
以编程方式生成 trace 的高级指南
本文档作为以编程方式创建 Perfetto trace 文件的高级参考。它基于"将任意时间戳数据转换为 Perfetto"中介绍的基本概念和示例。
我们假设你熟悉:
- Perfetto traces 的基本结构(包含
TracePacket消息流的Trace消息) - 在
TracePacket中使用TrackEvent有效负载创建具有各种类型的 Slice(简单、嵌套、异步)、Counter 和流程的自定义 Track - 用于生成 trace 的 Python 脚本模板(
trace_converter_template.py),并且此处提供的 Python 示例旨在在其populate_packets(builder)函数中使用。
本指南目前将专注于高级 TrackEvent 功能,例如:
- 将你的 Timeline 数据与操作系统(OS)进程和线程相关联,以实现更丰富的集成。
- 显式 Track 排序和数据驻留,以优化 trace 大小和细节。
虽然 TrackEvent 是表示 Timeline 数据的主要方法,但 TracePacket 是一个多功能容器。将来,本指南可能会扩展以涵盖其他对合成 trace 生成有用的 TracePacket 有效负载。
示例将继续使用 Python,但这些原则适用于任何具有 Protocol Buffer 支持的语言。有关所有可用字段的完整定义,请始终参考官方 Perfetto protobuf 源代码,特别是 TracePacket 及其各种子消息,包括 TrackEvent。
将 Track 与操作系统概念相关联
虽然 "将任意时间戳数据转换为 Perfetto" 指南演示了创建通用自定义 Track,但你可以通过将 Track 与操作系统(OS)进程和线程相关联来为 Perfetto 提供更具体的上下文。这允许 Perfetto 的 UI 和分析工具提供 更丰富的集成和与其他系统范围数据的更好关联。
将 Track 与进程相关联
你可以创建表示操作系统进程的顶级 Track。任何其他自定义 Track(可能包含 Slice 或 Counter)都可以父化到此进程 Track。这有助于:
- UI 分组: 你的自定义 Track 将出现在 Perfetto UI 中指定进程名称和 PID 下,与为该进程收集的任何其他数据(例如,CPU 调度、内存 Counter)一起。
- 关联: 你的自定义 Track 上的事件可以更容易地与与该进程相关的系统级别活动相关联。
- 清晰标识: 明确命名进程并提供其 PID 使你的自定义数据与哪个进程相关变得明确。
要定义进程 Track,请在其 TrackDescriptor 中填充 process 字段。至少,你应该提供 pid,理想情况下还应提供 process_name。
还建议将 timestamp 添加到包含进程的 TrackDescriptor 的 TracePacket 中。这尤其重要,当 trace 包含来自其他源的数据(例如,来自内核的调度信息)时。与"全局"Track 不同,这些 Track 类型可能会与其他数据源交互,因此具有时间戳可确保 Trace Processor 可以准确地将描述符排序到正确的位置。
Python 示例
假设你想发出一个自定义 Counter(例如,"活动数据库连接")并让它出现在名为 "MyDatabaseService" 且 PID 为 1234 的特定进程下。
将以下 Python 代码复制到你的 trace_converter_template.py 脚本中的 populate_packets(builder) 函数中。
单击展开/折叠 Python 代码
TRUSTED_PACKET_SEQUENCE_ID = 8008
# --- 定义 OS 进程 ---
PROCESS_ID = 1234
PROCESS_NAME = "MyDatabaseService"
# 为进程 Track 定义 UUID
process_track_uuid = uuid.uuid4().int & ((1 << 63) - 1)
# 1. 定义进程 Track
# 此数据包在 trace 中建立 "MyDatabaseService (1234)"。
packet = builder.add_packet()
# 最好将描述符的时间戳设置在第一个事件之前。
packet.timestamp = 9999
desc = packet.track_descriptor
desc.uuid = process_track_uuid
desc.process.pid = PROCESS_ID
desc.process.process_name = PROCESS_NAME
# 此 Track 本身通常没有事件,它作为父项。
# --- 定义父化到进程的自定义 Counter Track ---
db_connections_counter_track_uuid = uuid.uuid4().int & ((1 << 63) - 1)
packet = builder.add_packet()
desc = packet.track_descriptor
desc.uuid = db_connections_counter_track_uuid
desc.parent_uuid = process_track_uuid # 链接到进程 Track
desc.name = "活动数据库连接"
# 将此 Track 标记为 Counter Track
desc.counter.unit_name = "connections" # 可选:指定单位
# 添加 Counter 事件的辅助函数
def add_counter_event(ts, value, counter_track_uuid):
packet = builder.add_packet()
packet.timestamp = ts
packet.track_event.type = TrackEvent.TYPE_COUNTER
packet.track_event.track_uuid = counter_track_uuid
packet.track_event.counter_value = value
packet.trusted_packet_sequence_id = TRUSTED_PACKET_SEQUENCE_ID
# 3. 在自定义 Counter Track 上发出 Counter 值
add_counter_event(ts=10000, value=5, counter_track_uuid=db_connections_counter_track_uuid)
add_counter_event(ts=10100, value=7, counter_track_uuid=db_connections_counter_track_uuid)
add_counter_event(ts=10200, value=6, counter_track_uuid=db_connections_counter_track_uuid)如果你只有符号化的函数名称,则仅使用驻留的函数名称 ID 调用 add_frame(...):例如,add_frame(packet.interned_data, FRAME_MAIN, FUNC_MAIN)。
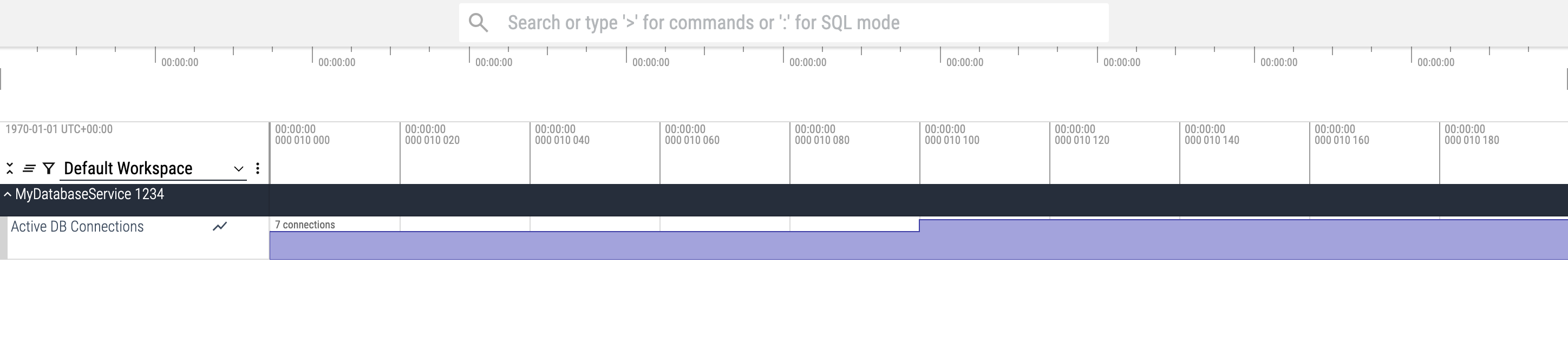
你可以在 Perfetto UI 的 Query 选项卡中使用 SQL 或使用 Trace Processor 查询与进程关联的 Counter 数据:
SELECT counter.ts, counter.value, process.name AS process_name
FROM counter
JOIN process_counter_track ON counter.track_id = process_counter_track.id
JOIN process USING(upid)
WHERE process.pid = 1234;一旦你定义了进程 Track,就可以将各种其他类型的 Track 父化到它。这包括该进程内特定线程的 Track(见下一节),以及进程范围 Counter 的自定义 Track(如上所示)或与此进程相关的异步操作组(使用 "将任意时间戳数据转换为 Perfetto" 指南中描述的异步 Slice 技术)。
将 Track 与线程相关联
你可以创建明确与操作系统进程内特定线程关联的 Track。这是表示线程特定活动(如函数调用堆栈或线程本地 Counter)的最常见方式。
好处:
- 正确的 UI 放置: 当线程 Track 的
pid和tid在其TrackDescriptor中指定时,Perfetto UI 通常将其分组在对应的进程(由该pid标识)下。这有助于组织 trace。 - 与系统数据关联: Perfetto 可以自动将你的线程 Track 上的事件与该线程的系统级别数据(如 CPU 调度 Slice)相关联。
- 清晰命名: 你可以为线程提供人类可读的名称。
要定义线程 Track:
- 为线程创建
TrackDescriptor。 - 填充其
thread字段,提供此线程所属进程的pid和线程的唯一tid。你还应该设置thread_name。 - 可选但鼓励的是,你还可以为父进程本身定义一个单独的
TrackDescriptor(使用其process字段和pid),尽管这不是线程 Track 被识别为该 PID 的线程严格要求的。UI 通常根据线程 Track 中存在的 PID 推断进程分组。
与进程 Track 类似,还建议将 timestamp 添加到包含线程的 TrackDescriptor 的 TracePacket 中。这尤其重要,当 trace 包含来自其他源的数据(例如,来自内核的调度信息)时。与"全局"Track 不同,这些 Track 类型可能会与其他数据源交互,因此具有时间戳可确保 Trace Processor 可以准确地将描述符排序到正确的位置。
Python 示例:特定于线程的 Slice
此示例定义了一个属于进程 "MyApplication" (PID 1234) 的线程 "MainWorkLoop" (TID 5678)。然后,它直接在此线程的 Track 上发出几个 Slice。为了清晰起见,我们还定义了进程本身的 Track,尽管线程 Track 的关联主要通过其 pid 和 tid
字段进行。
将以下 Python 代码复制到你的 trace_converter_template.py 脚本中的 populate_packets(builder) 函数中。
单击展开/折叠 Python 代码
TRUSTED_PACKET_SEQUENCE_ID = 8009
# --- 定义 OS 进程和线程 ID 和名称 ---
APP_PROCESS_ID = 1234
APP_PROCESS_NAME = "MyApplication"
MAIN_THREAD_ID = 5678
MAIN_THREAD_NAME = "MainWorkLoop"
# --- 定义 Track 的 UUID ---
# 虽然不严格要求将线程 Track 父化到进程 Track
# 以便 UI 按 PID 分组它们,但如果你想明确命名进程或稍后附加进程范围的 Track,定义进程 Track 可能是一个好习惯。
app_process_track_uuid = uuid.uuid4().int & ((1 << 63) - 1)
main_thread_track_uuid = uuid.uuid4().int & ((1 << 63) - 1)
# 1. 定义进程 Track(可选,但对命名进程很有用)
packet = builder.add_packet()
packet.timestamp = 14998
desc = packet.track_descriptor
desc.uuid = app_process_track_uuid
desc.process.pid = APP_PROCESS_ID
desc.process.process_name = APP_PROCESS_NAME
# 2. 定义线程 Track
# .thread.pid 字段将其与进程关联。
# 此处未设置 parent_uuid;UI 将按 PID 分组。
packet = builder.add_packet()
packet.timestamp = 14999
desc = packet.track_descriptor
desc.uuid = main_thread_track_uuid
# desc.parent_uuid = app_process_track_uuid # 不使用此行
desc.thread.pid = APP_PROCESS_ID
desc.thread.tid = MAIN_THREAD_ID
desc.thread.thread_name = MAIN_THREAD_NAME
# 将 Slice 事件添加到特定 Track 的辅助函数
def add_slice_event(ts, event_type, event_track_uuid, name=None):
packet = builder.add_packet()
packet.timestamp = ts
packet.track_event.type = event_type
packet.track_event.track_uuid = event_track_uuid
if name:
packet.track_event.name = name
packet.trusted_packet_sequence_id = TRUSTED_PACKET_SEQUENCE_ID
# 3. 在 main_thread_track_uuid 上发出 Slice
add_slice_event(ts=15000, event_type=TrackEvent.TYPE_SLICE_BEGIN,
event_track_uuid=main_thread_track_uuid, name="ProcessInputEvent")
# 嵌套切片
add_slice_event(ts=15050, event_type=TrackEvent.TYPE_SLICE_BEGIN,
event_track_uuid=main_thread_track_uuid, name="UpdateState")
add_slice_event(ts=15150, event_type=TrackEvent.TYPE_SLICE_END, # 结束 UpdateState
event_track_uuid=main_thread_track_uuid)
add_slice_event(ts=15200, event_type=TrackEvent.TYPE_SLICE_END, # 结束 ProcessInputEvent
event_track_uuid=main_thread_track_uuid)
add_slice_event(ts=16000, event_type=TrackEvent.TYPE_SLICE_BEGIN,
event_track_uuid=main_thread_track_uuid, name="RenderFrame")
add_slice_event(ts=16500, event_type=TrackEvent.TYPE_SLICE_END,
event_track_uuid=main_thread_track_uuid)
你可以在 Perfetto UI 的 Query 选项卡中使用 SQL 或使用 Trace Processor 查询特定于线程的 Slice:
INCLUDE PERFETTO MODULE slices.with_context;
SELECT ts, dur, name, thread_name
FROM thread_slice
WHERE tid = 5678;高级 Track 自定义
除了将 Track 与操作系统概念相关联之外,Perfetto 还提供了微调 Track 呈现方式和数据编码方式的方法。
控制 Track 排序顺序
默认情况下,Perfetto UI 应用自己的启发式方法对 Track 进行排序(例如,按名称字母顺序,或按 Track UUID)。但是,对于复杂的自定义 trace,你可能希望明确定义同级 Track 在父 Track 下出现的顺序。这是使用父 Track TrackDescriptor 上的 child_ordering 字段和对于 EXPLICIT 排序使用子 Track TrackDescriptor 上的 sibling_order_rank 来实现的。
父 Track 上的此 child_ordering 设置仅影响其直接子 Track。
可用的 child_ordering 模式(在 TrackDescriptor.ChildTracksOrdering 中定义):
ORDERING_UNSPECIFIED:默认值。UI 将使用自己的启发式方法。LEXICOGRAPHIC:子 Track 按其name字母顺序排序。CHRONOLOGICAL:子 Track 根据其中每一个上发生的最早TrackEvent的时间戳排序。具有较早事件的 Track 首先出现。EXPLICIT:子 Track 根据在各自TrackDescriptor中设置的sibling_order_rank字段排序。排名较低的首先出现。如果排名相等,或者如果未设置sibling_order_rank,则决胜顺序未定义。
注意: UI 将这些视为强提示。虽然它通常尊重这些排序,但在某些情况下,UI 保留不按此顺序显示它们的权利;通常,如果用户明确请求此操作,或者 UI 对这些 Track 有特殊处理,则会发生这种情况。
Python 示例:演示所有排序类型
此示例定义了三个父 Track,每个 Track 演示不同的
child_ordering 模式。
将以下 Python 代码复制到你的 trace_converter_template.py 脚本中的 populate_packets(builder) 函数中。
单击展开/折叠 Python 代码
TRUSTED_PACKET_SEQUENCE_ID = 9000
# 定义 TrackDescriptor 的辅助函数
def define_custom_track(track_uuid, name, parent_track_uuid=None, child_ordering_mode=None, order_rank=None):
packet = builder.add_packet()
desc = packet.track_descriptor
desc.uuid = track_uuid
desc.name = name
if parent_track_uuid:
desc.parent_uuid = parent_track_uuid
if child_ordering_mode:
desc.child_ordering = child_ordering_mode
if order_rank is not None:
desc.sibling_order_rank = order_rank
# 添加简单瞬时事件的辅助函数
def add_instant_event(ts, track_uuid, event_name):
packet = builder.add_packet()
packet.timestamp = ts
packet.track_event.type = TrackEvent.TYPE_INSTANT
packet.track_event.track_uuid = track_uuid
packet.track_event.name = event_name
packet.trusted_packet_sequence_id = TRUSTED_PACKET_SEQUENCE_ID
# --- 1. 字典排序示例 ---
parent_lex_uuid = uuid.uuid4().int & ((1 << 63) - 1)
define_custom_track(parent_lex_uuid, "字典排序父级",
child_ordering_mode=TrackDescriptor.LEXICOGRAPHIC)
child_c_lex_uuid = uuid.uuid4().int & ((1 << 63) - 1)
child_a_lex_uuid = uuid.uuid4().int & ((1 << 63) - 1)
child_b_lex_uuid = uuid.uuid4().int & ((1 << 63) - 1)
define_custom_track(child_c_lex_uuid, "C-项(字典)", parent_track_uuid=parent_lex_uuid)
define_custom_track(child_a_lex_uuid, "A-项(字典)", parent_track_uuid=parent_lex_uuid)
define_custom_track(child_b_lex_uuid, "B-项(字典)", parent_track_uuid=parent_lex_uuid)
add_instant_event(ts=100, track_uuid=child_c_lex_uuid, event_name="事件 C")
add_instant_event(ts=100, track_uuid=child_a_lex_uuid, event_name="事件 A")
add_instant_event(ts=100, track_uuid=child_b_lex_uuid, event_name="事件 B")
# "字典排序父级"下的预期 UI 顺序:A-项、B-项、C-项
# --- 2. 按时间排序示例 ---
parent_chrono_uuid = uuid.uuid4().int & ((1 << 63) - 1)
define_custom_track(parent_chrono_uuid, "按时间排序父级",
child_ordering_mode=TrackDescriptor.CHRONOLOGICAL)
child_late_uuid = uuid.uuid4().int & ((1 << 63) - 1)
child_early_uuid = uuid.uuid4().int & ((1 << 63) - 1)
child_middle_uuid = uuid.uuid4().int & ((1 << 63) - 1)
define_custom_track(child_late_uuid, "晚事件 Track", parent_track_uuid=parent_chrono_uuid)
define_custom_track(child_early_uuid, "早事件 Track", parent_track_uuid=parent_chrono_uuid)
define_custom_track(child_middle_uuid, "中事件 Track", parent_track_uuid=parent_chrono_uuid)
add_instant_event(ts=2000, track_uuid=child_late_uuid, event_name="晚事件")
add_instant_event(ts=1000, track_uuid=child_early_uuid, event_name="早事件")
add_instant_event(ts=1500, track_uuid=child_middle_uuid, event_name="中事件")
# "按时间排序父级"下的预期 UI 顺序:早事件 Track、中事件 Track、晚事件 Track
# --- 3. 显式排序示例 ---
parent_explicit_uuid = uuid.uuid4().int & ((1 << 63) - 1)
define_custom_track(parent_explicit_uuid, "显式排序父级",
child_ordering_mode=TrackDescriptor.EXPLICIT)
child_rank10_uuid = uuid.uuid4().int & ((1 << 63) - 1)
child_rank_neg5_uuid = uuid.uuid4().int & ((1 << 63) - 1)
child_rank0_uuid = uuid.uuid4().int & ((1 << 63) - 1)
define_custom_track(child_rank10_uuid, "显式排名 10",
parent_track_uuid=parent_explicit_uuid, order_rank=10)
define_custom_track(child_rank_neg5_uuid, "显式排名 -5",
parent_track_uuid=parent_explicit_uuid, order_rank=-5)
define_custom_track(child_rank0_uuid, "显式排名 0",
parent_track_uuid=parent_explicit_uuid, order_rank=0)
add_instant_event(ts=3000, track_uuid=child_rank10_uuid, event_name="事件排名 10")
add_instant_event(ts=3000, track_uuid=child_rank_neg5_uuid, event_name="事件排名 -5")
add_instant_event(ts=3000, track_uuid=child_rank0_uuid, event_name="事件排名 0")
# "显式排序父级"下的预期 UI 顺序:排名 -5、排名 0、排名 10
在 Counters 之间共享 Y 轴
在可视化多个 Counter Tracks 时,让它们共享相同的 Y 轴范围通常很有用。这允许轻松比较它们的值。Perfetto 通过 CounterDescriptor 中的 y_axis_share_key 字段支持此功能。
所有具有相同 y_axis_share_key 和相同父 Track 的 Counter Tracks 将在 UI 中共享它们的 Y 轴范围。
Python 示例:共享 Y 轴
在此示例中,我们创建两个具有相同 y_axis_share_key 的 Counter Tracks。这将导致它们在 Perfetto UI 中使用相同的 Y 轴范围进行渲染。
单击展开/折叠 Python 代码
TRUSTED_PACKET_SEQUENCE_ID = 9005
# --- 定义 Track UUID ---
counter1_uuid = 1
counter2_uuid = 2
# 定义 Counter Track TrackDescriptor 的辅助函数
def define_counter_track(track_uuid, name, share_key=None):
packet = builder.add_packet()
desc = packet.track_descriptor
desc.uuid = track_uuid
desc.name = name
if share_key:
desc.counter.y_axis_share_key = share_key
# 1. 定义具有相同共享密钥的 Counter Track
define_counter_track(counter1_uuid, "Counter 1", "group1")
define_counter_track(counter2_uuid, "Counter 2", "group1")
# 添加 Counter 事件的辅助函数
def add_counter_event(ts, value, counter_track_uuid):
packet = builder.add_packet()
packet.timestamp = ts
packet.track_event.type = TrackEvent.TYPE_COUNTER
packet.track_event.track_uuid = counter_track_uuid
packet.track_event.counter_value = value
packet.trusted_packet_sequence_id = TRUSTED_PACKET_SEQUENCE_ID
# 2. 向 Track 添加事件
add_counter_event(ts=1000, value=100, counter_track_uuid=counter1_uuid)
add_counter_event(ts=2000, value=200, counter_track_uuid=counter1_uuid)
add_counter_event(ts=1000, value=300, counter_track_uuid=counter2_uuid)
add_counter_event(ts=2000, value=400, counter_track_uuid=counter2_uuid)
添加 Track 描述:
你可以向任何 Track 添加人类可读的描述,以提供有关其包含数据的更多上下文。在 Perfetto UI 中,当用户单击 Track 名称旁边的帮助图标时,此描述会出现在弹出窗口中。这对于解释 Track 代表什么、其事件的含义或应如何解释它特别有用,尤其是在复杂的自定义 trace 中。
要添加描述,只需在 Track 的 TrackDescriptor 中设置可选的 description 字段。
Python 示例
此示例定义了两个 Track:一个设置了 description 字段,一个没有,以说明 UI 中的差异。
将以下 Python 代码复制到你的 trace_converter_template.py 脚本中的 populate_packets(builder) 函数中。
单击展开/折叠 Python 代码
TRUSTED_PACKET_SEQUENCE_ID = 9005
# --- 定义 Track UUID ---
described_track_uuid = uuid.uuid4().int & ((1 << 63) - 1)
undescribed_track_uuid = uuid.uuid4().int & ((1 << 63) - 1)
# --- 1. 定义两个 Track,一个有描述,一个没有 ---
# 带描述的 Track
packet = builder.add_packet()
desc = packet.track_descriptor
desc.uuid = described_track_uuid
desc.name = "带描述的 Track"
desc.description = "此 Track 显示传入用户请求的处理阶段。单击 (?) 图标查看此文本。"
# 不带描述的 Track
packet = builder.add_packet()
desc = packet.track_descriptor
desc.uuid = undescribed_track_uuid
desc.name = "不带描述的 Track"
# 'description' 字段只是未设置。
# 将 Slice 事件添加到 Track 的辅助函数
def add_slice_event(ts, event_type, event_track_uuid, name=None):
packet = builder.add_packet()
packet.timestamp = ts
packet.track_event.type = event_type
packet.track_event.track_uuid = event_track_uuid
if name:
packet.track_event.name = name
packet.trusted_packet_sequence_id = TRUSTED_PACKET_SEQUENCE_ID
# --- 2. 在两个 Track 上发出一些事件 ---
# 带描述 Track 的事件
add_slice_event(ts=1000, event_type=TrackEvent.TYPE_SLICE_BEGIN,
event_track_uuid=described_track_uuid, name="请求 #123")
add_slice_event(ts=1200, event_type=TrackEvent.TYPE_SLICE_END,
event_track_uuid=described_track_uuid)
# 不带描述 Track 的事件
add_slice_event(ts=1300, event_type=TrackEvent.TYPE_SLICE_BEGIN,
event_track_uuid=undescribed_track_uuid, name="其他一些任务")
add_slice_event(ts=1500, event_type=TrackEvent.TYPE_SLICE_END,
event_track_uuid=undescribed_track_uuid)
高级事件写入
本节涵盖了专业用例的高级 TrackEvent 功能,包括数据优化技术和事件链接机制。
驻留数据以优化 trace 大小
驻留是一种通过仅在 trace 中发出一次频繁重复的字符串(如事件名称或类别)来减少 trace 文件大小的技术。对这些字符串的后续引用使用紧凑的整数标识符("驻留 ID"或 iid)。当你有许多事件共享相同名称或其他基于字符串的属性时,这特别有用。
它如何工作:
- 定义驻留数据: 在
TracePacket中,你包含一个interned_data消息。在其中,你将字符串映射到iids。例如,你可以定义event_names,其中每个条目都有一个iid(你选择的一个非零整数)和一个name字符串。此数据包_建立_映射。 - 通过 IID 引用: 在后续的
TrackEvent中(在相同的trusted_packet_sequence_id内且在驻留状态被清除之前), 你不是直接设置name字段,而是将相应的name_iid字段设置为你定义的整数iid。 - 序列标志:
TracePacket.sequence_flags字段至关重要:
SEQ_INCREMENTAL_STATE_CLEARED(值 1):在处理此数据包的interned_data之前,如果应将此序列的驻留字典(和其他增量状态)视为已重置,请在此数据包上设置。这通常用于定义驻留条目的序列的第一个数据包上。SEQ_NEEDS_INCREMENTAL_STATE(值 2):在_定义新驻留数据条目或使用在先前数据包中(在序列的当前有效状态内)定义的 iid_的任何数据包上设置此数据包。
通常为序列_初始化_驻留字典的数据包将设置两个标志:
TracePacket.SEQ_INCREMENTAL_STATE_CLEARED | TracePacket.SEQ_NEEDS_INCREMENTAL_STATE。
_使用_这些已建立的驻留条目(或向现有的有效字典添加更多条目)的数据包将设置
TracePacket.SEQ_NEEDS_INCREMENTAL_STATE。
Python 示例:驻留事件名称
此示例显示如何为事件名称定义驻留字符串,然后多次使用它。
将以下 Python 代码复制到你的 trace_converter_template.py 脚本中的 populate_packets(builder) 函数中。
单击展开/折叠 Python 代码
TRUSTED_PACKET_SEQUENCE_ID = 9002
# --- 定义 Track UUID ---
interning_track_uuid = uuid.uuid4().int & ((1 << 63) - 1)
# 定义 TrackDescriptor 的辅助函数
def define_custom_track(track_uuid, name):
packet = builder.add_packet()
desc = packet.track_descriptor
desc.uuid = track_uuid
desc.name = name
# 1. 定义 Track
define_custom_track(interning_track_uuid, "驻留演示 Track")
# --- 定义驻留事件名称 ---
INTERNED_EVENT_NAME_IID = 1 # 选择唯一的 iid(非零)
VERY_LONG_EVENT_NAME = "MyFrequentlyRepeatedLongEventNameThatTakesUpSpace"
# 添加 TrackEvent 数据包的辅助函数,管理驻留和序列标志
def add_slice_with_interning(ts, event_type, name_iid=None, name_literal=None, define_new_internment=False, new_intern_iid=None, new_intern_name=None):
packet = builder.add_packet()
packet.timestamp = ts
tev = packet.track_event
tev.type = event_type
tev.track_uuid = interning_track_uuid
if name_iid:
tev.name_iid = name_iid
elif name_literal and event_type != TrackEvent.TYPE_SLICE_END:
tev.name = name_literal
if define_new_internment:
# 此数据包定义新的驻留数据。
# 我们还将清除此序列的任何先前状态。
if new_intern_iid and new_intern_name:
entry = packet.interned_data.event_names.add()
entry.iid = new_intern_iid
entry.name = new_intern_name
packet.sequence_flags = TracePacket.SEQ_INCREMENTAL_STATE_CLEARED | TracePacket.SEQ_NEEDS_INCREMENTAL_STATE
else:
# 此数据包使用现有的驻留数据(或没有驻留字段)
# 但是依赖增量状态的序列的一部分。
packet.sequence_flags = TracePacket.SEQ_NEEDS_INCREMENTAL_STATE
packet.trusted_packet_sequence_id = TRUSTED_PACKET_SEQUENCE_ID
return packet
# --- 数据包 1:定义驻留名称并使用它开始 Slice ---
add_slice_with_interning(
ts=1000,
event_type=TrackEvent.TYPE_SLICE_BEGIN,
name_iid=INTERNED_EVENT_NAME_IID,
define_new_internment=True, # 此数据包定义/重置驻留
new_intern_iid=INTERNED_EVENT_NAME_IID,
new_intern_name=VERY_LONG_EVENT_NAME
)
# 结束第一个切片
add_slice_with_interning(
ts=1100,
event_type=TrackEvent.TYPE_SLICE_END
# 结束不需要 name_iid,使用现有的驻留状态上下文
)
# --- 数据包 2:再次使用驻留事件名称 ---
add_slice_with_interning(
ts=1200,
event_type=TrackEvent.TYPE_SLICE_BEGIN,
name_iid=INTERNED_EVENT_NAME_IID # 重复使用 iid
# define_new_internment 默认为 False,因此这使用现有状态
)
# 结束第二个切片
add_slice_with_interning(
ts=1300,
event_type=TrackEvent.TYPE_SLICE_END
)
驻留调用堆栈
入门指南 涵盖了简单用例的内联调用堆栈。本节涵盖了高效驻留调用堆栈,用于调用堆栈重复或需要二进制映射信息进行符号化的情况。
驻留调用堆栈在 InternedData 中定义一次调用堆栈结构,并从多个事件中通过 ID 引用它。至少你只需要定义:
帧、调用堆栈,并从你的事件中引用这些调用堆栈。其他部分是可选的,当你拥有该信息时可以提供:
- 构建 ID 和 映射路径 → 映射(二进制文件/库)。如果你没有二进制元数据,则可以完全跳过此内容。
- 映射 → 帧(函数 + 位置)。
mapping_id、rel_pc、source_file_id、line_number等都是可选的——只设置对你的数据有意义的部分。 - 帧 → 调用堆栈(帧序列)
- 调用堆栈 → 事件(通过
callstack_iid)
Python 示例:驻留调用堆栈
此示例演示了驻留调用堆栈的完整工作流程,包括映射、帧和调用堆栈。对于最小 trace,你可以跳过映射条目,并仅使用函数名称(以及你拥有的任何位置详细信息)填充帧。
将以下 Python 代码复制到你的 trace_converter_template.py 脚本中的 populate_packets(builder) 函数中。
单击展开/折叠 Python 代码
from perfetto.protos.perfetto.trace.perfetto_trace_pb2 import TracePacket
TRUSTED_PACKET_SEQUENCE_ID = 9001
# --- 定义 Track UUID ---
interned_callstack_track_uuid = uuid.uuid4().int & ((1 << 63) - 1)
def add_function_name(entry, iid, name):
item = entry.function_names.add()
item.iid = iid
item.str = name.encode()
def add_mapping(entry, iid, build_id, start, end, path_id):
mapping_entry = entry.mappings.add()
mapping_entry.iid = iid
mapping_entry.build_id = build_id
mapping_entry.exact_offset = 0
mapping_entry.start = start
mapping_entry.end = end
mapping_entry.load_bias = 0
mapping_entry.path_string_ids.append(path_id)
def add_frame(entry, iid, function_name_id, mapping_id=None, rel_pc=None):
frame_entry = entry.frames.add()
frame_entry.iid = iid
frame_entry.function_name_id = function_name_id
if mapping_id is not None:
frame_entry.mapping_id = mapping_id
if rel_pc is not None:
frame_entry.rel_pc = rel_pc
def add_callstack(entry, iid, frame_ids):
callstack_entry = entry.callstacks.add()
callstack_entry.iid = iid
callstack_entry.frame_ids.extend(frame_ids)
def emit_track_event(
ts,
event_type,
name,
callstack_iid,
):
packet = builder.add_packet()
packet.timestamp = ts
packet.track_event.type = event_type
packet.track_event.track_uuid = interned_callstack_track_uuid
if name is not None:
packet.track_event.name = name
if callstack_iid is not None:
packet.track_event.callstack_iid = callstack_iid
packet.sequence_flags = TracePacket.SEQ_NEEDS_INCREMENTAL_STATE
packet.trusted_packet_sequence_id = TRUSTED_PACKET_SEQUENCE_ID
# 1. 定义 Track
packet = builder.add_packet()
desc = packet.track_descriptor
desc.uuid = interned_callstack_track_uuid
desc.name = "驻留调用堆栈演示"
# 2. 定义驻留数据(映射、帧、调用堆栈)
# 我们将在单个数据包中创建它,以初始化驻留状态
packet = builder.add_packet()
packet.trusted_packet_sequence_id = TRUSTED_PACKET_SEQUENCE_ID
packet.sequence_flags = (TracePacket.SEQ_INCREMENTAL_STATE_CLEARED |
TracePacket.SEQ_NEEDS_INCREMENTAL_STATE)
# 定义构建 ID
BUILD_ID_APP = 1
BUILD_ID_LIBC = 2
build_id_entry = packet.interned_data.build_ids.add()
build_id_entry.iid = BUILD_ID_APP
build_id_entry.str = b"a1b2c3d4e5f67890" # 十六进制编码的构建 ID
build_id_entry = packet.interned_data.build_ids.add()
build_id_entry.iid = BUILD_ID_LIBC
build_id_entry.str = b"1234567890abcdef"
# 定义映射路径
PATH_APP = 1
PATH_LIBC = 2
path_entry = packet.interned_data.mapping_paths.add()
path_entry.iid = PATH_APP
path_entry.str = b"/usr/bin/myapp"
path_entry = packet.interned_data.mapping_paths.add()
path_entry.iid = PATH_LIBC
path_entry.str = b"/lib/x86_64-linux-gnu/libc.so.6"
# 定义映射
MAPPING_APP = 1
MAPPING_LIBC = 2
add_mapping(packet.interned_data, MAPPING_APP, BUILD_ID_APP, 0x400000, 0x500000, PATH_APP)
add_mapping(packet.interned_data, MAPPING_LIBC, BUILD_ID_LIBC, 0x7F0000000000, 0x7F0000200000, PATH_LIBC)
# 定义帧
FUNC_MAIN = 1
FUNC_PROCESS_REQUESTS = 2
FUNC_HANDLE_REQUEST = 3
FUNC_MALLOC = 4
add_function_name(packet.interned_data, FUNC_MAIN, "main")
add_function_name(packet.interned_data, FUNC_PROCESS_REQUESTS, "ProcessRequests")
add_function_name(packet.interned_data, FUNC_HANDLE_REQUEST, "HandleRequest")
add_function_name(packet.interned_data, FUNC_MALLOC, "malloc")
FRAME_MAIN = 1
FRAME_PROCESS_REQUESTS = 2
FRAME_HANDLE_REQUEST = 3
FRAME_MALLOC = 4
add_frame(packet.interned_data, FRAME_MAIN, FUNC_MAIN, MAPPING_APP, 0x1234)
add_frame(packet.interned_data, FRAME_PROCESS_REQUESTS, FUNC_PROCESS_REQUESTS, MAPPING_APP, 0x2345)
add_frame(packet.interned_data, FRAME_HANDLE_REQUEST, FUNC_HANDLE_REQUEST, MAPPING_APP, 0x3456)
add_frame(packet.interned_data, FRAME_MALLOC, FUNC_MALLOC, MAPPING_LIBC, 0x8765)
# 定义调用堆栈
# 调用堆栈 1: main -> ProcessRequests -> HandleRequest
CALLSTACK_1 = 1
add_callstack(packet.interned_data, CALLSTACK_1, [FRAME_MAIN, FRAME_PROCESS_REQUESTS, FRAME_HANDLE_REQUEST])
# 调用堆栈 2: main -> ProcessRequests -> HandleRequest -> malloc
CALLSTACK_2 = 2
add_callstack(
packet.interned_data,
CALLSTACK_2,
[FRAME_MAIN, FRAME_PROCESS_REQUESTS, FRAME_HANDLE_REQUEST, FRAME_MALLOC],
)
# 3. 创建引用驻留调用堆栈的事件
# 事件 1: 引用 CALLSTACK_1
emit_track_event(
ts=5000,
event_type=TrackEvent.TYPE_SLICE_BEGIN,
name="HandleRequest",
callstack_iid=CALLSTACK_1,
)
emit_track_event(
ts=5300,
event_type=TrackEvent.TYPE_SLICE_END,
name=None,
callstack_iid=None,
)
# 事件 2: 引用 CALLSTACK_2
emit_track_event(
ts=5100,
event_type=TrackEvent.TYPE_SLICE_BEGIN,
name="AllocateMemory",
callstack_iid=CALLSTACK_2,
)
emit_track_event(
ts=5200,
event_type=TrackEvent.TYPE_SLICE_END,
name=None,
callstack_iid=None,
)
# 事件 3: 另一个具有 CALLSTACK_1 的事件(重用驻留数据)
emit_track_event(
ts=6000,
event_type=TrackEvent.TYPE_SLICE_BEGIN,
name="HandleRequest",
callstack_iid=CALLSTACK_1,
)
emit_track_event(
ts=6400,
event_type=TrackEvent.TYPE_SLICE_END,
name=None,
callstack_iid=None,
)注意:
- 序列标志:定义驻留数据(首次)时使用
SEQ_INCREMENTAL_STATE_CLEARED | SEQ_NEEDS_INCREMENTAL_STATE;引用它或定义更多增量数据时仅使用SEQ_NEEDS_INCREMENTAL_STATE。 - 帧顺序:
frame_ids从最外到最内排序(与内联调用堆栈相同)。 - 重用:事件 3 重用
CALLSTACK_1,演示效率增益。
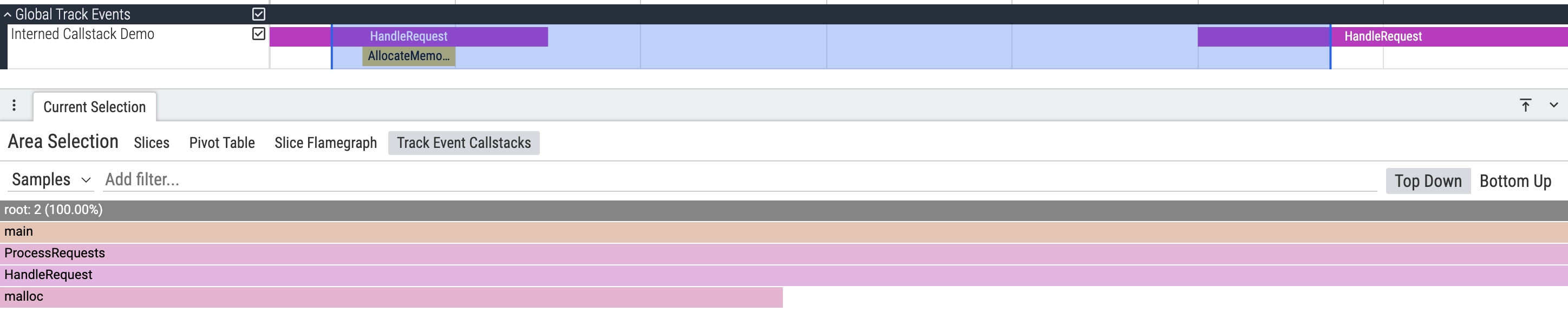
运行脚本后,在 Perfetto UI 中打开生成的 trace并进行区域选择将显示以下输出:
使用关联 ID 链接相关事件
关联 ID 提供了一种视觉上将属于同一逻辑操作的 Slice 链接起来的方法,即使它们没有因果连接。与代表直接因果关系的流程不同,关联 ID 对共享公共上下文或属于同一高级操作的事件进行分组。
常见用例:
- GPU 渲染: 链接在不同 GPU 阶段中涉及渲染同一帧的所有切片
- 分布式系统: 在通过不同服务移动时对与同一 RPC 请求相关的所有 Slice 进行分组
- 网络处理: 连接通过不同内核阶段处理同一网络请求的所有 Slice
视觉好处: Perfetto UI 可以使用关联 ID 为相关 Slice 分配一致的颜色,或者在悬停一个 Slice 时突出显示整个关联集,从而更容易追踪不同 Track 上的相关操作。
与流程的关系:
- 当事件有直接的因果关系时使用流程(A 触发 B)
- 当事件是同一逻辑操作的一部分但未直接连接时使用关联 ID
- 你可以同时使用两者:在关联组内的因果连接使用流程
Perfetto 支持三种类型的关联标识符:
correlation_id:一个 64 位无符号整数(最高效,推荐用于 大多数情况)correlation_id_str:一个字符串值(最灵活,人类可读)correlation_id_str_iid:一个驻留字符串 ID(参见 驻留数据以优化 trace 大小 有关驻留的详细信息)
Python 示例
此示例通过模拟跨越多个服务 Track 的两个单独请求的处理的不同阶段来演示使用整数标识符的关联 ID。
将以下 Python 代码复制到你的 trace_converter_template.py 脚本中的 populate_packets(builder) 函数中。
单击展开/折叠 Python 代码
TRUSTED_PACKET_SEQUENCE_ID = 9010
# --- 定义 Track UUID ---
frontend_track_uuid = uuid.uuid4().int & ((1 << 63) - 1)
auth_track_uuid = uuid.uuid4().int & ((1 << 63) - 1)
database_track_uuid = uuid.uuid4().int & ((1 << 63) - 1)
cache_track_uuid = uuid.uuid4().int & ((1 << 63) - 1)
# 定义 TrackDescriptor 的辅助函数
def define_custom_track(track_uuid, name):
packet = builder.add_packet()
desc = packet.track_descriptor
desc.uuid = track_uuid
desc.name = name
# 1. 定义 Track
define_custom_track(frontend_track_uuid, "前端服务")
define_custom_track(auth_track_uuid, "认证服务")
define_custom_track(database_track_uuid, "数据库服务")
define_custom_track(cache_track_uuid, "缓存服务")
# 添加带有关联 ID 的 Slice 的辅助函数
def add_correlated_slice(ts_start, ts_end, track_uuid, slice_name, correlation_id):
# 开始切片
packet = builder.add_packet()
packet.timestamp = ts_start
packet.track_event.type = TrackEvent.TYPE_SLICE_BEGIN
packet.track_event.track_uuid = track_uuid
packet.track_event.name = slice_name
packet.track_event.correlation_id = correlation_id
packet.trusted_packet_sequence_id = TRUSTED_PACKET_SEQUENCE_ID
# 结束切片
packet = builder.add_packet()
packet.timestamp = ts_end
packet.track_event.type = TrackEvent.TYPE_SLICE_END
packet.track_event.track_uuid = track_uuid
packet.trusted_packet_sequence_id = TRUSTED_PACKET_SEQUENCE_ID
# --- 请求 #42: 所有具有 correlation_id = 42 的 Slice ---
REQUEST_42_ID = 42
add_correlated_slice(1000, 1200, frontend_track_uuid, "处理请求 #42", REQUEST_42_ID)
add_correlated_slice(1100, 1400, auth_track_uuid, "认证请求 #42", REQUEST_42_ID)
add_correlated_slice(1350, 1600, database_track_uuid, "查询请求 #42", REQUEST_42_ID)
# --- 请求 #123: 所有具有 correlation_id = 123 的 Slice ---
REQUEST_123_ID = 123
add_correlated_slice(2000, 2300, frontend_track_uuid, "处理请求 #123", REQUEST_123_ID)
add_correlated_slice(2100, 2500, database_track_uuid, "查询请求 #123", REQUEST_123_ID)
add_correlated_slice(2400, 2600, cache_track_uuid, "缓存请求 #123", REQUEST_123_ID)
使用 Proto 扩展附加自定义类型字段
当 debug_annotations 不够表达力时 — 你想要具有嵌套消息、重复字段或下游工具可以依赖的类型的真实模式 — 使用 protobuf 扩展扩展 TrackEvent。Trace Processor 会自动将每个解码的扩展字段解析到 args 表中,前提是其描述符可用。
有关该机制的完整说明(字段编号分配、包装消息要求、描述符到达 Trace Processor 的三种方式),请参阅使用自定义 Proto 扩展 TrackEvent。本节重点介绍手动 trace 写入流程:如何使用标准 protobuf Python API 设置扩展字段并将描述符嵌入 trace 中,使结果自包含。
双文件设置
将模式拆分为两个 .proto 文件。
文件 1 — acme_data.proto 是你的常规数据模式。你将为此文件生成 Python 绑定并像任何其他 protobuf 消息一样使用它们。
syntax = "proto2";
package com.acme;
message AcmeRequestMetadata {
optional string request_id = 1;
repeated int32 retry_latencies_ms = 2;
optional string endpoint = 3;
}文件 2 — acme_extension.proto 是扩展 Hook:它将数据消息绑定到 TrackEvent 上的特定字段编号。你永远不要为此文件导入 Python 绑定 — 其唯一目的是生成嵌入在 trace 中的 FileDescriptorSet,以便 Trace Processor 知道如何解码该字段编号。
syntax = "proto2";
import "protos/perfetto/trace/perfetto_trace.proto";
import "acme_data.proto";
package com.acme;
message AcmeExtension {
extend perfetto.protos.TrackEvent {
optional AcmeRequestMetadata request_metadata = 9902;
}
}将 perfetto_trace.proto 的副本(从 GitHub 下载)放在 protos/perfetto/trace/ 下:
project/
├── protos/perfetto/trace/perfetto_trace.proto # 来自 Perfetto 仓库
├── acme_data.proto
└── acme_extension.proto从 project/ 编译:
# 仅数据模式的 Python 绑定。
protoc --python_out=. acme_data.proto
# 扩展 Hook 的自包含描述符集(拉入其导入)。
protoc -I. --include_imports \
--descriptor_set_out=acme_extension.desc \
acme_extension.protoPython 示例
扩展有效负载作为 protobuf 线字节写入 TrackEvent — 一个长度分隔的字段(线类型 2),其值是数据消息的序列化字节。
将以下代码复制到你的 trace_converter_template.py 脚本中的 populate_packets(builder) 函数中。
from acme_data_pb2 import AcmeRequestMetadata
# 在 acme_extension.proto 中声明的字段编号。
REQUEST_METADATA_FIELD_NUMBER = 9902
def _varint(n):
out = bytearray()
while n >= 0x80:
out.append((n & 0x7f) | 0x80)
n >>= 7
out.append(n)
return bytes(out)
def set_request_metadata(track_event, meta):
"""将消息类型的扩展字段(线类型 2)附加到 TrackEvent 上。"""
tag = (REQUEST_METADATA_FIELD_NUMBER << 3) | 2
payload = meta.SerializeToString()
wire = _varint(tag) + _varint(len(payload)) + payload
# MergeFromString 将编译模式之外的字段保留为
# 未知字段,这些字段在重新序列化时会被保留。
track_event.MergeFromString(wire)
TRUSTED_PACKET_SEQUENCE_ID = 1001
TRACK_UUID = 77777
# 1. 嵌入描述符集,以便 Trace Processor 可以解码扩展。
desc_packet = builder.add_packet()
with open('acme_extension.desc', 'rb') as f:
desc_packet.extension_descriptor.extension_set.ParseFromString(f.read())
# 2. 描述事件将出现的 Track。
td = builder.add_packet()
td.track_descriptor.uuid = TRACK_UUID
td.track_descriptor.name = "Requests"
# 3. 构建你的元数据。
meta = AcmeRequestMetadata()
meta.request_id = "req-42"
meta.retry_latencies_ms.extend([12, 34])
meta.endpoint = "/api/v1/search"
# 4. 发出带有作为扩展插入的元数据的 SLICE_BEGIN。
begin = builder.add_packet()
begin.timestamp = 1000
begin.trusted_packet_sequence_id = TRUSTED_PACKET_SEQUENCE_ID
begin.track_event.type = TrackEvent.TYPE_SLICE_BEGIN
begin.track_event.track_uuid = TRACK_UUID
begin.track_event.name = "HandleRequest"
set_request_metadata(begin.track_event, meta)
# 5. 关闭 Slice。
end = builder.add_packet()
end.timestamp = 1500
end.trusted_packet_sequence_id = TRUSTED_PACKET_SEQUENCE_ID
end.track_event.type = TrackEvent.TYPE_SLICE_END
end.track_event.track_uuid = TRACK_UUID导入生成的 trace 后,扩展字段可以使用 EXTRACT_ARG 查询。Trace Processor 按名称(request_metadata)键入扩展字段,并使用点表示法展平嵌套消息;重复字段使用 [N] 索引。
SELECT
slice.name,
EXTRACT_ARG(slice.arg_set_id, 'request_metadata.request_id') AS request_id,
EXTRACT_ARG(slice.arg_set_id, 'request_metadata.endpoint') AS endpoint,
EXTRACT_ARG(slice.arg_set_id, 'request_metadata.retry_latencies_ms[0]') AS first_retry_ms
FROM slice
WHERE EXTRACT_ARG(slice.arg_set_id, 'request_metadata.request_id') IS NOT NULL;控制 Track 合并
默认情况下,Perfetto UI 合并共享相同名称的 Track。这通常是用于分组相关异步事件的所需行为。但是,在某些情况下,你需要更明确的控制。你可以使用 TrackDescriptor 中的 sibling_merge_behavior 和 sibling_merge_key
字段覆盖此默认合并逻辑。
这允许你:
- 防止合并: 强制 Track(即使具有相同名称)始终单独显示。
- 按键合并: 强制 Track 根据自定义密钥合并,无论它们的名称如何。
Sibling_merge_behavior 字段可以设置为以下值之一:
SIBLING_MERGE_BEHAVIOR_BY_TRACK_NAME(默认):合并具有相同name的同级 Track。SIBLING_MERGE_BEHAVIOR_NONE:防止 Track 与其任何同级合并。SIBLING_MERGE_BEHAVIOR_BY_SIBLING_MERGE_KEY:合并具有相同sibling_merge_key字符串的同级 Track。
Python 示例:防止合并
在此示例中,我们创建两个具有相同名称的 Track。通过将其
Sibling_merge_behavior 设置为 SIBLING_MERGE_BEHAVIOR_NONE,我们确保它们
始终在 UI 中显示为不同的 Track。
单击展开/折叠 Python 代码
TRUSTED_PACKET_SEQUENCE_ID = 9003
# --- 定义 Track UUID ---
track1_uuid = 1
track2_uuid = 2
# 定义 TrackDescriptor 的辅助函数
def define_custom_track(track_uuid, name):
packet = builder.add_packet()
desc = packet.track_descriptor
desc.uuid = track_uuid
desc.name = name
desc.sibling_merge_behavior = TrackDescriptor.SIBLING_MERGE_BEHAVIOR_NONE
# 1. 定义 Track
define_custom_track(track1_uuid, "我的独立 Track")
define_custom_track(track2_uuid, "我的独立 Track")
# 添加 Slice 事件的辅助函数
def add_slice_event(ts, event_type, event_track_uuid, name=None):
packet = builder.add_packet()
packet.timestamp = ts
packet.track_event.type = event_type
packet.track_event.track_uuid = event_track_uuid
if name:
packet.track_event.name = name
packet.trusted_packet_sequence_id = TRUSTED_PACKET_SEQUENCE_ID
# 2. 向 Track 添加事件
add_slice_event(ts=1000, event_type=TrackEvent.TYPE_SLICE_BEGIN, event_track_uuid=track1_uuid, name="Slice 1")
add_slice_event(ts=1100, event_type=TrackEvent.TYPE_SLICE_END, event_track_uuid=track1_uuid)
add_slice_event(ts=1200, event_type=TrackEvent.TYPE_SLICE_BEGIN, event_track_uuid=track2_uuid, name="Slice 2")
add_slice_event(ts=1300, event_type=TrackEvent.TYPE_SLICE_END, event_track_uuid=track2_uuid)
Python 示例:按键合并
在此示例中,我们创建两个具有不同名称但相同
sibling_merge_key 的 Track。通过将其 Sibling_merge_behavior 设置为
SIBLING_MERGE_BEHAVIOR_BY_SIBLING_MERGE_KEY,我们指示 UI 将它们
合并到单个视觉 Track 中。合并组的名称将取自其中一个 Track(通常是具有较低 UUID 的 Track)。
单击展开/折叠 Python 代码
TRUSTED_PACKET_SEQUENCE_ID = 9004
# --- 定义 Track UUID ---
track1_uuid = 1
track2_uuid = 2
# 定义 TrackDescriptor 的辅助函数
def define_custom_track(track_uuid, name, merge_key):
packet = builder.add_packet()
desc = packet.track_descriptor
desc.uuid = track_uuid
desc.name = name
desc.sibling_merge_behavior = TrackDescriptor.SIBLING_MERGE_BEHAVIOR_BY_SIBLING_MERGE_KEY
desc.sibling_merge_key = merge_key
# 1. 定义具有相同合并密钥的 Track
define_custom_track(track1_uuid, "HTTP GET", "conn-123")
define_custom_track(track2_uuid, "HTTP POST", "conn-123")
# 添加 Slice 事件的辅助函数
def add_slice_event(ts, event_type, event_track_uuid, name=None):
packet = builder.add_packet()
packet.timestamp = ts
packet.track_event.type = event_type
packet.track_event.track_uuid = event_track_uuid
if name:
packet.track_event.name = name
packet.trusted_packet_sequence_id = TRUSTED_PACKET_SEQUENCE_ID
# 2. 向 Track 添加事件
add_slice_event(ts=1000, event_type=TrackEvent.TYPE_SLICE_BEGIN, event_track_uuid=track1_uuid, name="GET /data")
add_slice_event(ts=1100, event_type=TrackEvent.TYPE_SLICE_END, event_track_uuid=track1_uuid)
add_slice_event(ts=1200, event_type=TrackEvent.TYPE_SLICE_BEGIN, event_track_uuid=track2_uuid, name="POST /submit")
add_slice_event(ts=1300, event_type=TrackEvent.TYPE_SLICE_END, event_track_uuid=track2_uuid)
使用流处理大型 trace
到目前为止,所有示例都使用了 TraceProtoBuilder,它在将 trace 写入文件之前在内存中构建整个 trace。这对于中等大小的 trace简单有效,但如果你生成具有数百万事件的 trace,则可能会导致高内存消耗。
对于这些情况,StreamingTraceProtoBuilder 是推荐的解决方案。它在创建每个 TracePacket 时将其写入文件,无论 trace 大小如何,都保持内存使用最小化。
它如何工作
流式构建器的 API 略有不同:
- 初始化: 你使用以二进制写入模式打开的类文件对象初始化
StreamingTraceProtoBuilder。 - 数据包创建: 调用
builder.create_packet()而不是builder.add_packet()来获取新的空TracePacket。 - 数据包写入: 填充数据包后,必须显式调用
builder.write_packet(packet)以将其序列化并写入文件。
Python 示例:完整的流式脚本
这是一个完整的、独立的 Python 脚本,演示如何使用
StreamingTraceProtoBuilder。它基于
[入门指南](/docs/getting-started/converting.md)中的"创建基本 Timeline
Slice"示例。
你可以将此代码保存为新文件(例如,streaming_converter.py)并运行它。
单击展开/折叠 Python 代码
#!/usr/bin/env python3
import uuid
from perfetto.trace_builder.proto_builder import StreamingTraceProtoBuilder
from perfetto.protos.perfetto.trace.perfetto_trace_pb2 import TrackEvent
def populate_packets(builder: StreamingTraceProtoBuilder):
"""
此函数定义并将 TracePackets 写入流中。
参数:
builder: StreamingTraceProtoBuilder 的实例。
"""
# 为此数据包序列定义唯一 ID
TRUSTED_PACKET_SEQUENCE_ID = 1001
# 为你的自定义 Track 定义唯一 UUID
CUSTOM_TRACK_UUID = 12345678
# 1. 定义自定义 Track
packet = builder.create_packet()
packet.track_descriptor.uuid = CUSTOM_TRACK_UUID
packet.track_descriptor.name = "我的自定义数据 Timeline"
builder.write_packet(packet)
# 2. 为此自定义 Track 发出事件
# 示例事件 1:"任务 A"
packet = builder.create_packet()
packet.timestamp = 1000
packet.track_event.type = TrackEvent.TYPE_SLICE_BEGIN
packet.track_event.track_uuid = CUSTOM_TRACK_UUID
packet.track_event.name = "任务 A"
packet.trusted_packet_sequence_id = TRUSTED_PACKET_SEQUENCE_ID
builder.write_packet(packet)
packet = builder.create_packet()
packet.timestamp = 1500
packet.track_event.type = TrackEvent.TYPE_SLICE_END
packet.track_event.track_uuid = CUSTOM_TRACK_UUID
packet.trusted_packet_sequence_id = TRUSTED_PACKET_SEQUENCE_ID
builder.write_packet(packet)
# 示例事件 2:"任务 B"
packet = builder.create_packet()
packet.timestamp = 1600
packet.track_event.type = TrackEvent.TYPE_SLICE_BEGIN
packet.track_event.track_uuid = CUSTOM_TRACK_UUID
packet.track_event.name = "任务 B"
packet.trusted_packet_sequence_id = TRUSTED_PACKET_SEQUENCE_ID
builder.write_packet(packet)
packet = builder.create_packet()
packet.timestamp = 1800
packet.track_event.type = TrackEvent.TYPE_SLICE_END
packet.track_event.track_uuid = CUSTOM_TRACK_UUID
packet.trusted_packet_sequence_id = TRUSTED_PACKET_SEQUENCE_ID
builder.write_packet(packet)
# 示例事件 3:一个瞬时事件
packet = builder.create_packet()
packet.timestamp = 1900
packet.track_event.type = TrackEvent.TYPE_INSTANT
packet.track_event.track_uuid = CUSTOM_TRACK_UUID
packet.track_event.name = "里程碑 Y"
packet.trusted_packet_sequence_id = TRUSTED_PACKET_SEQUENCE_ID
builder.write_packet(packet)
def main():
"""
初始化 StreamingTraceProtoBuilder 并调用 populate_packets
将 trace 写入文件。
"""
output_filename = "my_streamed_trace.pftrace"
with open(output_filename, 'wb') as f:
builder = StreamingTraceProtoBuilder(f)
populate_packets(builder)
print(f"trace 已写入 {output_filename}")
print(f"使用 [https://ui.perfetto.dev](https://ui.perfetto.dev) 打开。")
if __name__ == "__main__":
main()