
PerfettoSQL 入门指南
PerfettoSQL 是 Perfetto 中 trace 分析的基础。它是一种 SQL 方言,允许你将 trace 内容作为数据库进行查询。本文介绍了使用 PerfettoSQL 进行 trace 查询的核心概念,并提供了如何编写查询的指导。
Trace 查询概述
Perfetto UI 是一个强大的可视化分析工具,提供调用栈、Timeline 视图、线程 track 和 slice。但它还包括一个强大的 SQL 查询语言(PerfettoSQL),由查询引擎(TraceProcessor)解释,使你能够以编程方式提取数据。
虽然 UI 对于多种分析场景功能强大,但用户能够在 Perfetto UI 中编写和执行查询用于多种目的,例如:
- 从 trace 中提取性能数据
- 创建自定义可视化(Debug track)以执行更复杂的分析
- 创建派生 metrics
- 使用数据驱动的逻辑识别性能瓶颈
除了 Perfetto UI 之外,你可以使用 Python Trace Processor API 或 C++ Trace Processor 以编程方式查询 trace。
Perfetto 还支持通过 Batch Trace Processor 进行批量 trace 分析。此系统的一个关键优势是查询可重用性:用于单个 trace 的相同 PerfettoSQL 查询无需修改即可应用于大型数据集。
核心概念
在编写查询之前,了解 Perfetto 如何构造 trace 数据的基础概念很重要。
事件
在最一般的意义上,trace 只是一组带时间戳的"事件"。事件可以具有关联的元数据和上下文,使它们能够被解释和分析。时间戳以纳秒为单位;值本身取决于 TraceConfig 中选择的 clock。
事件构成了 trace processor 的基础,并且有两种类型:slice 和 counter。
Slice

Slice 指的是一段时间间隔,其中包含一些描述该期间内发生情况的数据。一些 slice 的示例包括:
- Android 上的 atrace slice
- 来自 Chrome 的用户空间 slice
Counter

Counter 是随时间变化的连续值。一些 counter 的示例包括:
- 每个 CPU 核心的 CPU 频率
- RSS 内存事件 - 来自内核和从 /proc/stats 轮询
- Android 上的 atrace counter 事件
- Chrome counter 事件
Track
Track 是相同类型和相同关联上下文的事件的命名分区。Track 将事件与特定的上下文(如线程(utid)、进程(upid)或 CPU)关联起来。例如:
- 同步用户空间 slice 每个发出事件的线程有一个 track
- 异步用户空间 slice 每个链接一组异步事件的"cookie"有一个 track
Track 可以根据它们包含的事件类型和它们关联的上下文分为各种类型。示例包括:
- 全局 track 不与任何上下文关联并包含 slice
- 线程 track 与单个线程关联并包含 slice
- Counter track 不与任何上下文关联并包含 counter
- CPU counter track 与单个 CPU 关联并包含 counter
注意,Perfetto UI 也使用"track"一词来指代 timeline 上的可视行。这些是用于组织显示的 UI 层级概念,与 trace processor 的 track 并非一一对应。
调度
CPU 调度数据有自己的专用表,不通过 track 访问。sched 表包含每个线程在 CPU 上运行的时间间隔的行。关键列包括 ts、dur、cpu、utid、end_state 和 priority。
例如,要查看 CPU 0 上正在运行哪些线程:
SELECT ts, dur, utid
FROM sched
WHERE cpu = 0
LIMIT 10;与之互补的 thread_state 表显示了线程在_未_运行时正在做什么——无论它是在休眠、不可中断睡眠中阻塞、可运行并等待 CPU,等等。
要查询带有线程和进程名称的调度数据,请使用 sched.with_context stdlib 模块,该模块提供了 sched_with_thread_process 视图:
INCLUDE PERFETTO MODULE sched.with_context;
SELECT ts, dur, cpu, thread_name, process_name
FROM sched_with_thread_process
WHERE thread_name = 'RenderThread'
LIMIT 10;栈采样 (CPU profiling)
栈采样定期捕获代码执行的位置,提供 CPU 使用情况的统计视图。Perfetto 支持多种数据源,包括 Linux perf、simpleperf、macOS Instruments 和 Chrome CPU profiling。
原始数据存在于特定来源的表中(perf_sample、cpu_profile_stack_sample)。每个样本都有一个 callsite_id,指向 stack_profile_callsite 表——这是一个由 frame 组成的链表,形成了调用栈。每个 callsite 行都有一个 frame_id,指向 stack_profile_frame(函数名和映射/二进制文件),以及一个 parent_id,指向栈中上一层的 frame。
要将样本解析为其叶节点(最近的)frame,通过 callsite 连接到 frame:
SELECT
s.ts,
s.utid,
f.name AS function_name,
m.name AS binary_name
FROM perf_sample AS s
JOIN stack_profile_callsite AS c ON s.callsite_id = c.id
JOIN stack_profile_frame AS f ON c.frame_id = f.id
JOIN stack_profile_mapping AS m ON f.mapping = m.id
LIMIT 10;对于完整调用栈的聚合和汇总,请使用 stacks.cpu_profiling stdlib 模块。它提供了一个跨所有数据源的统一 cpu_profiling_samples 表,以及一个 cpu_profiling_summary_tree 表,用于计算 self count(函数是叶节点的样本数)和 cumulative count(函数在调用栈中任何位置出现的样本数):
INCLUDE PERFETTO MODULE stacks.cpu_profiling;
-- 跨所有 CPU profiling 数据源的统一样本:
SELECT ts, thread_name, callsite_id
FROM cpu_profiling_samples
LIMIT 10;
-- 带有 self 和 cumulative 计数的聚合调用栈树:
SELECT name, mapping_name, self_count, cumulative_count
FROM cpu_profiling_summary_tree
ORDER BY cumulative_count DESC
LIMIT 20;Heap Profiling
Heap Profiling 捕获内存分配及其调用栈,显示内存在何时何地被分配(和释放)。这对于查找内存泄漏和理解分配模式很有用。
heap_profile_allocation 表包含每个分配或释放事件的行。关键列包括 ts、upid、callsite_id、count 和 size。upid 列可以与 process 表连接以获取完整的进程命令行(cmdline)和真实 pid。
SELECT ts, upid, size, count
FROM heap_profile_allocation
WHERE size > 0
ORDER BY size DESC
LIMIT 10;与 CPU profiling 一样,每个分配都有一个 callsite_id,指向调用栈表。要将分配解析为其叶节点 frame:
SELECT
a.ts,
a.size,
f.name AS function_name,
m.name AS binary_name
FROM heap_profile_allocation AS a
JOIN stack_profile_callsite AS c ON a.callsite_id = c.id
JOIN stack_profile_frame AS f ON c.frame_id = f.id
JOIN stack_profile_mapping AS m ON f.mapping = m.id
WHERE a.size > 0
LIMIT 10;对于带有 self 和 cumulative 大小的完整调用栈聚合,请使用 android.memory.heap_profile.summary_tree stdlib 模块:
INCLUDE PERFETTO MODULE android.memory.heap_profile.summary_tree;
SELECT name, mapping_name, self_size, cumulative_size
FROM android_heap_profile_summary_tree
ORDER BY cumulative_size DESC
LIMIT 20;堆图 (heap dumps)
堆图数据捕获托管堆(例如 Android 上的 Java/ART)的快照,记录某个时间点的完整对象引用图。这对于理解内存保持和查找托管运行时中的泄漏很有用。
关键表包括:
heap_graph_object:堆上的对象,包含其类型、大小和可达性信息。heap_graph_reference:对象之间的引用(哪个对象指向哪个对象)。heap_graph_class:类元数据(名称、父类、类加载器)。
SELECT
c.name AS class_name,
SUM(o.self_size) AS total_size,
COUNT() AS object_count
FROM heap_graph_object AS o
JOIN heap_graph_class AS c ON o.type_id = c.id
WHERE o.reachable
GROUP BY c.name
ORDER BY total_size DESC
LIMIT 10;线程和进程标识符
在 trace 的上下文中考虑时,线程和进程的处理需要特别小心;线程和进程的标识符(例如 Android/macOS/Linux 中的 pid/tgid 和 tid)可以在 trace 过程中被操作系统重用。这意味着当查询 trace processor 中的表时,不能将它们作为唯一标识符依赖。
为了解决此问题,trace processor 使用 utid(unique tid)表示线程,使用 upid(unique pid)表示进程。所有对线程和进程的引用(例如,在 CPU 调度数据、线程 track 中)都使用 utid 和 upid 而不是系统标识符。
在 Perfetto UI 中查询 trace
既然你了解了核心概念,就可以开始编写查询了。
Perfetto 直接在 UI 中提供了两种探索 trace 数据的方式:
- Data Explorer 页面让你无需编写 SQL 即可交互式浏览可用表。这对于发现 trace 中有哪些数据和理解表结构很有用。
- Query (SQL) 标签提供了一个自由格式的 SQL 编辑器,用于编写和执行 PerfettoSQL 查询。
要使用 Query 标签:
在 Perfetto UI 中打开 trace。
单击导航栏中的 Query (SQL) 标签(见下图)。
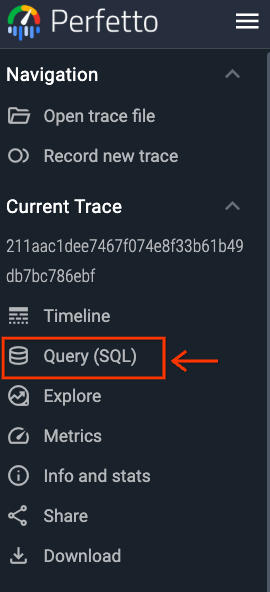
选择此标签后,查询 UI 将显示,你可以自由格式编写 PerfettoSQL 查询,该界面支持编写查询、显示查询结果和查询历史记录,如下图所示。
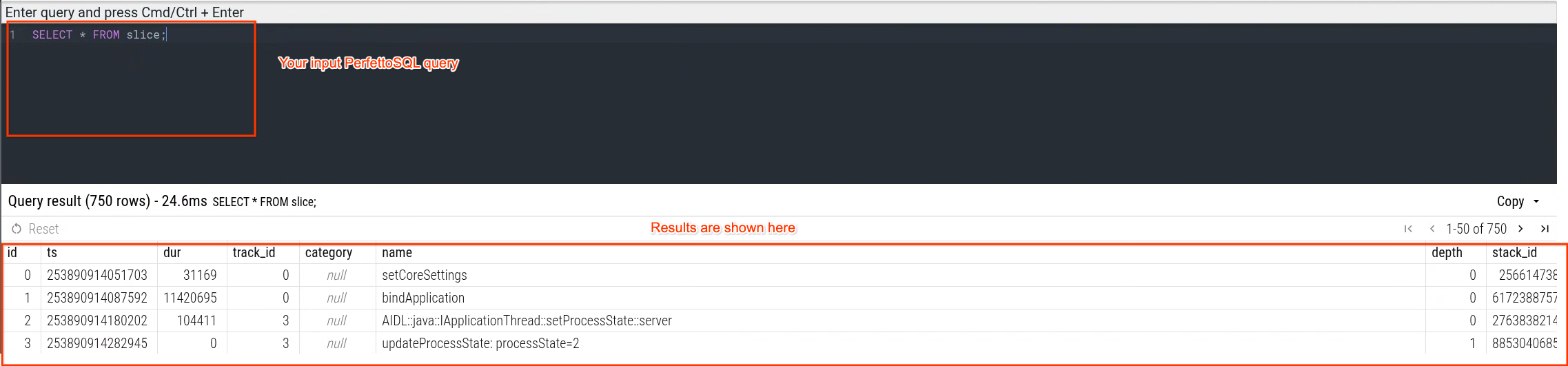
- 在查询 UI 区域中输入你的查询,然后按 Ctrl + Enter(或 Cmd + Enter)执行。
执行查询后,查询结果将在同一窗口中显示。
当你对如何查询以及查询什么有一定了解时,这种查询方法很有用。
为了了解如何编写查询,请参阅 语法指南,然后为了查找可用的表、模块、函数等,请参阅 标准库。
很多时候,将查询结果转换为 track 对于在 UI 中执行复杂分析很有用,我们鼓励读者查看 Debug Tracks 以获取有关如何实现此操作的更多信息。
示例:执行基本查询
探索 trace 的最简单方法是从原始表中进行选择。例如,要查看 trace 中的前 10 个 slice,你可以运行:
SELECT ts, dur, name FROM slice LIMIT 10;你可以通过在 PerfettoSQL 查询 UI 中单击 Run Query 来编写和执行它,下面是来自 trace 的示例。
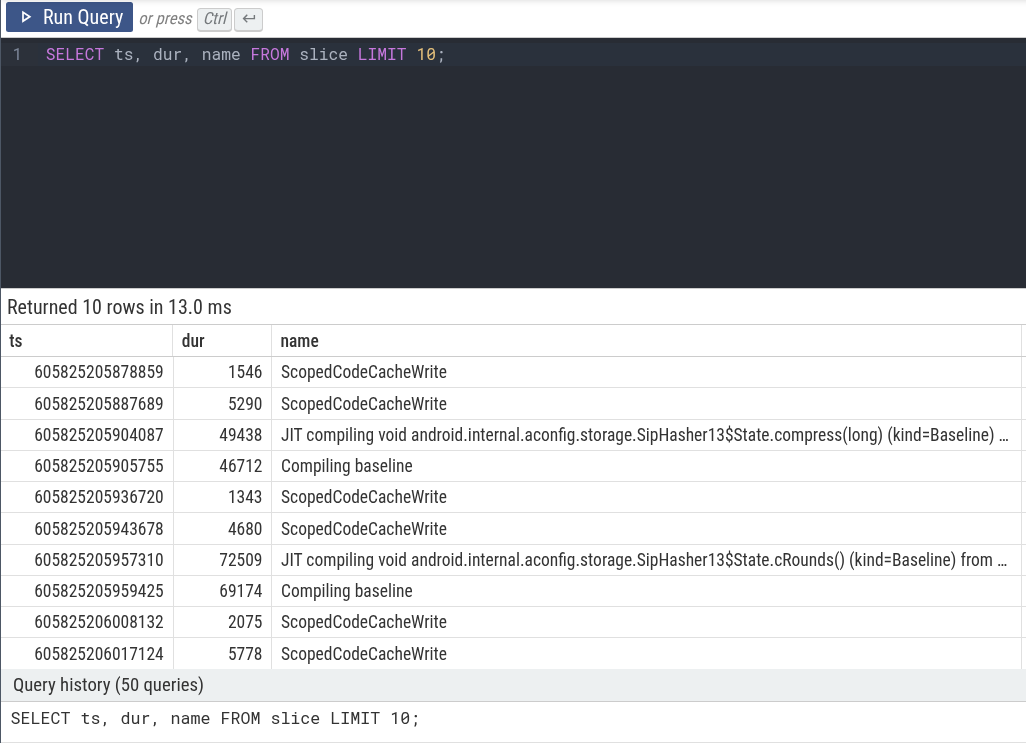
为 Slice 添加上下文
查询 slice 时的一个常见问题是:"我如何获取发出此 slice 的线程或进程?"。最简单的方法是使用 slices.with_context 标准库模块,该模块提供了预连接的视图,直接包含线程和进程信息。
INCLUDE PERFETTO MODULE slices.with_context;导入后,你可以访问三个视图:
thread_slice — 来自线程 track 的 slice,带有线程和进程上下文:
SELECT ts, dur, name, thread_name, process_name, tid, pid
FROM thread_slice
WHERE name = 'measure';process_slice — 来自进程 track 的 slice,带有进程上下文:
SELECT ts, dur, name, process_name, pid
FROM process_slice
WHERE name LIKE 'MyEvent%';thread_or_process_slice — 线程和进程 slice 的组合视图,当你想要搜索所有 slice 而不考虑 track 类型时很有用:
SELECT ts, dur, name, thread_name, process_name
FROM thread_or_process_slice
WHERE dur > 1000000;这些视图是大多数 slice 查询的推荐方式。它们替你处理了连接操作,并公开了常用的列,如 thread_name、process_name、tid、pid、utid 和 upid。
手动 JOIN 以获得更多控制
在底层,thread_slice 将 slice 与 thread_track、thread 和 process 进行连接。如果你需要 stdlib 视图未公开的列,或者你正在处理没有 stdlib 便捷视图的表(例如 counter track),你可以自己编写连接。
thread 和 process 表将 utid 和 upid 映射到系统级别的 tid、pid 和名称:
SELECT tid, name
FROM thread
WHERE utid = 10;例如,要获取值大于 1000 的 mem.swap counter 的所有进程的 upid:
SELECT upid
FROM counter
JOIN process_counter_track ON process_counter_track.id = counter.track_id
WHERE process_counter_track.name = 'mem.swap' AND value > 1000;或者手动将 slice 与线程信息连接:
SELECT thread.name AS thread_name
FROM slice
JOIN thread_track ON slice.track_id = thread_track.id
JOIN thread USING(utid)
WHERE slice.name = 'measure'
GROUP BY thread_name;最佳实践
优先使用 stdlib 视图而非手动 JOIN
标准库为最常见的查询提供了预连接视图。使用 thread_slice、process_slice、thread_or_process_slice 和 sched_with_thread_process 可以节省样板代码,避免连接条件中的错误。
尽早过滤
始终将 WHERE 子句——尤其是对 name 的过滤——尽可能提前。这让 trace processor 可以跳过扫描不会对结果产生贡献的行。
探索时使用 LIMIT
当你不熟悉某个表时,先从小查询开始了解其结构,然后再编写复杂查询:
SELECT * FROM slice LIMIT 10;时间戳以纳秒为单位
所有 ts 和 dur 值均以纳秒为单位。如需人类可读的输出,请使用 time.conversion stdlib 模块:
INCLUDE PERFETTO MODULE time.conversion;
SELECT name, time_to_ms(dur) AS dur_ms
FROM slice
WHERE dur > time_from_ms(10);高级查询
对于需要超越标准库或构建自己的抽象的用户,PerfettoSQL 提供了几种高级功能。
辅助函数
辅助函数是内置在 C++ 中的函数,用于减少需要在 SQL 中编写的样板代码。
提取参数
EXTRACT_ARG 是一个辅助函数,用于从 args 表中检索事件(例如 slice 或 counter)的属性。
它接受 arg_set_id 和 key 作为输入,并返回在 args 表中查找的值。
例如,要从 ftrace_event 表中检索 sched_switch 事件的 prev_comm 字段。
SELECT EXTRACT_ARG(arg_set_id, 'prev_comm')
FROM ftrace_event
WHERE name = 'sched_switch'在幕后,上述查询将脱糖为以下内容:
SELECT
(
SELECT string_value
FROM args
WHERE key = 'prev_comm' AND args.arg_set_id = raw.arg_set_id
)
FROM ftrace_event
WHERE name = 'sched_switch'运算符表
SQL 查询通常足以从 trace processor 检索数据。但有时,某些构造很难用纯 SQL 表示。
在这些情况下,trace processor 具有特殊的"运算符表",它们用 C++ 解决特定问题,但公开 SQL 接口以供查询利用。
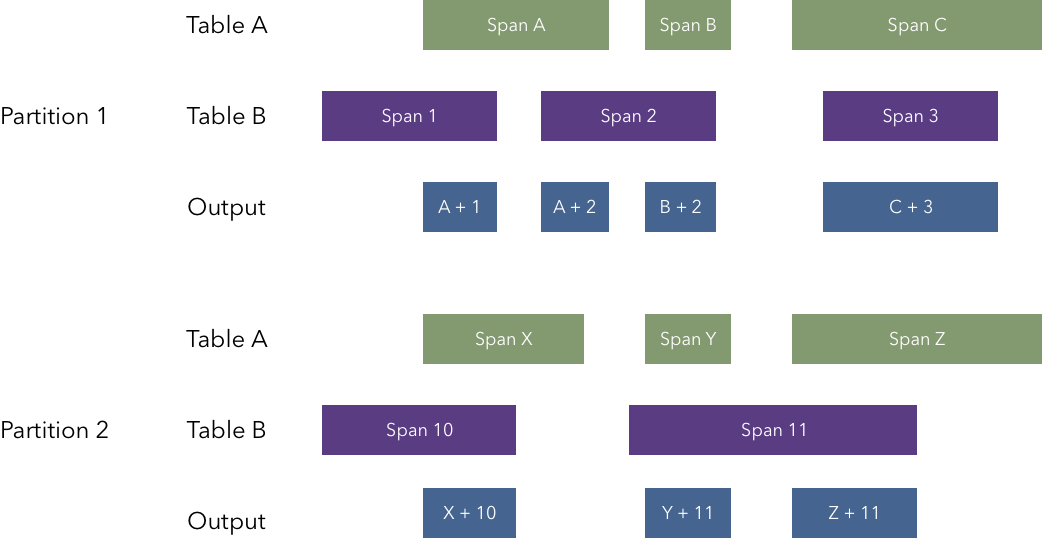
Span join
Span join 是一个自定义运算符表,用于计算来自两个表或视图的时间段的交集。在此概念中,span 是表/视图中包含"ts"(时间戳)和"dur"(持续时间)列的一行。
可以指定一个列(称为 _partition_),在计算交集之前将每个表的行划分为分区。
-- 获取所有调度 slice
CREATE VIEW sp_sched AS
SELECT ts, dur, cpu, utid
FROM sched;
-- 获取所有 cpu frequency slice
CREATE VIEW sp_frequency AS
SELECT
ts,
lead(ts) OVER (PARTITION BY track_id ORDER BY ts) - ts as dur,
cpu,
value as freq
FROM counter
JOIN cpu_counter_track ON counter.track_id = cpu_counter_track.id
WHERE cpu_counter_track.name = 'cpufreq';
-- 创建将 cpu frequency 与
-- 调度 slice 结合的 span joined 表。
CREATE VIRTUAL TABLE sched_with_frequency
USING SPAN_JOIN(sp_sched PARTITIONED cpu, sp_frequency PARTITIONED cpu);
-- 此 span joined 表可以正常查询,并具有来自两个表
-- 的列。
SELECT ts, dur, cpu, utid, freq
FROM sched_with_frequency;NOTE: 可以在两个表、一个表或都不表上指定分区。如果在两个表上指定,则必须在每个表上指定相同的列名称。
WARNING: span joined 表的一个重要限制是,同一分区中同一表的 span _不能_重叠。出于性能原因,span join 不会尝试检测并在这种情况下出错;相反,将静默产生错误的行。
WARNING: 分区必须是整数。重要的是,不支持字符串分区;请注意,可以通过将 HASH 函数应用于字符串列将字符串转换为整数。
还支持左连接和外 span join;两者的功能类似于 SQL 中的左连接和外连接。
-- 左表分区 + 右表未分区。
CREATE VIRTUAL TABLE left_join
USING SPAN_LEFT_JOIN(table_a PARTITIONED a, table_b);
-- 两个表都未分区。
CREATE VIRTUAL TABLE outer_join
USING SPAN_OUTER_JOIN(table_x, table_y);NOTE: 如果分区表为空,并且是 a) 外连接的一部分 b) 左连接的右侧,则存在细微差别。在这种情况下,即使另一个表非空,也不会发出任何 slice。在考虑实际中如何使用 span join 之后,决定此方法是最自然的。
Ancestor slice
给定一个 slice,ancestor_slice 返回同一 track 上在该 slice 上方的所有直接父 slice(即通过跟随 parent_id 链直到根节点(depth 0)可以找到的所有 slice)。
+----------------------------+ depth 0 \
| A (id=1) | |
| +------------+ +--------+ | | ancestor_slice(4)
| | B (id=2) | | D | | depth 1 > 返回 A, B
| | +--------+ | | | | |
| | |C (id=4)| | | | | depth 2 /
| | +--------+ | | | |
| +------------+ +--------+ |
+----------------------------+返回的格式与 slice 表 相同。
例如,以下查找给定一组感兴趣的 slice 的顶层 slice:
CREATE VIEW interesting_slices AS
SELECT id, ts, dur, track_id
FROM slice WHERE name LIKE "%interesting slice name%";
SELECT
*
FROM
interesting_slices LEFT JOIN
ancestor_slice(interesting_slices.id) AS ancestor ON ancestor.depth = 0TIP: 要检查一个 slice 是否是另一个 slice 的祖先而无需获取所有祖先,请使用 slice_is_ancestor(ancestor_id, descendant_id) 函数,该函数无需任何导入即可使用。
Descendant slice
给定一个 slice,descendant_slice 返回同一 track 上嵌套在该 slice 下的所有 slice(即同一时间范围内深度大于给定 slice 深度的所有 slice)。
+----------------------------+ depth 0
| A (id=1) |
| +------------+ +--------+ | \
| | B (id=2) | | D | | depth 1 |
| | +--------+ | | +----+ | | | descendant_slice(1)
| | |C (id=4)| | | | E | | | depth 2 > 返回 B, C, D, E
| | +--------+ | | +----+ | | |
| +------------+ +--------+ | /
+----------------------------+返回的格式与 slice 表 相同。
例如,以下查找每个感兴趣的 slice 下的 slice 数量:
CREATE VIEW interesting_slices AS
SELECT id, ts, dur, track_id
FROM slice WHERE name LIKE "%interesting slice name%";
SELECT
interesting_slices.*,
(
SELECT COUNT(*)
FROM descendant_slice(interesting_slices.id)
) AS total_descendants
FROM interesting_slicesConnected/Following/Preceding flows
DIRECTLY_CONNECTED_FLOW、FOLLOWING_FLOW 和 PRECEDING_FLOW 是自定义运算符表,它们接受 slice 表的 id 列,并收集 flow 表 中与给定起始 slice 直接或间接连接的所有条目。
DIRECTLY_CONNECTED_FLOW(start_slice_id) — 包含 flow 表 中存在于任何类型的链中的所有条目:flow[0] -> flow[1] -> ... -> flow[n],其中 flow[i].slice_out = flow[i+1].slice_in 且 flow[0].slice_out = start_slice_id OR start_slice_id = flow[n].slice_in。
NOTE: 与后续/前置流函数不同,此函数在从 slice 搜索流时不会包含连接到祖先或后代的流。它仅包含直接连接的链中的 slice。
FOLLOWING_FLOW(start_slice_id) — 包含所有可以通过从流的传出 slice 递归跟随到其传入 slice 以及从到达的 slice 到其子 slice 而从给定 slice 到达的流。返回表包含 flow 表 中存在于任何类型的链中的所有条目:flow[0] -> flow[1] -> ... -> flow[n],其中 flow[i+1].slice_out IN DESCENDANT_SLICE(flow[i].slice_in) OR flow[i+1].slice_out = flow[i].slice_in 且 flow[0].slice_out IN DESCENDANT_SLICE(start_slice_id) OR flow[0].slice_out = start_slice_id。
PRECEDING_FLOW(start_slice_id) — 包含所有可以通过从流的传入 slice 递归跟随到其传出 slice 以及从到达的 slice 到其父 slice 而从给定 slice 到达的流。返回表包含 flow 表 中存在于任何类型的链中的所有条目:flow[n] -> flow[n-1] -> ... -> flow[0],其中 flow[i].slice_in IN ANCESTOR_SLICE(flow[i+1].slice_out) OR flow[i].slice_in = flow[i+1].slice_out 且 flow[0].slice_in IN ANCESTOR_SLICE(start_slice_id) OR flow[0].slice_in = start_slice_id。
-- 每个 slice 的后续流数量
SELECT (SELECT COUNT(*) FROM FOLLOWING_FLOW(slice_id)) as following FROM slice;下一步
既然你对 PerfettoSQL 有了基础了解,你可以探索以下主题以加深你的知识:
- **PerfettoSQL 语法**:了解 Perfetto 支持的 SQL 语法,包括用于创建函数、表和视图的特殊功能。
- **标准库**:探索标准库中可用的丰富模块集,用于分析常见场景,如 CPU 使用率、内存和功耗。
- **Trace Processor (C++)**:了解如何使用交互式 shell 和底层 C++ 库。
- **Trace Processor (Python)**:利用 Python API 将 trace 分析与丰富的数据科学和可视化生态系统结合起来。