
GPU
Perfetto 支持在多种使用场景下 Tracing GPU 活动,从 Android 移动端图形处理到高端多 GPU 计算负载。
数据源
以下数据源可用于 GPU Tracing:
| 数据源 | 配置 | 用途 |
|---|---|---|
gpu.counters |
gpu_counter_config.proto | 周期性或插桩式 GPU Counter 采样 |
gpu.renderstages |
gpu_renderstages_config.proto | GPU 渲染阶段和计算活动时间线 |
vulkan.memory_tracker |
vulkan_memory_config.proto | Vulkan 内存分配和绑定 Tracing |
gpu.log |
(无) | GPU 调试日志消息 |
linux.ftrace |
ftrace_config.proto | GPU 频率、内存总量、DRM 调度器事件 |
GPU 生产者通常会使用硬件特定的后缀注册数据源,例如 gpu.counters.adreno 或 gpu.renderstages.mali。Tracing 服务使用精确名称匹配,因此 trace 配置必须使用相同的带后缀名称。Trace Processor 根据 proto 字段类型解析 GPU 数据,因此所有带后缀的变体都会被相同处理。当针对特定 GPU 厂商的生产者时,请在 trace 配置中使用带后缀的名称:
data_sources: {
config {
name: "gpu.counters"
gpu_counter_config {
counter_period_ns: 1000000
counter_ids: 1
}
}
}Trace 包含 gpu_id 字段用于区分不同的 GPU,以及 machine_id 字段用于在多机环境中区分不同的机器。GPU 硬件元数据(名称、厂商、架构、UUID、PCI BDF)通过 GpuInfo trace packet 记录。
Android
GPU 频率
GPU 频率通过 ftrace 收集:
data_sources: {
config {
name: "linux.ftrace"
ftrace_config {
ftrace_events: "power/gpu_frequency"
}
}
}GPU Counter
Android GPU 生产者必须使用 Counter 描述符模式 1:GpuCounterDescriptor 直接嵌入到会话的第一个 GpuCounterEvent packet 中,并且 Counter ID 是全局的。这是 CDD/CTS 合规性所要求的。
GPU Counter 通过指定设备特定的 Counter ID 进行采样。可用的 Counter ID 在数据源描述符的 GpuCounterSpec 中描述。
data_sources: {
config {
name: "gpu.counters"
gpu_counter_config {
counter_period_ns: 1000000
counter_ids: 1
counter_ids: 3
counter_ids: 106
counter_ids: 107
counter_ids: 109
}
}
}counter_period_ns 设置所需的采样间隔。
或者,可以使用 counter_names 按名称选择 Counter。选择其中一种方式,不要两者同时使用。并非所有生产者都支持此方式——请检查 DataSource 描述符中的 supports_counter_names。counter_names 中可以使用 glob 模式按名称匹配多个 Counter;请检查描述符中的 supports_counter_name_globs 是否支持。
GPU 内存
每个进程的总 GPU 内存使用量通过 ftrace 收集:
data_sources: {
config {
name: "linux.ftrace"
ftrace_config {
ftrace_events: "gpu_mem/gpu_mem_total"
}
}
}GPU 渲染阶段
渲染阶段 Tracing 提供 GPU 活动(图形和计算提交)的时间线:
data_sources: {
config {
name: "gpu.renderstages"
}
}Vulkan 内存
Vulkan 内存分配和绑定事件可以通过以下方式 Tracing:
data_sources: {
config {
name: "vulkan.memory_tracker"
vulkan_memory_config {
track_driver_memory_usage: true
track_device_memory_usage: true
}
}
}GPU 日志
GPU 调试日志消息可以通过启用该数据源来收集:
data_sources: {
config {
name: "gpu.log"
}
}高端 GPGPU
对于高性能和数据中心 GPU 负载(CUDA、OpenCL、HIP),Perfetto 支持多 GPU 和多机 Tracing,并提供插桩式 Counter 采样。
插桩式 Counter 采样
除了全局采样外,还可以通过在 GPU 命令缓冲区中插桩来采样 Counter。这提供了每次提交级别的 Counter 值:
data_sources: {
config {
name: "gpu.counters"
gpu_counter_config {
counter_ids: 1
counter_ids: 2
instrumented_sampling: true
}
}
}要更精细地控制对哪些 GPU 活动进行插桩,请使用 instrumented_sampling_config 而不是 instrumented_sampling 布尔值。这启用了一个按以下顺序应用的过滤器管道:
活动名称过滤:如果
activity_name_filters非空,则活动必须至少匹配一个过滤器。每个过滤器需要一个name_glob模式和一个可选的name_base(默认为MANGLED_KERNEL_NAME)。如果为空,所有活动通过此步骤。TX 范围过滤:如果
activity_tx_include_globs非空,则活动必须落在匹配某个包含 glob 的 TX 范围(例如 CUDA 的 NVTX 范围)内。匹配activity_tx_exclude_globs的 TX 范围中的活动被排除(排除优先于包含)。TX 范围可以嵌套,活动在其嵌套层次结构中任何范围匹配时都算匹配。如果两者都为空,所有活动通过此步骤。基于范围的采样:如果
activity_ranges非空,则仅对指定 skip/count 范围内的活动进行插桩。skip默认为 0,count默认为 UINT32_MAX(所有剩余活动)。如果为空,所有通过前述步骤的活动都被插桩。
示例配置:仅对 demangled kernel 名称匹配 "myKernel*" 且在匹配 "training*" 的 TX 范围内的活动进行插桩,跳过前 10 个匹配活动然后插桩 5 个:
data_sources: {
config {
name: "gpu.counters"
gpu_counter_config {
counter_names: "sm__cycles_elapsed.avg"
counter_names: "sm__cycles_active.avg"
instrumented_sampling_config {
activity_name_filters {
name_glob: "myKernel*"
name_base: DEMANGLED_KERNEL_NAME
}
activity_tx_include_globs: "training*"
activity_ranges {
skip: 10
count: 5
}
}
}
}
}对于 GPGPU 使用场景,推荐使用 Counter 描述符模式 2:生产者发送通过 IID 引用的 InternedGpuCounterDescriptor,为每个可信序列提供独立的局部 Counter ID。这避免了模式 1 所需的全局协调,并自然地支持多个生产者和 GPU。有关两种模式的详细信息,请参阅 gpu_counter_event.proto。
Counter 名称和 ID 由 GPU 生产者通过数据源描述符中的 GpuCounterSpec 发布。Counter 按组分类(SYSTEM、VERTICES、FRAGMENTS、PRIMITIVES、MEMORY、COMPUTE、RAY_TRACING),并包含度量单位和描述。
多 GPU
系统中的每个 GPU 都分配了一个 gpu_id。Counter 事件、渲染阶段和其他 GPU trace 数据都携带此 ID,以便 UI 可以按 GPU 对 Track 进行分组。GPU 硬件详细信息通过 GpuInfo 消息记录,包括:
name、vendor、model、architectureuuid(16 字节标识符)pci_bdf(PCI 总线/设备/功能)
多机
在跨多台机器进行 Tracing 时,每个 GPU trace 事件还携带 machine_id,用于区分该 GPU 属于哪台机器。Perfetto UI 在 GPU Track 旁显示机器标签。
渲染阶段事件关联
GPU 渲染阶段事件可以使用 GpuRenderStageEvent 上的 event_wait_ids 字段声明对其他渲染阶段事件的依赖关系。每个条目是该事件在运行前需要等待的另一个渲染阶段事件的 event_id。trace processor 使用这些信息在关联的 GPU 切片之间创建流箭头。
示例:一个依赖于先前异步 memcpy 的 matmul kernel:
gpu_render_stage_event {
event_id: 1
duration: 50000
hw_queue_iid: 1
stage_iid: 2
context: 0
name: "Memcpy HtoD"
}
gpu_render_stage_event {
event_id: 2
duration: 40000
hw_queue_iid: 3
stage_iid: 4
context: 0
name: "matmul_kernel"
event_wait_ids: 1
}这会创建一个从 memcpy 事件(event_id 1)到 matmul kernel(event_id 2)的流,在 Perfetto UI 中可视化依赖关系。
Counter 分组
Counter 分组被 Perfetto UI 用来将 Counter Track 组织成组。Counter 可以通过 GpuCounterSpec.groups 分配到内置分组(SYSTEM、VERTICES、FRAGMENTS、PRIMITIVES、MEMORY、COMPUTE、RAY_TRACING),也可以通过 GpuCounterDescriptor 中的 GpuCounterGroupSpec 消息定义自定义 Counter 分组:
Counter 的组成员关系是通过 GpuCounterSpec.groups(固定枚举)和 GpuCounterGroupSpec.counter_ids(自定义分组)分配的组的并集。
例如,使用自定义分组 "Compute Core" 和 "L2 Cache":
GPU > Counters > Compute Core > Counter A
GPU > Counters > Compute Core > Counter B
GPU > Counters > L2 Cache > Counter CHost-to-GPU 关联
Host 端的 track event 可以使用 GpuCorrelation TrackEvent 扩展与 GPU 渲染阶段事件进行关联。这对于将 host API 调用(如 cudaLaunchKernel、cudaMemcpyAsync)与对应的 GPU 工作连接起来非常有用。
该扩展提供两个字段:
render_stage_submission_event_ids:此 host event 提交的 GPU 渲染阶段事件的 event ID。render_stage_wait_event_ids:此 host event 等待其完成的 GPU 渲染阶段事件的 event ID。
示例:一个与 GPU 计算 kernel 关联的 host kernel 启动:
track_event {
type: TYPE_SLICE_BEGIN
name: "cudaLaunchKernel"
[perfetto.protos.GpuTrackEvent.gpu_correlation] {
render_stage_submission_event_ids: 1
}
}
gpu_render_stage_event {
event_id: 1
duration: 50000
hw_queue_iid: 1
stage_iid: 2
context: 0
name: "matmul_kernel"
}UI Plugin
Perfetto UI 内置了多个消费 GPU trace 数据的 Plugin。它们在标准工作区树的 GPU 组下注册 Track、分组和详情面板(对于进程级 Plugin,则在每个进程组下注册)。
dev.perfetto.Gpu
基础 Plugin,为每个 GPU 布局一个 GPU 组,并用 gpu_counter_track、gpu_render_stage、gpu_log、vulkan_events 和 graphics_frame_event 系列的叶 Track 和汇总 Track 填充它。多 GPU 和多机 trace 被拆分为每个 GPU 的子组(当存在多台机器时附加机器标签);在 GpuCounterDescriptor / GpuCounterGroupSpec 中声明的自定义 Counter 分组显示为 Counters 下的可折叠子组。

dev.perfetto.GpuByProcess
呈现范围限定为单个进程且没有有意义的全局表示的 GPU 概念。例如,CUDA Stream 是一个进程级句柄:两个不同进程中相同的数字 stream ID 引用两个不相关的 Stream,因此将所有 Stream 显示在单个共享的 GPU 组下会产生误导。此 Plugin 将这些 Track 放置在每个所属进程下。
对于 GPU Slice 带有 device 和 stream 启动参数的 trace(例如 CUDA、HIP),它将 gpu_render_stage Slice 嵌套在每个进程下,格式为 <API> → Device #N → Context #N → Stream #N,折叠只有一个值的任何级别。不携带这些参数的 Slice 回退到每个 hw_queue_id 一个 Track,以源硬件队列 Track 命名(通常为 "Channel #N")。当进程跨越多个 GPU 时,叶 Track 嵌套在每个 GPU 的子组下。

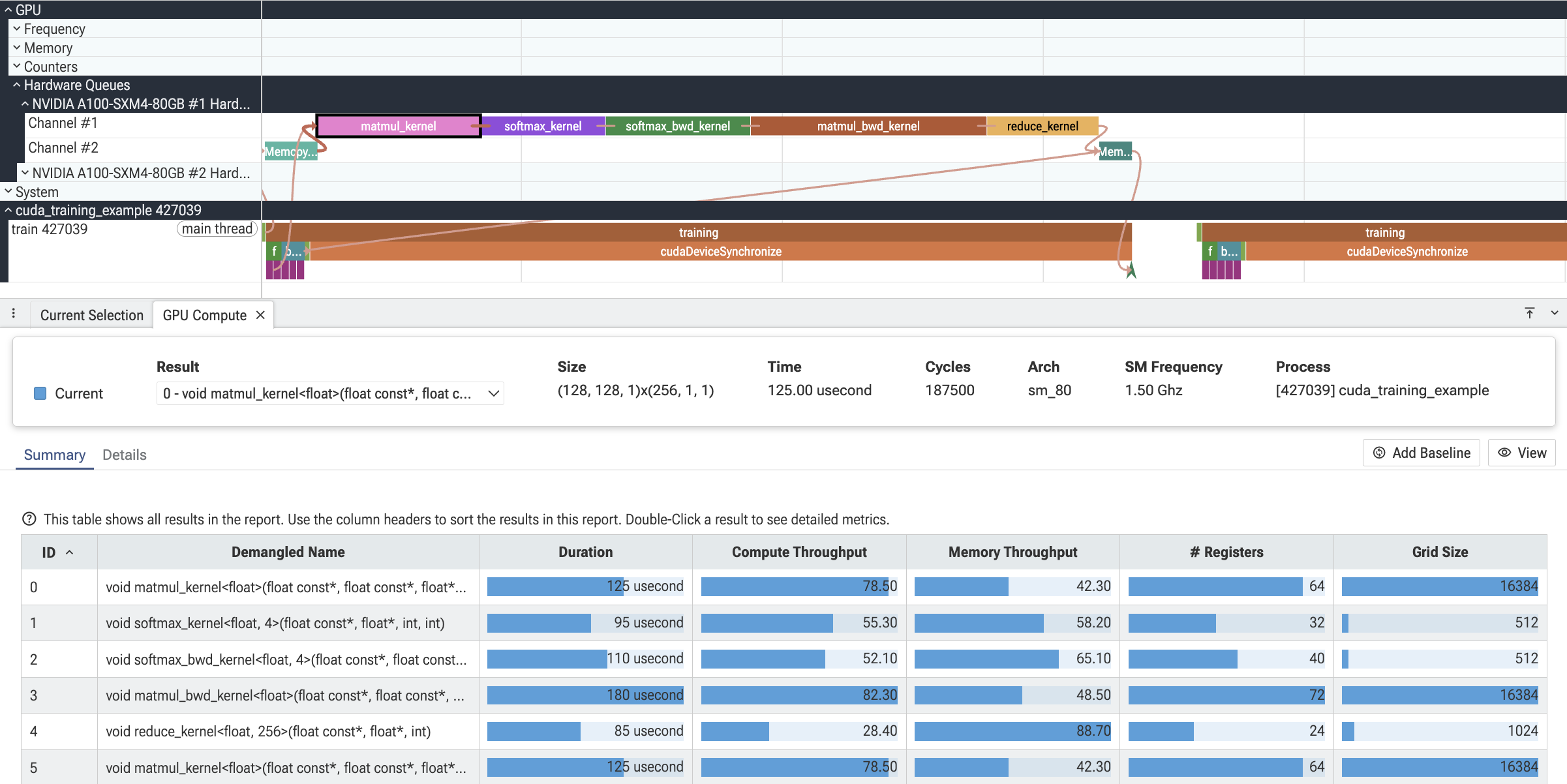
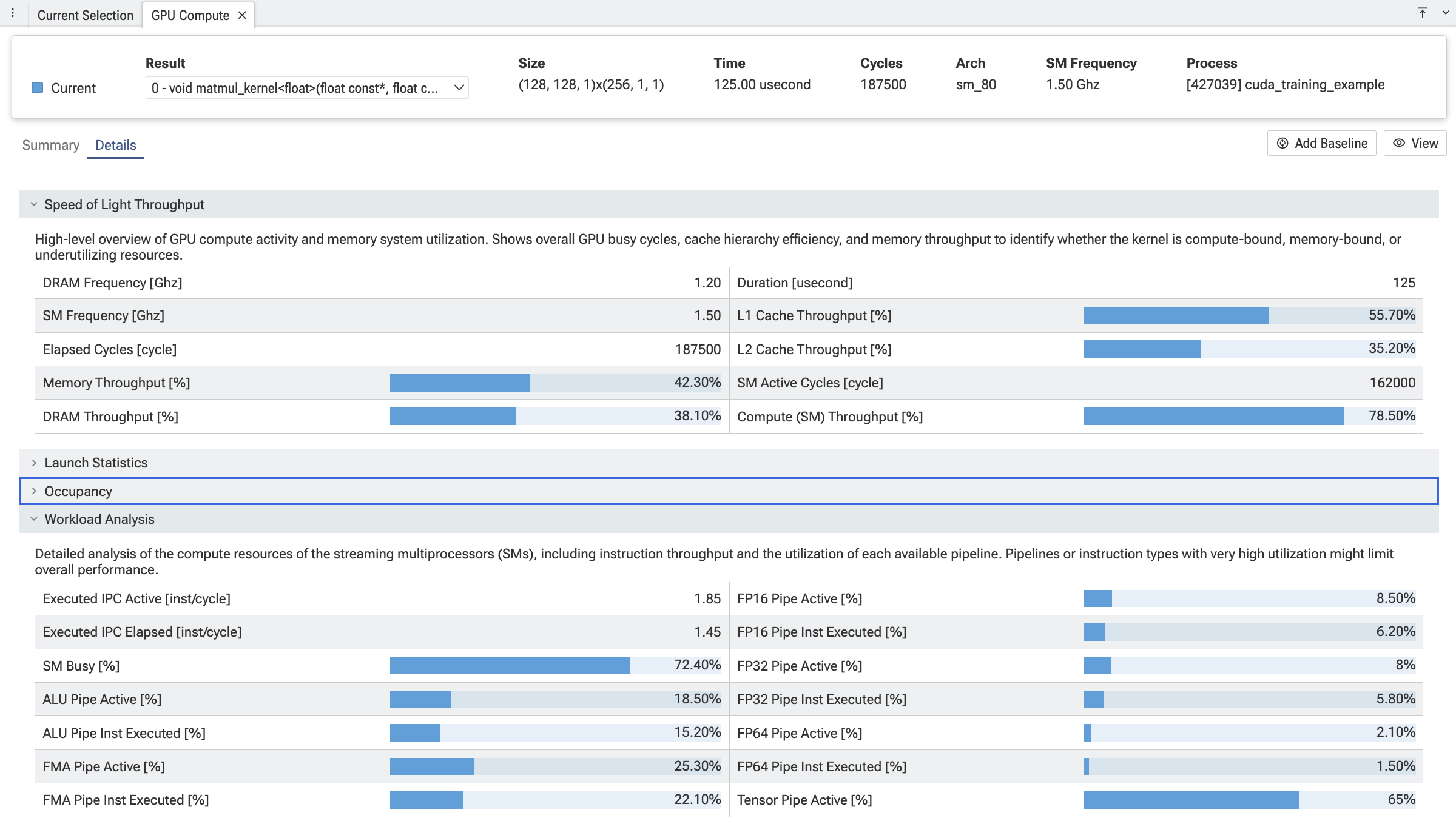
com.meta.GpuCompute
Compute kernel 深入分析。添加了三个选项卡,当选择计算类 gpu_render_stage Slice(即 gpu_slice.render_stage_category = COMPUTE)时会填充:
- Summary — trace 中每个 kernel 启动的表格,可按持续时间、占用率和其他硬件指标排序。双击跳转到该 kernel 的详情视图。
- Details — 每个部分的指标表格(Speed-of-Light、Launch Statistics、Occupancy、Workload Analysis),支持两个 kernel 之间的可选基线比较。
- Toolbar — kernel 选择器、基线固定、术语切换(CUDA / OpenCL / 厂商提供)以及自动单位转换(bytes → KB, ns → s 等)。
核心 Plugin 内置 CUDA 和 AMD 支持;其他厂商通过注册术语、指标部分、知名 metric ID 和分析提供程序的配套 Plugin 添加。参见 com.meta.GpuCompute/README.md 了解扩展 API。
示例查询
运行时间最长的前 5 个 kernel 及其时间加权利用率
此查询按持续时间对计算 kernel 进行排序,并为每个 kernel 计算 GPU Utilization Counter 在该 kernel 执行窗口内的时间加权平均值。counter_leading_intervals 将稀疏的 Counter 样本转换为 (ts, dur, value) 区间(每个样本的值持续到下一个样本),_interval_intersect 将这些区间与每个 kernel 的 [ts, ts + dur) 窗口进行裁剪,因此平均值按每个 Counter 值在 kernel 执行期间实际生效的时间加权。
INCLUDE PERFETTO MODULE counters.intervals;
INCLUDE PERFETTO MODULE intervals.intersect;
WITH
-- GPU Utilization Counter,展开为 (ts, dur, value) 区间。
-- 携带 ugpu 以便交集可以将每个 kernel 匹配到自己的 GPU。
utilization AS (
SELECT u.id, u.ts, u.dur, u.value, gct.ugpu
FROM counter_leading_intervals!((
SELECT c.id, c.ts, c.track_id, c.value
FROM counter c
JOIN gpu_counter_track gct ON gct.id = c.track_id
WHERE gct.name = 'Utilization'
)) u
JOIN gpu_counter_track gct ON gct.id = u.track_id
),
-- 运行时间最长的 5 个计算 kernel(render_stage_category 2 = COMPUTE)。
top_kernels AS (
SELECT
s.id, s.ts, s.dur, s.name,
extract_arg(t.dimension_arg_set_id, 'ugpu') AS ugpu
FROM gpu_slice s
JOIN gpu_track t ON s.track_id = t.id
WHERE s.render_stage_category = 2 AND s.dur > 0
ORDER BY s.dur DESC
LIMIT 5
)
SELECT
k.name AS kernel,
g.name AS gpu_name,
k.dur AS dur_ns,
-- 时间加权平均值:sum(value * overlap_dur) / kernel_dur。
SUM(u.value * ii.dur) / k.dur AS avg_utilization
FROM top_kernels k
LEFT JOIN gpu g ON g.id = k.ugpu
JOIN _interval_intersect!((top_kernels, utilization), (ugpu)) ii
ON ii.id_0 = k.id
JOIN utilization u ON u.id = ii.id_1
GROUP BY k.id, k.name, g.name, k.dur
ORDER BY k.dur DESC;示例输出(双 GPU 训练 trace):
| kernel | gpu_name | dur_ns | avg_utilization |
|---|---|---|---|
| matmul_bwd_kernel | NVIDIA A100-SXM4-80GB #1 | 180000 | 78.27 |
| matmul_bwd_kernel | NVIDIA A100-SXM4-80GB #2 | 180000 | 77.25 |
| matmul_kernel | NVIDIA A100-SXM4-80GB #1 | 125000 | 78.70 |
| matmul_kernel | NVIDIA A100-SXM4-80GB #2 | 125000 | 78.83 |
| softmax_bwd_kernel | NVIDIA A100-SXM4-80GB #1 | 110000 | 73.76 |