Cookbook: 分析 Android Traces
本页将带你了解一些真实世界的示例,介绍如何使用 SQL 和 Perfetto UI 的更高级功能来分析问题。
查找 slices
演示内容:
- 查询 slices。
- GLOB 和类似操作符。
- 常见聚合器:COUNT、SUM、PERCENTILE。
- JOIN 表。
在 Perfetto 的 Timeline UI 中看到的 Slices 也可以用 PerfettoSQL 查询。按下侧边栏中的 "Query (SQL)" 并输入此查询:
SELECT *
FROM slice
WHERE name GLOB '*interesting_slice*'
LIMIT 10;导航回 Timeline(按下 "Show timeline")将在底部栏中显示结果表。你可以点击 slice ID 以跳转到 Timeline 中的 slice。
PerfettoSQL 支持多种 pattern matching operators,如 GLOB、LIKE 和 REGEXP。你还可以使用不同的聚合器来生成选择的统计信息。
SELECT
name,
COUNT(dur) AS count_slice,
-- 将纳秒转换为毫秒
AVG(dur) / 1000000 AS avg_dur_ms,
CAST(MAX(dur) AS DOUBLE) / 1000000 AS max_dur_ms,
CAST(MIN(dur) AS DOUBLE) / 1000000 AS min_dur_ms,
PERCENTILE(dur,50) / 1000000 AS P50_dur_ms,
PERCENTILE(dur,90) / 1000000 AS P90_dur_ms,
PERCENTILE(dur,99) / 1000000 AS P99_dur_ms
FROM slice
WHERE name REGEXP '.*interesting_slice.*'
GROUP BY name
ORDER BY count_slice DESC
LIMIT 10;你可以跨多个表连接信息,以在查询结果中显示更多信息或缩小搜索范围。
SELECT
s.id AS id,
s.ts AS ts,
s.track_id AS track_id,
s.slice_id AS slice_id,
s.dur AS dur,
s.name AS slice,
p.name AS process,
t.name AS thread
FROM slice s
JOIN thread_track tt ON s.track_id = tt.id
JOIN thread t on tt.utid = t.utid
JOIN process p on t.upid = p.upid
WHERE s.name LIKE '%interesting_slice%'
-- 只在你应用的进程中查找 slices
AND p.name = 'com.example.myapp'
-- 只在你应用的主线程上查找 slices
AND t.is_main_thread
ORDER BY dur DESC;在 SQL 视图中运行查询后,点击侧边栏中的 "Show timeline",查询结果将出现在底部栏中。包含 slice 列 id、ts、dur、track_id 和 slice_id 的查询可以链接到 Timeline 视图中的 slices,以便轻松导航。点击 id 下的值,Timeline 将直接跳转到该 slice。

查找进程元数据并获取 UPID
演示内容:
- 获取
process_name、upid和uid。这些数据用于从其他表中获取进程级别的指标 - 使用 UPID 从其他表获取进程特定的指标
- 使用
GLOB进行基于正则的查询
了解诸如进程名称、包名或 UPID 等细节非常有用,因为它们为 Perfetto 中的许多其他查询提供了基础。
INCLUDE PERFETTO MODULE android.process_metadata;
SELECT
upid,
process_name,
package_name,
uid
FROM android_process_metadata
WHERE process_name GLOB '*Camera*'; -- GLOB 搜索区分大小写结果:

注意: 如果你没有看到预期的进程,这可能是因为 GLOB 搜索区分大小写。因此,如果你不确定进程名称,值得执行 select upid, process_name, package_name, uid from android_process_metadata 来查找你进程的 UPID。
UPID 是唯一的进程 ID,在 trace 持续时间内保持不变,而 PID(进程 ID)可能会改变。Perfetto 中的许多 standard library tables,如 android_lmk_events、cpu_cycles_per_process 等,使用 UPID 指向进程。这在需要针对你的进程过滤数据时特别方便。UPID 也可用于与其他表执行 JOIN 操作。获取 GoogleCamera 冷启动原因的示例:
INCLUDE PERFETTO MODULE android.app_process_starts;
INCLUDE PERFETTO MODULE time.conversion;
SELECT
process_name,
upid,
intent,
reason,
time_to_ms(total_dur)
FROM android_app_process_starts
WHERE upid = 844;UID 是 Android app User ID,也很有用。在 package_name 不存在的情况下,标准库表以 uid=$X 格式填充。例如,android_network_packets。获取进程的网络传输字节数的示例:
include perfetto module android.network_packets;
SELECT
*
FROM android_network_packets
WHERE package_name = 'uid=12332';查询内存使用情况
演示内容:
- 使用 Perfetto 标准库模块进行内存分析
- 查询每个进程的内存使用情况
- 查找 trace 期间的峰值内存使用情况
Android 通过各种指标提供全面的内存跟踪,包括 RSS(Resident Set Size)、swap 使用情况和 oom_score_adj
(OOM-killer adjustment scores,
进程重要性的度量)。android.memory.process 模块提供标准化的表,用于分析内存消耗模式。
要查询特定进程(如 SystemUI)的内存使用情况:
INCLUDE PERFETTO MODULE android.memory.process;
SELECT *
FROM memory_oom_score_with_rss_and_swap_per_process
WHERE process_name GLOB 'com.android.systemui*';查找峰值内存使用情况
要计算 trace 期间进程的峰值内存使用情况,请使用 MAX 聚合。我们强烈建议使用 anon_rss_and_swap 作为主要指标,因为它捕获了 "我的应用正在使用大量内存" 的大多数故障条件。请注意,它不跟踪 file/shmem,因此如果这些对你很重要,你也应该使用这些指标:
INCLUDE PERFETTO MODULE android.memory.process;
SELECT
process_name,
-- 推荐:Anonymous memory + swap 是应用内存压力的最佳指标
MAX(anon_rss_and_swap) / 1024.0 AS peak_anon_rss_and_swap_mb,
-- FYI: 其他内存指标用于附加上下文
MAX(anon_rss) / 1024.0 AS peak_anon_rss_mb,
MAX(file_rss) / 1024.0 AS peak_file_rss_mb,
MAX(swap) / 1024.0 AS peak_swap_mb
FROM memory_oom_score_with_rss_and_swap_per_process
WHERE process_name GLOB 'com.android.systemui*'
GROUP BY process_name;注意: 有关可用内存表和指标的全面文档,请参阅 Android Memory Process module documentation。
查找不可中断睡眠的主要原因
演示内容:
- 在 PerfettoSQL 唯一 ID 上连接表。
- SQL 聚合。
Thread tracks 显示 thread's state, 例如它是否正在运行、可运行但未运行、休眠等。性能问题的常见来源是应用线程进入 "uninterruptible sleep",即调用阻塞在不可中断条件上的内核函数。
要排除不可中断睡眠问题,你需要在采集 traces 时在 Perfetto 配置中包含以下代码段:
data_sources: {
config {
name: "linux.ftrace"
target_buffer: 0
ftrace_config {
ftrace_events: "sched/sched_blocked_reason"
}
}
}配置完成后,点击处于不可中断睡眠状态的 thread state slice 时,你将在底部栏中看到一个名为 "blocked_function" 的字段。你可以运行查询来汇总数据,而不是点击单个 slices:
SELECT blocked_function, COUNT(thread_state.id), SUM(dur)
FROM thread_state
JOIN thread USING (utid)
JOIN process USING (upid)
WHERE process.name = "com.google.android.youtube"
GROUP BY blocked_function
ORDER BY SUM(dur) DESC;查找在 monitor contention 上阻塞的应用启动
演示内容:
PARTITION以按列的值细分 slices 表。SPAN_JOIN以从两个表的数据交集中创建 spans。
在 Android Java 和 Kotlin 中,"monitor contention" 是指当一个线程试图进入 synchronized 部分或调用 synchronized 方法,但另一个线程已经获取了用于同步的锁(即 monitor)时。下面的示例演示了查找在应用启动时发生的 monitor contention slices,这些 slices 阻塞了应用的主线程,从而延迟了应用的启动。
INCLUDE PERFETTO MODULE android.monitor_contention;
INCLUDE PERFETTO MODULE android.startup.startups;
-- 为启动项连接包和进程信息
DROP VIEW IF EXISTS startups;
CREATE VIEW startups AS
SELECT startup_id, ts, dur, upid
FROM android_startups
JOIN android_startup_processes USING(startup_id);
-- 在同一进程中将 monitor contention 与启动项相交。
-- 这确保我们只查看正在启动的应用中的 monitor contention,
-- 并且只在其启动阶段。
DROP TABLE IF EXISTS monitor_contention_during_startup;
CREATE VIRTUAL TABLE monitor_contention_during_startup
USING SPAN_JOIN(android_monitor_contention PARTITIONED upid, startups PARTITIONED upid);
SELECT
process_name,
-- 将持续时间从纳秒转换为毫秒
SUM(dur) / 1000000 AS sum_dur_ms,
COUNT(*) AS count_contention
FROM monitor_contention_during_startup
WHERE is_blocked_thread_main
GROUP BY process_name
ORDER BY SUM(dur) DESC;作为 debug tracks 的进程调度组
演示内容:
- 使用子字符串替换将字符串列投影到一个或多个列。
- 在 Perfetto Timeline 视图中创建自定义 Debug Tracks。
- Views。
PARTITION以按另一列值细分 slices。LEAD以按时间戳顺序查找分区中的下一个事件。
Android 的 system_server 将不同的应用进程分类为不同的调度组。这用于将更多系统资源导向更多用户可见或对延迟敏感的应用(如 "top" 或 "foreground" 应用),并远离在后台执行延迟不敏感任务的其他进程。
system_server 将以以下格式发出 slices:
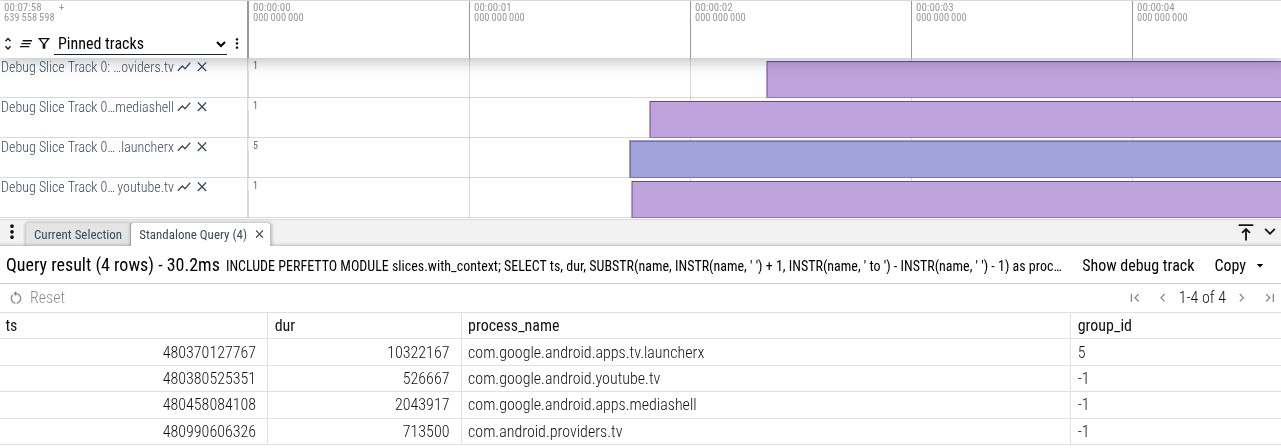
setProcessGroup <process> to <group>使用 PerfettoSQL,你可以将这些字符串转换为结构化数据:
INCLUDE PERFETTO MODULE slices.with_context;
SELECT
ts,
dur,
SUBSTR(name, INSTR(name, ' ') + 1, INSTR(name, ' to ') - INSTR(name, ' ') - 1) as process_name,
SUBSTR(name, INSTR(name, ' to ') + 4) AS group_id
FROM thread_slice
WHERE process_name = 'system_server'
AND thread_name = 'OomAdjuster'
AND name LIKE 'setProcessGroup %';使用 debug tracks,你可以将此信息添加到 Timeline。按下 "Show timeline"。在底部栏中,按下 "Show debug track" 并配置:
- Track type: counter
- ts:
ts - value:
group_id - pivot:
process_name

按下 "Show",你将看到从结果生成的 debug tracks:
组的整数值在 SchedPolicy 中枚举,位于
system/core/libprocessgroup/include/processgroup/sched_policy.h。
你可以将数值投影为字符串名称:
INCLUDE PERFETTO MODULE slices.with_context;
SELECT
ts,
dur,
SUBSTR(name, INSTR(name, ' ') + 1, INSTR(name, ' to ') - INSTR(name, ' ') - 1) as process_name,
-- Resolve SchedPolicy
CASE SUBSTR(name, INSTR(name, ' to ') + 4)
WHEN '-1' THEN 'SP_DEFAULT'
WHEN '0' THEN 'SP_BACKGROUND'
WHEN '1' THEN 'SP_FOREGROUND'
WHEN '2' THEN 'SP_SYSTEM'
WHEN '3' THEN 'SP_AUDIO_APP'
WHEN '4' THEN 'SP_AUDIO_SYS'
WHEN '5' THEN 'SP_TOP_APP'
WHEN '6' THEN 'SP_RT_APP'
WHEN '7' THEN 'SP_RESTRICTED'
WHEN '8' THEN 'SP_FOREGROUND_WINDOW'
ELSE SUBSTR(name, INSTR(name, ' to ') + 4)
END AS group_name
FROM thread_slice
WHERE process_name = 'system_server'
AND thread_name = 'OomAdjuster'
AND name LIKE 'setProcessGroup %';配置 debug track:
你将看到带有可读名称的 debug tracks:

你会注意到一个问题 - tracks 的持续时间是短暂的。持续时间仅表示 system_server 更改这些进程的进程组所花费的时间。你可能希望看到进程在该组中的持续时间,即持续时间应延伸到下一次组更新或 trace 结束。你可以使用 LEAD 通过查找下一个 slice(按 process_name 分区)来实现这一点。
INCLUDE PERFETTO MODULE slices.with_context;
-- 创建一个视图,以便我们可以在以下查询中引用 next_ts
DROP VIEW IF EXISTS setProcessGroup;
CREATE VIEW setProcessGroup AS
SELECT
ts,
dur,
SUBSTR(name, INSTR(name, ' ') + 1, INSTR(name, ' to ') - INSTR(name, ' ') - 1) as process_name,
LEAD(ts) OVER (PARTITION BY SUBSTR(name, INSTR(name, ' ') + 1, INSTR(name, ' to ') - INSTR(name, ' ') - 1) ORDER BY ts) AS next_ts,
-- Resolve SchedPolicy
CASE SUBSTR(name, INSTR(name, ' to ') + 4)
WHEN '-1' THEN 'SP_DEFAULT'
WHEN '0' THEN 'SP_BACKGROUND'
WHEN '1' THEN 'SP_FOREGROUND'
WHEN '2' THEN 'SP_SYSTEM'
WHEN '3' THEN 'SP_AUDIO_APP'
WHEN '4' THEN 'SP_AUDIO_SYS'
WHEN '5' THEN 'SP_TOP_APP'
WHEN '6' THEN 'SP_RT_APP'
WHEN '7' THEN 'SP_RESTRICTED'
WHEN '8' THEN 'SP_FOREGROUND_WINDOW'
ELSE SUBSTR(name, INSTR(name, ' to ') + 4)
END AS group_name
FROM thread_slice
WHERE process_name = 'system_server'
AND thread_name = 'OomAdjuster'
AND name LIKE 'setProcessGroup %';
SELECT
ts,
dur,
process_name,
group_name,
next_ts,
IIF(
next_ts IS NOT NULL,
-- Duration 是从 ts 到 next_ts
next_ts - ts,
-- Duration 是从 ts 到本 trace 中看到的最后一个时间戳
(SELECT MAX(ts + dur) FROM slice) - ts
) AS dur_until_next
FROM setProcessGroup;再次配置你的 debug tracks:

debug tracks 现在应该如下所示:

这里有一个来自更繁忙 trace 的示例,你可以看到同一进程被分配到不同的组:

后台作业的状态
使用 Perfetto 中的 android_job_scheduler_states 表来收集作业的 job duration 和 error metrics,以识别后台作业是否按预期运行。
演示内容:
- 按进程过滤
- 使用 Perfetto 标准库表
- 为 SQL 查询包含 Perfetto 模块
- 使用
time_to_ms函数将持续时间转换为毫秒
JobScheduler 是一个 Android 系统服务,可帮助应用高效地安排后台任务(如数据同步或文件下载)。在 Android 开发中,Background jobs 通常指应用需要执行的任何不直接与用户界面交互的工作。这可能包括与服务器同步数据、下载文件、处理图像、发送分析或执行数据库操作等任务。
要在 android_job_scheduler_states 表中收集后台作业的数据,你需要在采集 traces 时在 Perfetto 配置中包含以下代码段:
data_sources {
config {
name: "android.statsd"
statsd_tracing_config {
push_atom_id: ATOM_SCHEDULED_JOB_STATE_CHANGED
}
}
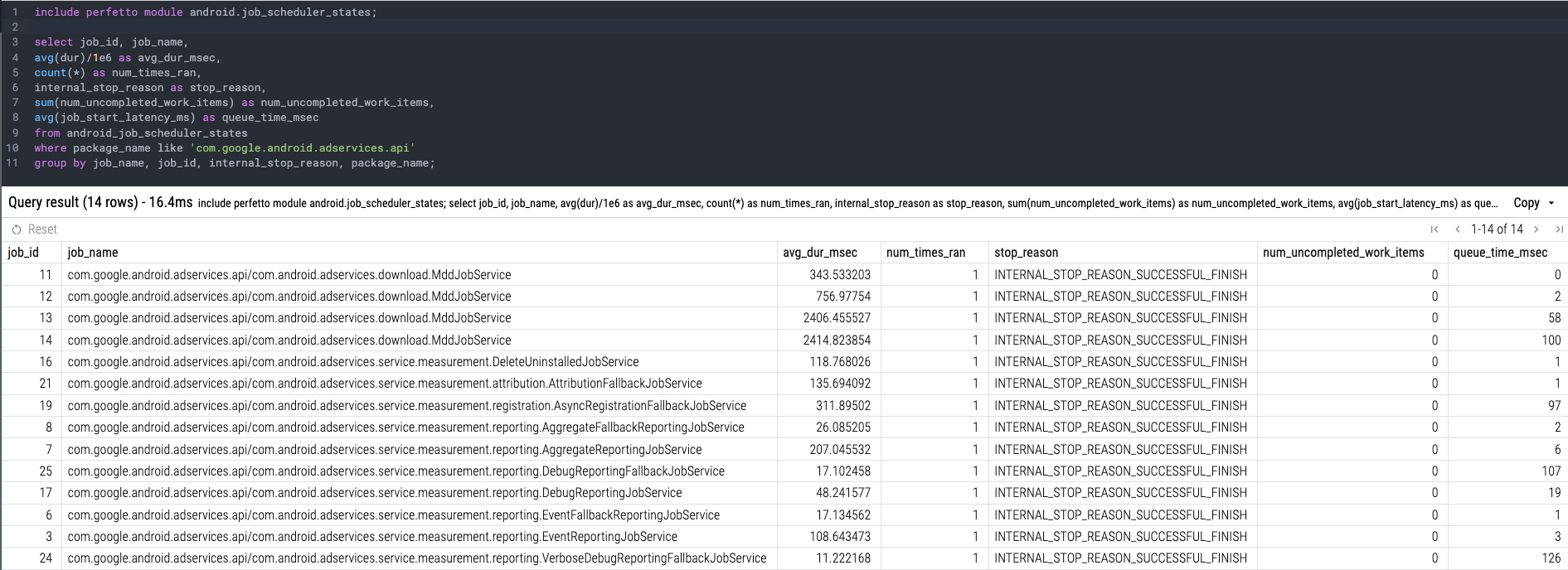
}INCLUDE PERFETTO MODULE android.job_scheduler_states;
SELECT
job_id,
job_name,
AVG(time_to_ms(dur)) AS avg_dur_ms,
COUNT(*) AS num_times_ran,
internal_stop_reason AS stop_reason,
SUM(num_uncompleted_work_items) AS num_uncompleted_work_items,
AVG(job_start_latency_ms) AS queue_time_ms
FROM android_job_scheduler_states
WHERE package_name = 'com.google.android.adservices.api'
GROUP BY job_name, job_id, internal_stop_reason, package_name;长持续时间、频繁的错误和重试表明你的后台作业本身存在问题(例如,代码中的错误、未处理的异常、不正确的数据处理)。它们可能导致用户设备上的资源消耗增加、电池消耗和数据使用增加。
长队列时间意味着你的后台作业等待执行的时间过长。这可能会产生下游影响。例如,如果作业负责同步用户数据,长队列时间可能导致向用户显示过时信息或关键更新延迟。
结果
获取 CPU 利用率和处理信息
要收集与 CPU 上的事件和利用率相关的数据,你需要在采集 traces 时在 Perfetto 配置中包含以下代码段:
data_sources {
config {
name: "linux.ftrace"
ftrace_config {
ftrace_events: "sched/sched_process_exit"
ftrace_events: "sched/sched_process_free"
ftrace_events: "task/task_newtask"
ftrace_events: "task/task_rename"
ftrace_events: "sched/sched_switch"
ftrace_events: "power/suspend_resume"
ftrace_events: "sched/sched_blocked_reason"
ftrace_events: "sched/sched_wakeup"
ftrace_events: "sched/sched_wakeup_new"
ftrace_events: "sched/sched_waking"
ftrace_events: "sched/sched_process_exit"
ftrace_events: "sched/sched_process_free"
ftrace_events: "task/task_newtask"
ftrace_events: "task/task_rename"
ftrace_events: "power/cpu_frequency"
ftrace_events: "power/cpu_idle"
ftrace_events: "power/suspend_resume"
symbolize_ksyms: true
disable_generic_events: true
}
}
}
data_sources {
config {
name: "linux.process_stats"
process_stats_config {
scan_all_processes_on_start: true
}
}
}
data_sources {
config {
name: "linux.sys_stats"
sys_stats_config {
cpufreq_period_ms: 250
}
}
}进程级 CPU 利用率
Android 设备的 CPU 利用率是指设备 CPU 积极工作以执行指令和运行程序的时间百分比。CPU 利用率可以使用 CPU cycles 来衡量,它直接与 CPU 完成任务所花费的时间成正比。特定 Android 进程的高 CPU 利用率表明它正在占用 CPU 处理能力的很大一部分。
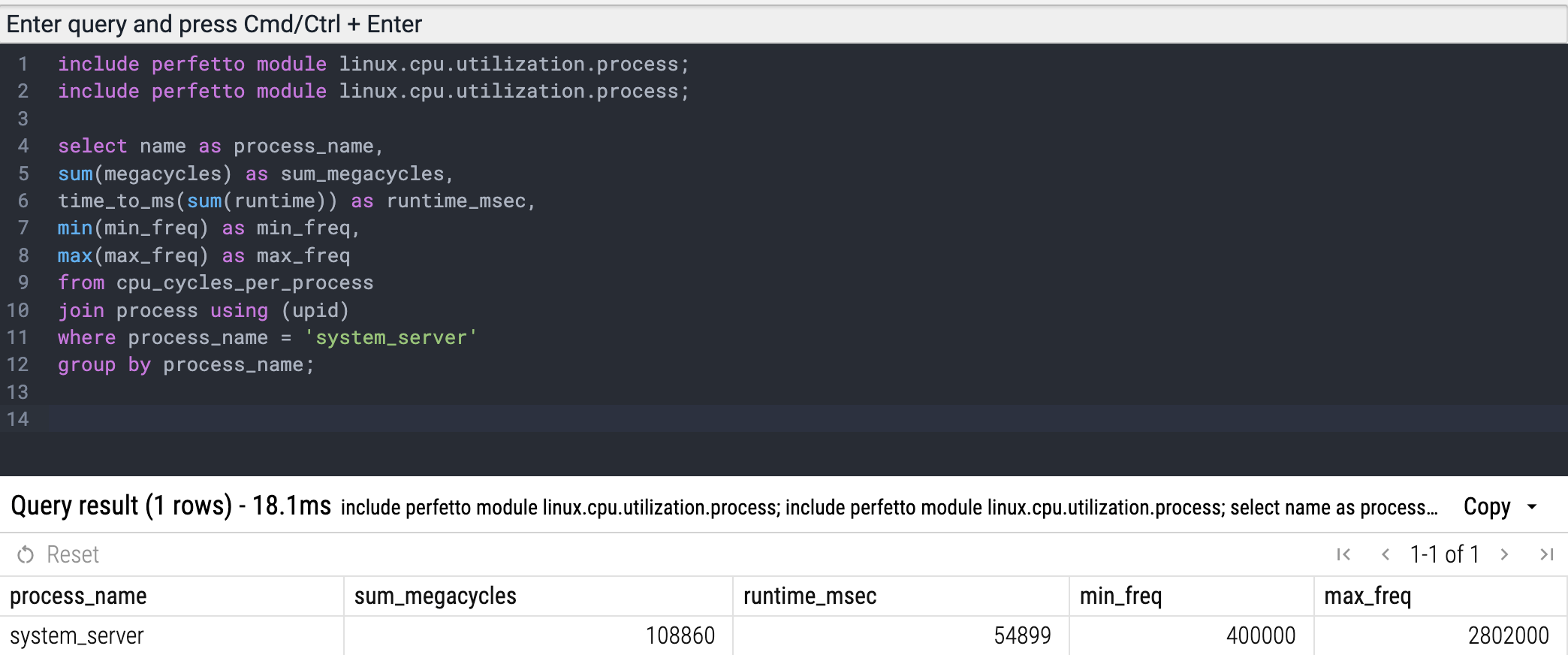
INCLUDE PERFETTO MODULE linux.cpu.utilization.process;
select
name AS process_name,
SUM(megacycles) AS sum_megacycles,
time_to_ms(SUM(runtime)) AS runtime_msec,
MIN(min_freq) AS min_freq,
MAX(max_freq) AS max_freq
FROM cpu_cycles_per_process
JOIN process USING (upid)
WHERE process_name = 'system-server'
GROUP BY process_name;结果:
Slice 级 CPU 利用率
要查看感兴趣 slice 的 cpu 利用率,请使用以下查询:
INCLUDE PERFETTO MODULE linux.cpu.utilization.slice;
select
slice_name,
SUM(megacycles)
FROM cpu_cycles_per_thread_slice
WHERE slice_name GLOB '*interesting_slice*' -- 或 cpu_cycles_per_thread_slice.id=<id of interesting slice>
GROUP BY slice_name;或检查你进程的所有 slices 的 slice 利用率:
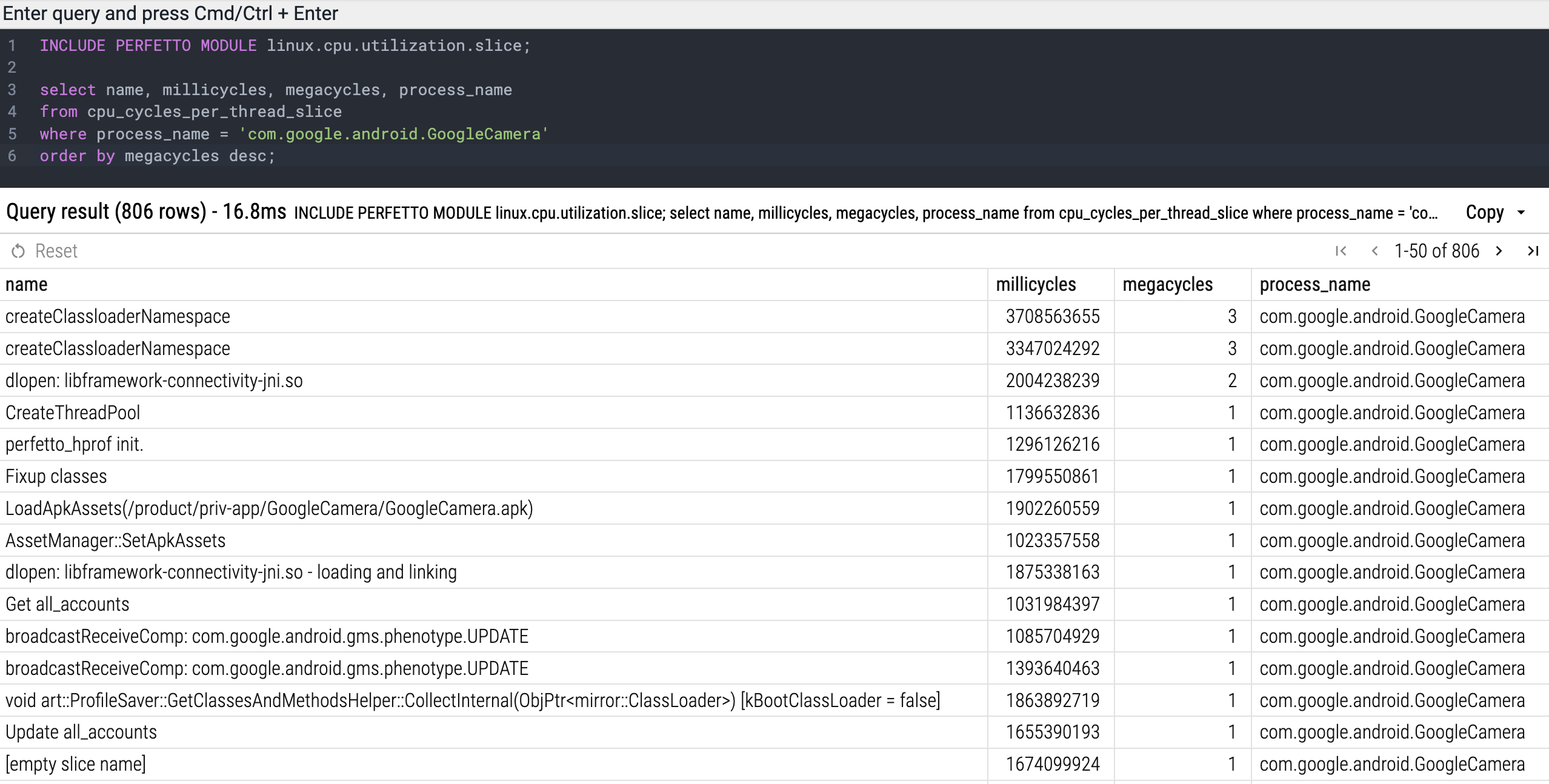
INCLUDE PERFETTO MODULE linux.cpu.utilization.slice;
SELECT
name,
millicycles,
megacycles,
process_name
FROM cpu_cycles_per_thread_slice
WHERE process_name = 'com.google.android.GoogleCamera'
ORDER BY megacycles DESC;结果:
CPU 退出空闲状态的次数
当 CPU 空闲时,它会进入低功耗状态以节省能源。唤醒会中断此状态,迫使 CPU 增加其活动并消耗更多电量。
在 trace 持续时间内 CPU 退出空闲状态的次数:
select
COUNT(*) as num_idle_exits
FROM counter AS c
LEFT JOIN cpu_counter_track AS t
ON c.track_id = t.id
WHERE t.name = 'cpuidle'
AND value = 4294967295;值 4294967295 (0xffffffff) 表示 back to not-idle。
当进程过度将 CPU 从空闲状态唤醒时,可能会产生以下不利影响:
- 电池消耗:频繁的唤醒可能会显著消耗电池
- 延迟:将 CPU 从空闲状态唤醒会引入延迟,因为 CPU 需要一段时间才能从低功耗状态转换到活动状态。
- 上下文切换:每次唤醒可能涉及上下文切换,其中 CPU 必须保存当前任务的状态并加载新任务的状态,进一步增加开销。
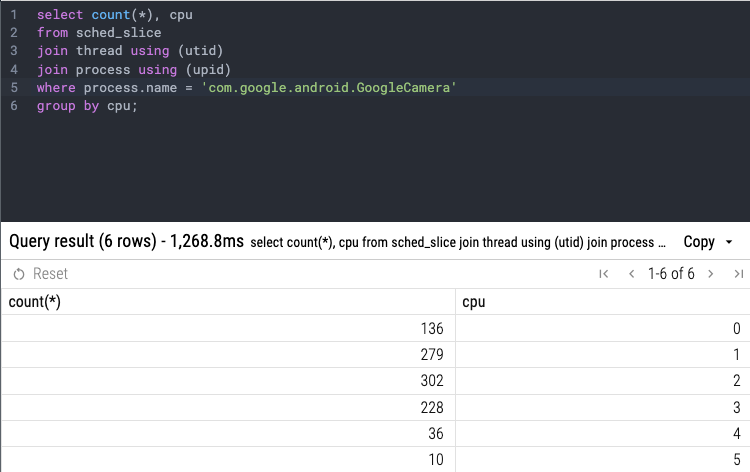
你的进程在 CPU 上调度的事件数
要查看你的进程线程是否在可用的 CPU 核心之间均匀分布,你可以检查你的进程在每个 CPU 核心上调度的事件数:
SELECT
COUNT(*),
cpu
FROM sched_slice
JOIN thread USING (utid)
JOIN process USING (upid)
WHERE process.name = 'com.google.android.GoogleCamera'
GROUP BY cpu;结果: