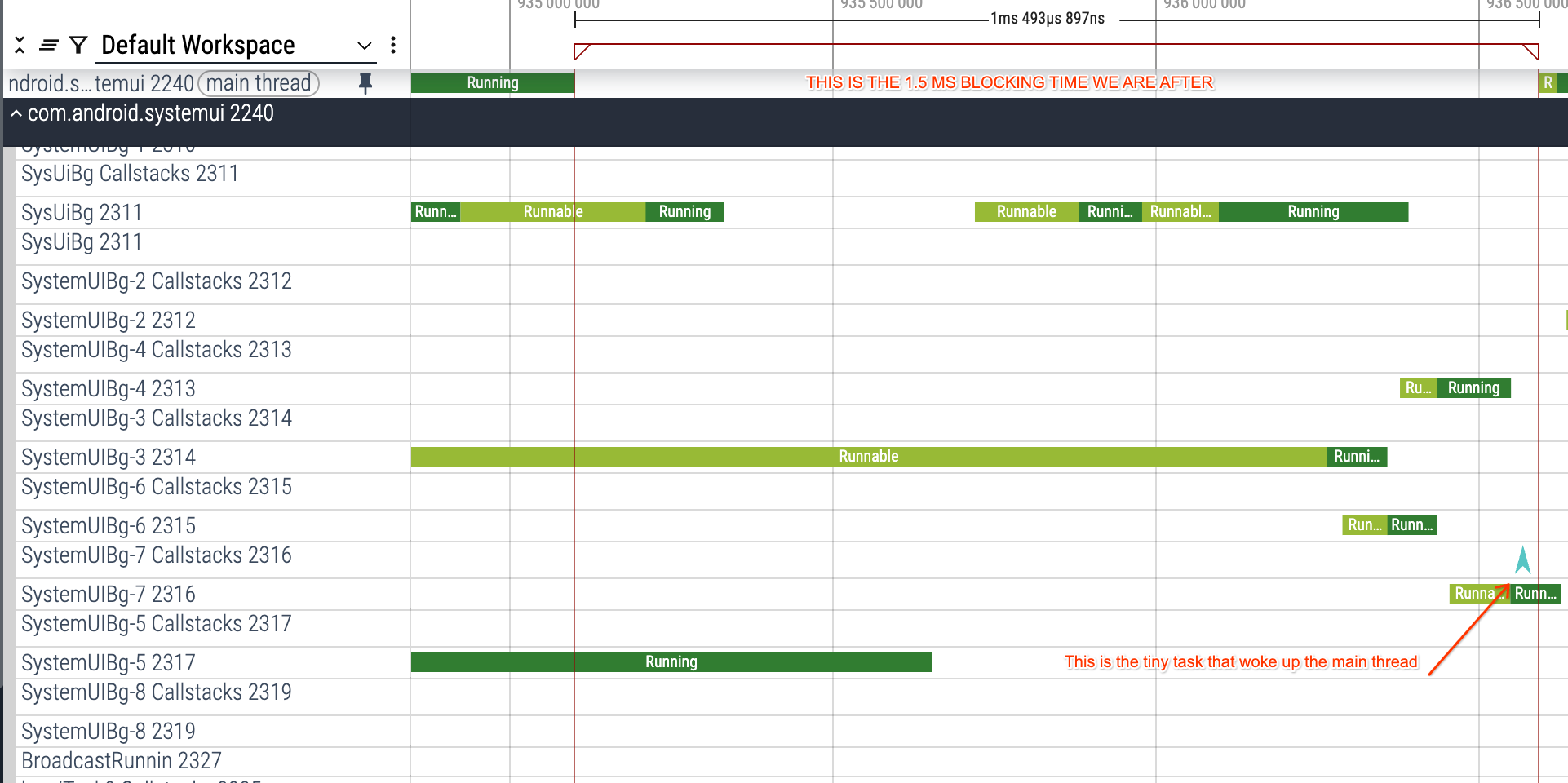
我们可以使用 "Critical path lite" 按钮查看导致主线程状态更改的线程列表,而不必手动跟踪线程状态 track 中的各种 "Woken by" 标签:
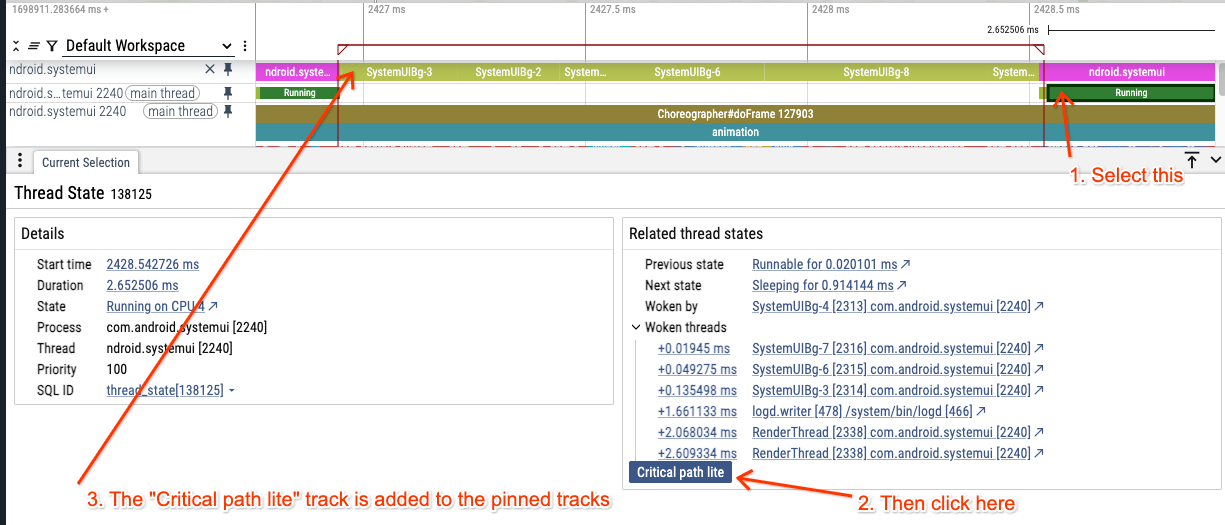
现在这里有一些可疑的地方,让我们回顾一下:
- 主线程被阻塞 1.5 ms
- 我们在 ScheduledThreadPoolExecutor 锁上被阻塞
- 唤醒我们的线程非常短(150us)
- 剩余的 1.35 ms 发生了什么?
- 大约在同一时间还有一堆其他 BG 线程活动
- 在这一点上我们怀疑这是一种优先级反转(在优先级反转的更一般和宽松意义上)。

这是正在发生的事情:
- 主线程正在尝试获取锁。
- 锁被一个 bg 线程持有(到目前为止,这很正常)。
- 同时其他 BG 线程正在尝试获取锁,并加入锁的等待者列表。
- 当 BG 线程完成时,另一个 BG 线程赢得竞争,而不是主线程,主线程具有更高的调度优先级。
不幸的是,我们还看不到(还)BG 线程的调用栈,因为我们只过滤了 sysui 主线程(及其唤醒者)。我们将不得不再次调整配置。
重新捕获 trace
让我们稍微调整一下配置并添加 BG 线程:
tracepoint {
name: "sched/sched_switch"
filter: "prev_comm ~ \"*systemui*\" || next_comm ~ \"*systemui*\" || prev_comm ~ \"SystemUIBg-*\" || next_comm ~ \"SystemUIBg-*\""
}新的 trace 看起来像这样。你会注意到现在我们有更多的 V 形,因为我们还有 SystemUiBG* 线程的每个调度事件的调用栈。点击它们确认了我们的理论。所有这些 BG 线程都在获取和释放 ScheduledThreadPoolExecutor 锁。
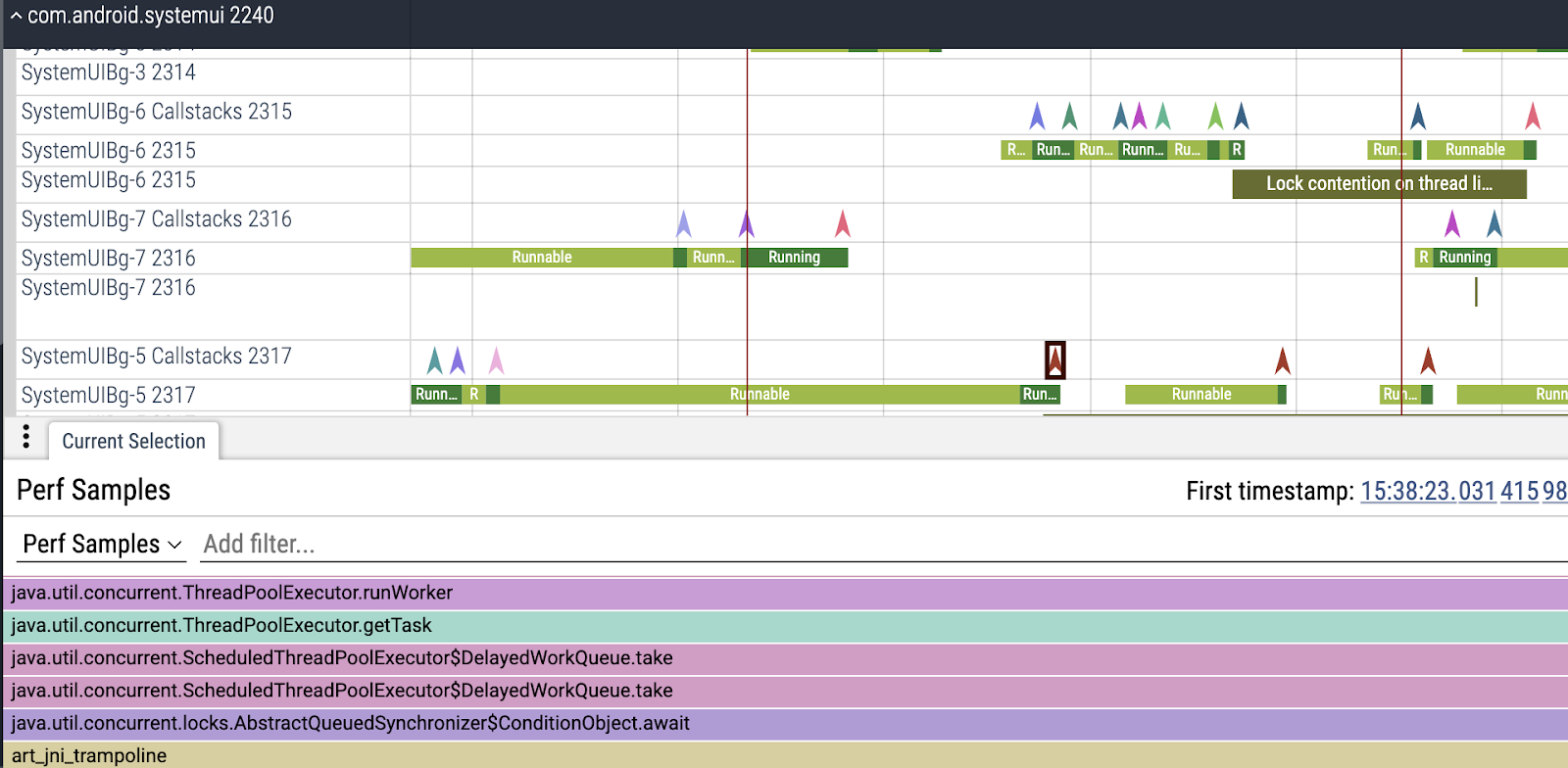
此时我们可以重建完整的事件序列。
ScheduledThreadPoolExecutor 中的每个工作线程执行以下操作:
- 获取锁
- 从队列中提取任务
- 释放锁
- 运行任务
(3) 导致唤醒另一个等待锁的线程。
不幸的是,这里有一些问题出错:
由于大量 BG coroutines,有大量 BG 线程在锁上排队,尝试提取任务。 底层的 ReentrantLock 实现将按排队顺序通知它们,增加主线程的阻塞时间。
ReentrantLock 实现与标准的
synchronized (x) {...}监视器不同。虽然监视器由标准内核 futex 支持,但 ReentrantLock 在 Java 中 有自己的重新实现 的等待者列表,它手动停放/取消停放线程,某种程度上遮蔽了内核会做的工作。 不幸的是,此实现不知道线程的 CPU 亲和性,并且可能在 unlock() 时在唤醒等待者时导致次优决策。 实际上,它可能取消停放一个绑定到当前相同 CPU 的线程。在使用默认的 SCHED_OTHER 策略时,Linux/Android CFS 调度程序不是 工作保守 的,并且不会积极地跨核心迁移线程以最小化调度延迟(它这样做是为了平衡功耗与延迟)。因此,被唤醒的线程最终等待当前线程完成其任务,即使锁已释放。最终结果是两个线程最终在同一 CPU 上以线性顺序执行,尽管互斥锁大部分时间已解锁。这种 BG 工作负载的序列化进一步放大了主线程的阻塞时间。你可能会注意到上面的截图中 SystemUIBg-* 线程缺乏真正的并行化。
附录:使用的最终 trace 配置
duration_ms: 10000
buffers: {
size_kb: 102400
fill_policy: DISCARD
}
data_sources {
config {
name: "linux.perf"
perf_event_config {
timebase {
period: 1
tracepoint {
name: "sched/sched_switch"
filter: "prev_comm ~ \"*systemui*\" || next_comm ~ \"*systemui*\" || prev_comm ~ \"SystemUIBg-*\" || next_comm ~ \"SystemUIBg-*\""
}
timestamp_clock: PERF_CLOCK_MONOTONIC
}
callstack_sampling {
kernel_frames: true
}
ring_buffer_pages: 2048
}
}
}
data_sources {
config {
name: "linux.perf"
perf_event_config {
timebase {
period: 1
tracepoint {
name: "sched/sched_waking"
filter: "comm ~ \"*systemui*\" || comm ~ \"SystemUIBg-*\""
}
timestamp_clock: PERF_CLOCK_MONOTONIC
}
callstack_sampling {
kernel_frames: true
}
ring_buffer_pages: 2048
}
}
}
# 通过 ftrace 包含调度数据
data_sources: {
config: {
name: "linux.ftrace"
ftrace_config: {
ftrace_events: "sched/sched_switch"
ftrace_events: "sched/sched_waking"
atrace_categories: "dalvik"
atrace_categories: "gfx"
atrace_categories: "view"
}
}
}
# 通过 procfs 包含进程名称和分组
data_sources: {
config: {
name: "linux.process_stats"
process_stats_config {
scan_all_processes_on_start: true
}
}
}附录:添加 syscall tracing
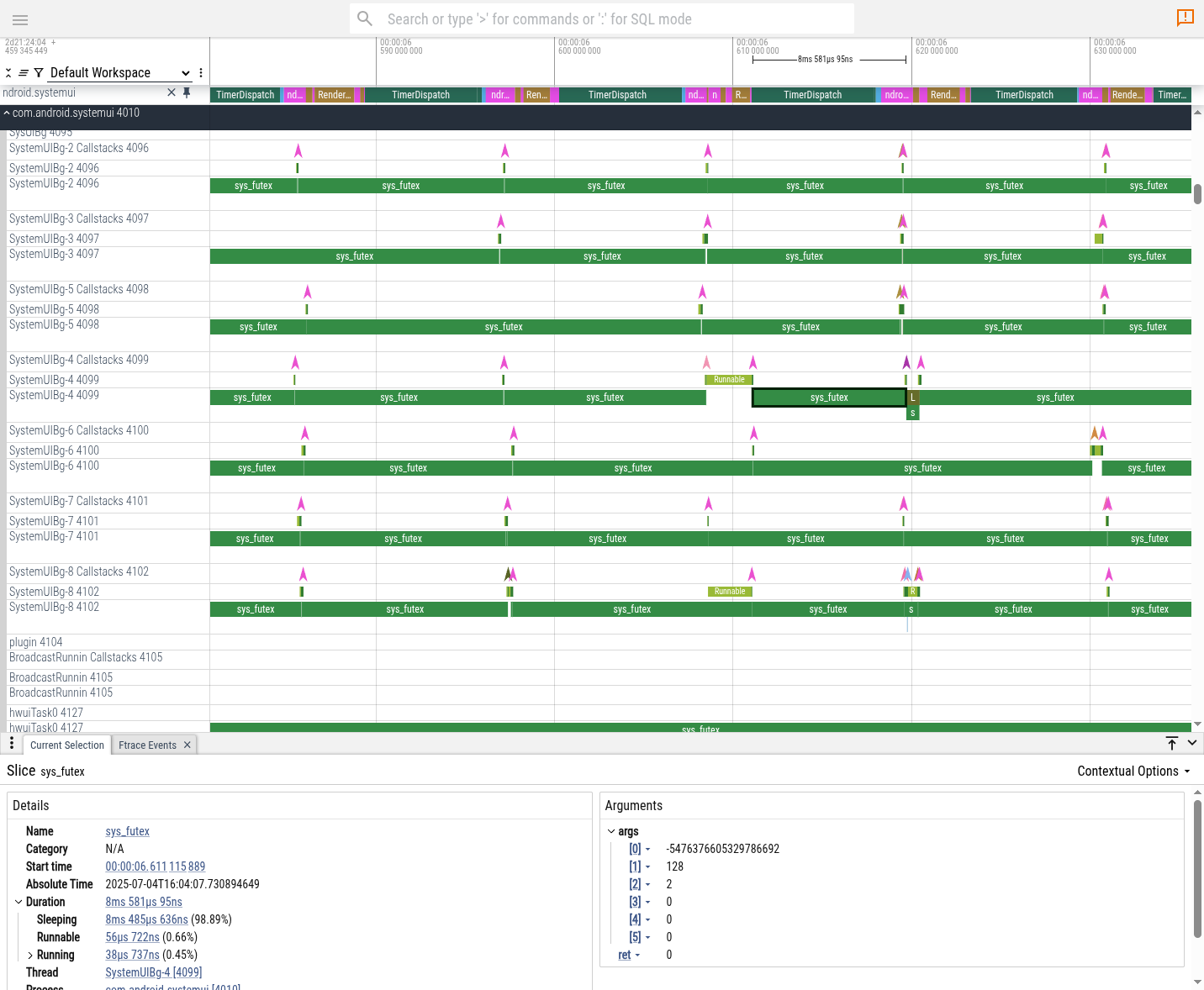
作为进一步的说明,事后看来,trace 可以通过 syscall tracing 增强,添加 sys_futex 调用的插桩。
这只是将以下行添加到 ftrace 配置的问题:syscall_events: "sys_futex" 如下:
data_sources: {
config: {
name: "linux.ftrace"
ftrace_config: {
syscall_events: "sys_futex"
ftrace_events: "sched/sched_switch"
ftrace_events: "sched/sched_waking"
atrace_categories: "dalvik"
atrace_categories: "gfx"
atrace_categories: "view"
}
}
}生成的 trace 看起来像这样: